阅读理解系列的框架很多大同小异,但这篇 paper 真心觉得精彩,虽然并不是最新最 state-of-art~
现在大多数的阅读理解系统都是 top-down 的形式构建的,也就是说一开始就提出了一个很复杂的结构(一般经典的就是 emedding-, encoding-, interaction-, answer-layer),然后通过 ablation study,不断的减少一些模块配置来验证想法,大多数的创新点都在 interaction 层。而这篇 paper 提供了抽取式 QA 基于神经网络的两个 baseline,BoW- 和 RNN-based nerual QA (FastQA) ,创新的以 bottom-up 的方式分析了框架复杂性以及主流 interaction layer 的作用。
一个基本认识,构建好的 QA 系统必不可少的两个要素是:
- 在处理 context 时对 question words 的意识
- 有一个超越简单的 bag-of-words modeling 的函数,像是 RNN
另外,作者还发现了很多看似复杂的问题其实通过简单的 context/type matching heruistic 就可以解出来了,过程是选择满足条件的 answer spans:
- 与 question 对应的 answer type 匹配
比如说问 when 就回答 time - 与重要的 question words 位置上临近
如下图的 St. Kazimierz Church

FastQA 的表现对额外的复杂度,尤其是 interaction 的复杂交互,提出了质疑。
A BoW Neural QA System
比照传统思路来构建。
- Embedding
词向量和字向量的拼接,字向量用 CNN 进行训练,$x=[x^w; x^c] \in R^d$ - Type matching
抽取 question words 得到 lexical answer type(LAT)。抽哪些?- who, when, why, how, how many, etc.
- what, which 后面的第一个名词短语,如 what year did…
将 LAT 的第一个和最后一个单词的 embedding,以及 LAT 所有单词的平均的 embedding 拼接起来,再通过全连接层和 tanh 做一个非线性变换得到 $\hat z$。
用同样方法对每个 potential answer span(s, e) 做编码。所有 span,最长为 10 个单词,同样把 span 里第一个和最后一个单词的 embedding 和所有单词的 embedding 进行拼接,又因为 potential answer span 周围的单词会对 answer span type 提供线索(比如上文提到的 St. Kazimierz Church),所以额外的拼接了 span 往左、往右 5 个单词的平均 embedding,这样一共就是 5 个 embedding,接 FC 层和 tanh 非线性变换,得到 $\hat x_{s,e}$
最后,拼接 LAT 和 span 的表示,$[\hat z; \hat x_{s, e}; \hat z \ ☉ \ \hat x_{s,e}]$,用一个前馈网络计算每个 span(s,e) 和 LAT 的分数 $g_{type}(s,e)$
- Context Matching
引入两个 word-in-question 特征,对 context 中的每个单词 $x_j$- binary
$wiq^b$ ,如果 $x_j$ 出现在了 question 中,就为 1,否则为 0 - weighted
计算 $q_i$ 和 $x_j$ 的词向量相似性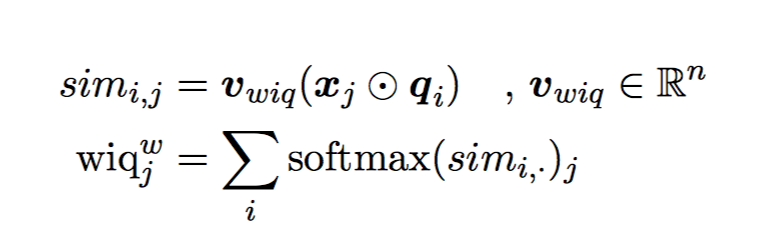 Softmax 保证了 infrequent occurrences of words are weighted more heavily.
Softmax 保证了 infrequent occurrences of words are weighted more heavily.
对每个 answer span(s,e),计算往左、往右 5/10/20 token-windows 内 $wiq^b$ 和 $wiq^w$ 的平均分数,也就是计算 2(kind of features) 3(windows) 2(left/right)=12个分数的加权和得到 context-matching score $g_{ctxt}(s,e)$,各分数的权重由训练得到
- binary
- Answer span scoring
最后每个 span(s,e) 的分数就是 type matching score 和 context matching score 的和
$$g(s,e)=g_{type}(s,e)+g_{ctxt}(s,e)$$
最小化 softmax-cross-entropy loss 进行训练。
FastQA
上面的方法中语义特征完全被缩减成了 answer-type 和 word-in-question features,另外 answer span 也受到了长度限制,对语义的捕捉很弱。
BiRNN 在识别 NER 上面非常有优势,context matching 也可以通过给 BiRNN 喂 wiq-features 得到,answer-type 会间接由网络学习得到。
模型相对简单,就三层 embedding-, encoding-, answer layer。

- Embedding
和 BoW baseline 相同。 - Encoding
为了让 question 和 context embedding 可以交互,先映射到 n 维向量,再过一个 highway layer。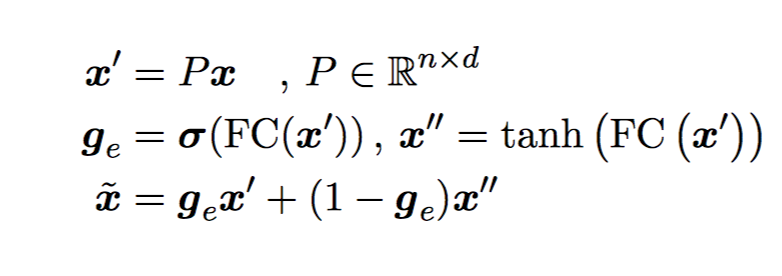 然后加上 wiq features
然后加上 wiq features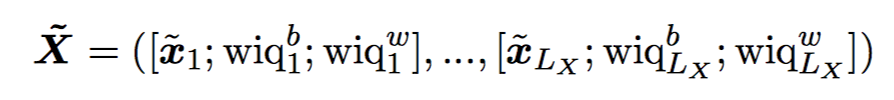 再一起过一个 BiRNN,输出再做个 projection
再一起过一个 BiRNN,输出再做个 projection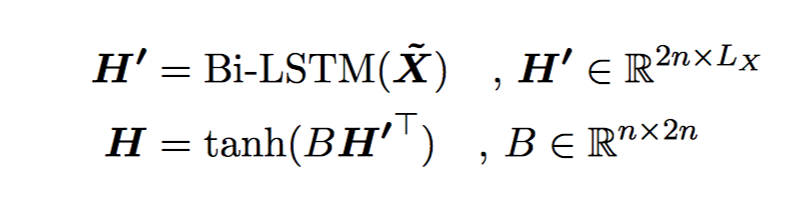 初始化 project matrix B 为 $[I_n; I_n]$,$I_n$ 是 n 维的 identity matrix,H 是 forawrd 和 backward LSTM 的输出的加和。
初始化 project matrix B 为 $[I_n; I_n]$,$I_n$ 是 n 维的 identity matrix,H 是 forawrd 和 backward LSTM 的输出的加和。
question 和 context 的参数共享,question 对应的两个 wiq 特征设为 1。projection matrix B 不共享。 - Answer layer
context x $H=[h_1,…,h_{L_X}]$
question Q $Z=[Z_1,…Z_{L_Q}]$
对 Z 做一个变换,同样是 context-independent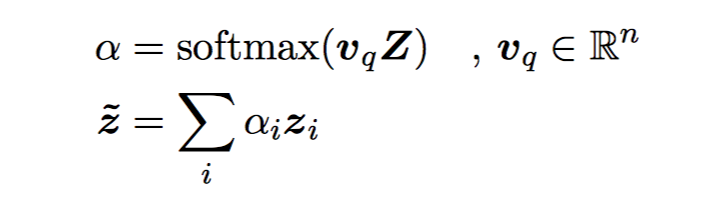 answer 的开始位置的概率 $p_s$ 由 2 个前馈网络加一个 ReLU 激活得到。
answer 的开始位置的概率 $p_s$ 由 2 个前馈网络加一个 ReLU 激活得到。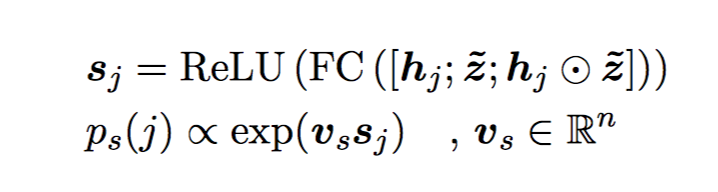 结束位置:
结束位置: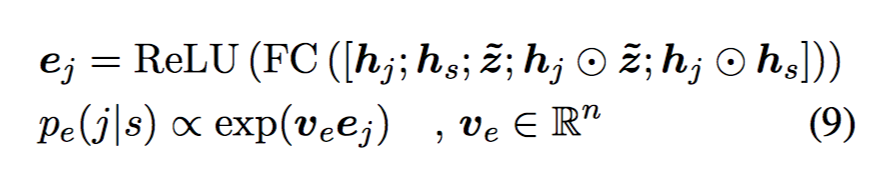 $$p(s,e)=p_s(s)•p_e(e|s)$$
$$p(s,e)=p_s(s)•p_e(e|s)$$
最小化 p(s,e) 的交叉熵来训练。
在预测的时候,可以用 beam-search。
FastQA Extended
相当于主流模型的 interaction layer。对当前的 context state,考虑和剩下的 context(intra)或者和 question(inter)做注意力计算,将其余 context/question 的信息融入当前 context。
- Intra-fustion
between passages of the context - Inter-fusion
between question and context
实验结果: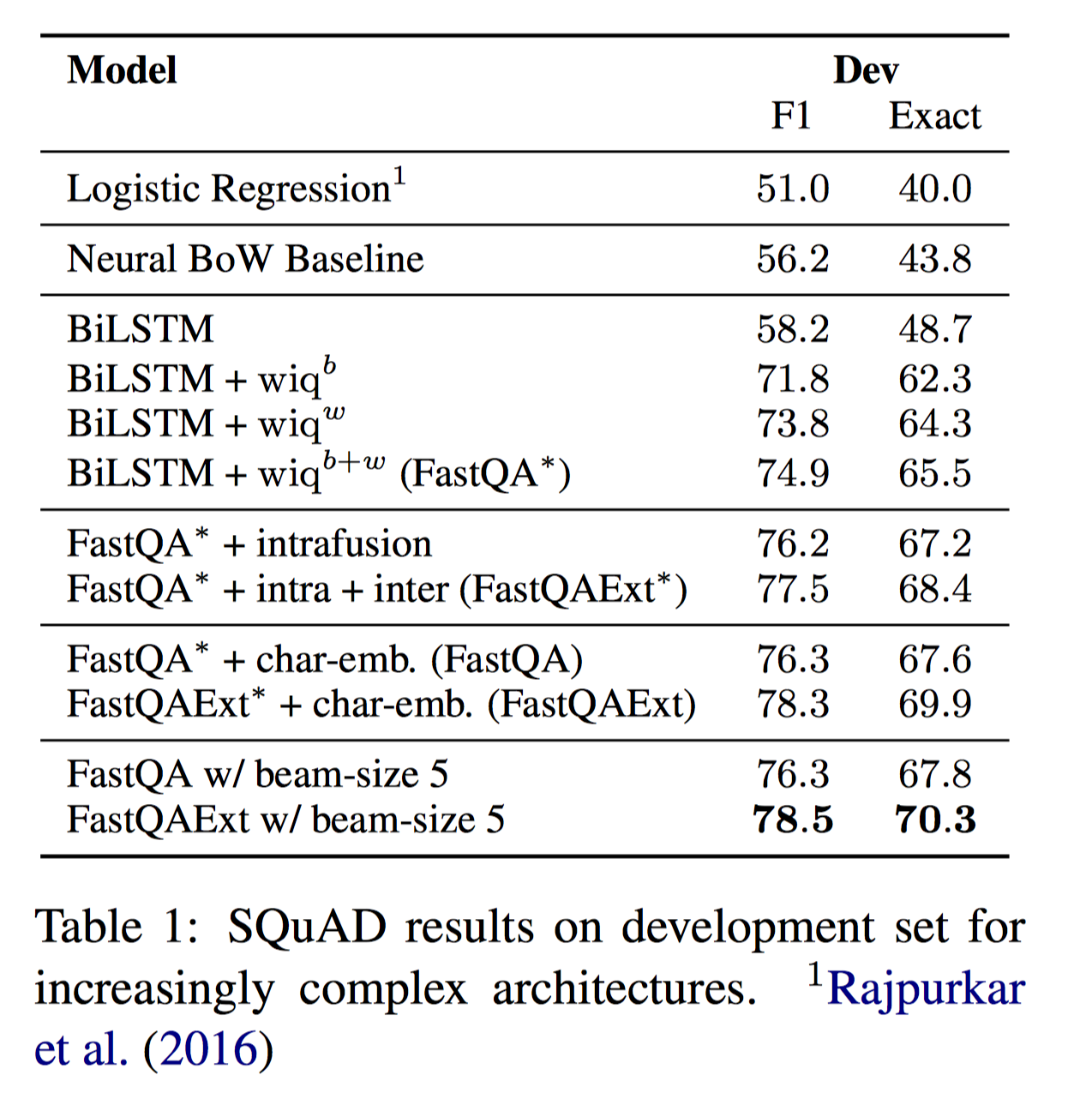
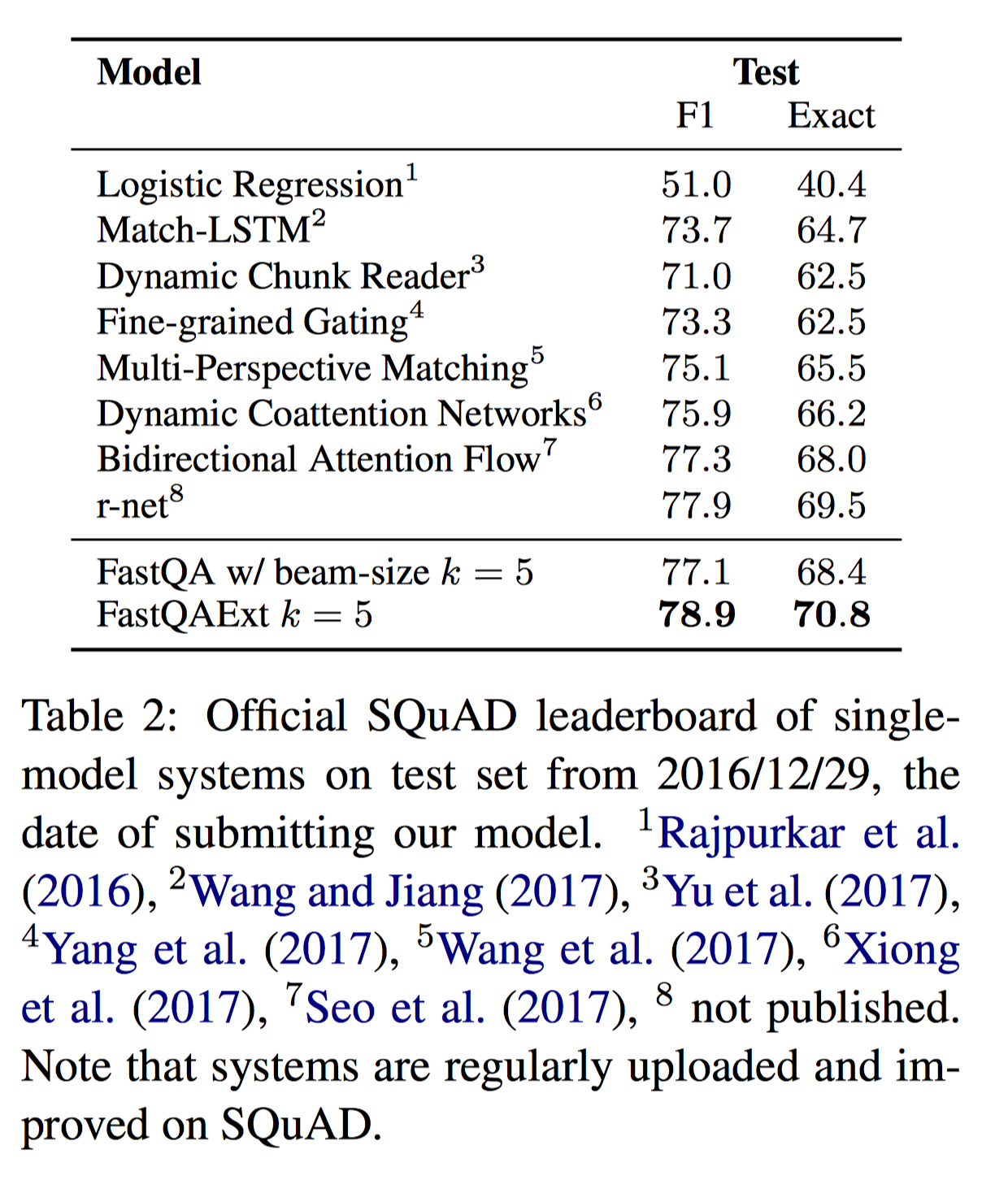
一些小结论:
- 简单的 $wiq^b$ 特征能大幅度提升 performance,原因是让 encoder 有了真实 question 的部分知识后,encoder 就可以有选择性的追踪问题相关的信息并进一步将具体的实体抽象为对应的类型,如果在问题中提到了人名,那么 context encoder 就会记住 “question-person” 而不是具体名字。
- Beam-search 可以微弱提升结果,因为最可能的开始位置不一定是最好的 answer span
- 额外的 character embedding 对结果有显著提升
- 进一步的 fusion 对结果也有帮助,但并没有那么显著
讨论 Do we need additional interaction?
对比试验,FastQA 与 FastQAExt 和 DCN 相比,快两倍,而且少 2-4 倍的显存。分析了结果发现 FastQAExt 泛化能力更强些,但并没有 systematic advantage,并不会对某类问题(主要分析了推理)有一致性的提升。
Qualitative Analysis
对 FastQA 的错误结果进行了一些分析,大部分的错误来自:
- 缺乏对句法结构的理解
- 不同词位相似语义的词的细粒度语义之间的区分
其他很多的错误也是来自人工标注偏好。
举了一些典型的错误例子,像 例1 是缺乏对某些答案类型的细化理解。例2 缺乏指代消解和上下文缩略语的认识,例3 模型有时难以捕捉基本的句法结构,尤其是对于重要的分隔符如标点符号和连词被忽略的嵌套句子

现有 top-down 模型用到实际业务当中通常需要为了 fit 进显存或者是满足一定的响应时间而进行模型的各种简化,FastQA 在显存占用和响应速度上有着绝对优势,感觉还是非常有意义的~

