CMU & Google 出品的 Fast and Accurate Reading Comprehension by Combining Self-Attention and Convolution,SQuAD 榜单上对应模型 QANet,这名字是不是太随意了TAT…
Fast and Accurate Reading Comprehension by Combining Self-Attention and Convolution
CMU 和 Google Brain 新出的文章,SQuAD 目前的并列第一,两大特点:
- 模型方面创新的用 CNN+attention 来完成阅读理解任务
在编码层放弃了 RNN,只采用 CNN 和 self-attention。CNN 捕捉文本的局部结构信息( local interactions),self-attention 捕捉全局关系( global interactions),在没有牺牲准确率的情况下,加速了训练(训练速度提升了 3x-13x,预测速度提升 4x-9x) - 数据增强方面通过神经翻译模型(把英语翻译成外语(德语/法语)再翻译回英语)的方式来扩充训练语料,增加文本多样性
其实目前多数 NLP 的任务都可以用 word vector + RNN + attention 的结构来取得不错的效果,虽然我挺偏好 CNN 并坚定相信 CNN 在 NLP 中的作用(捕捉局部相关性&方便并行),但多数情况下也是跟着主流走并没有完全舍弃过 RNN,这篇论文还是给了我们很多想象空间的。
Model Architecture
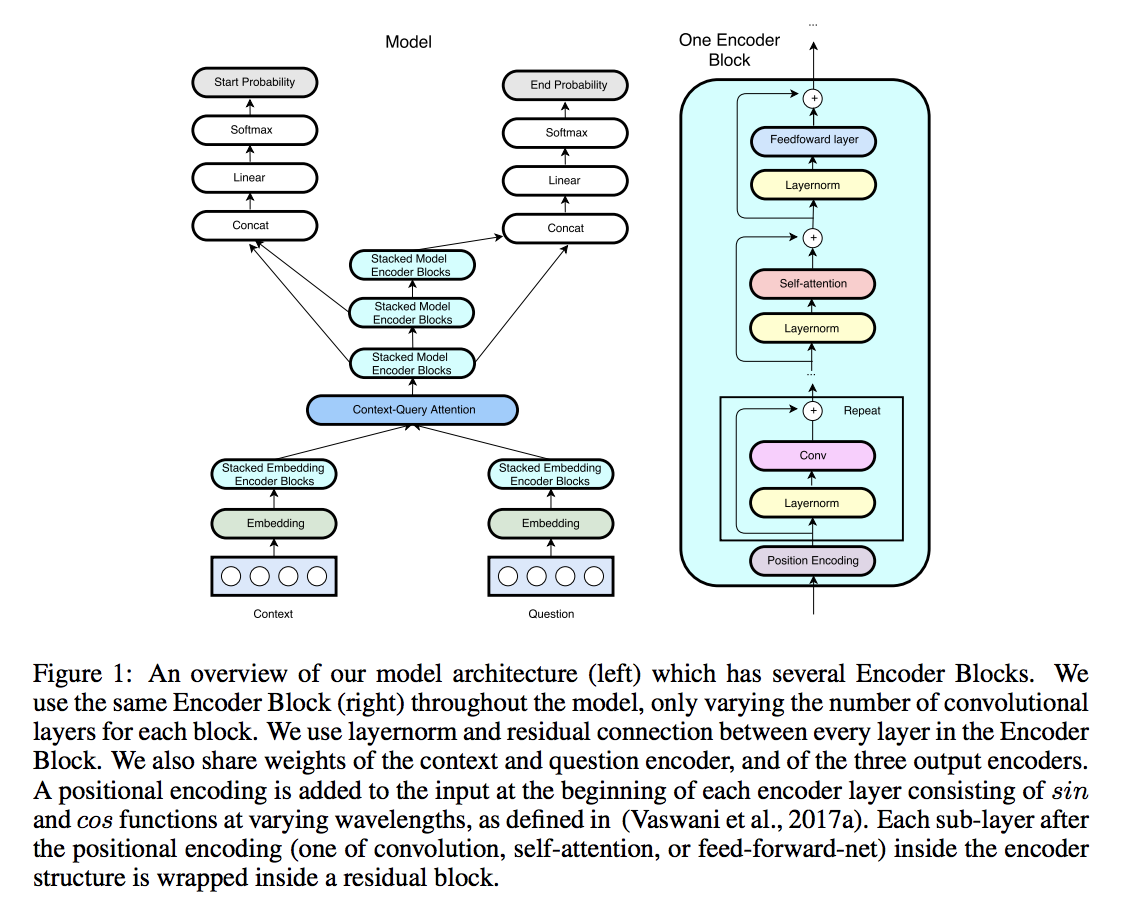
先看模型,在 BiDAF 基础上的一些改进,主要在 embedding encoder 层。还是阅读理解经典五层结构:
- Input embedding layer
和其他模型差不多,word embedding + character embedding,预训练词向量,OOV 和字向量可训练,字向量用 CNN 训练
单词 w 的表示由词向量和字向量的拼接 $[x_w; x_c] \in R^{p_1+p_2}$然后经过两层 highway network 得到,这个和 BiDAF 相同 - Embedding encoder layer
重点是这一层上的改变,由几个基本 block 堆叠而成,每个 block 的结构是:
[convolution-layer x # + self-attention-layer + feed-forward-layer]
卷积用的 separable convolutions 而不是传统的 convolution,因为更加 memory efficient,泛化能力也更强。核心思想是将一个完整的卷积运算分解为 Depthwise Convolution 和 Pointwise Convolution 两步进行,两幅图简单过一下概念
先做 depthwise conv, 卷积在二维平面进行,filter 数量等于上一次的 depth/channel,相当于对输入的每个 channel 独立进行卷积运算,然后就结束了,这里没有 ReLU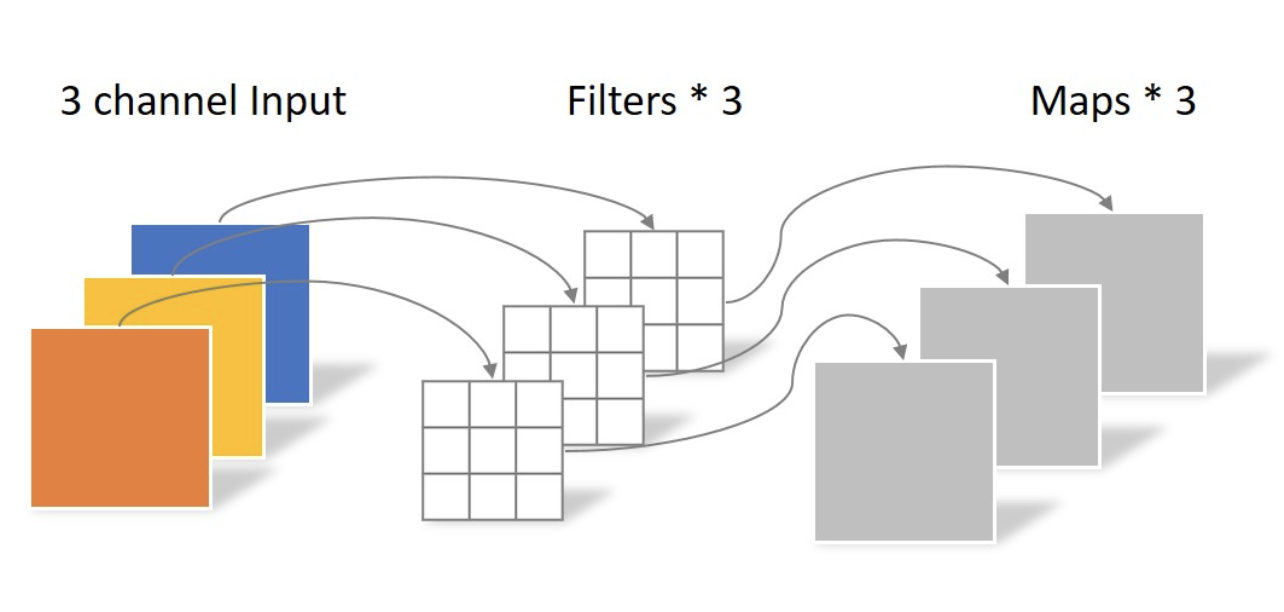 然后做 pointwsie conv,和常规卷积相似,卷积核尺寸是 1x1xM,M 为上一层的 depth,相当于将上一步depthwise conv 得到的 map 在深度上进行加权组合,生成新的 feature map
然后做 pointwsie conv,和常规卷积相似,卷积核尺寸是 1x1xM,M 为上一层的 depth,相当于将上一步depthwise conv 得到的 map 在深度上进行加权组合,生成新的 feature map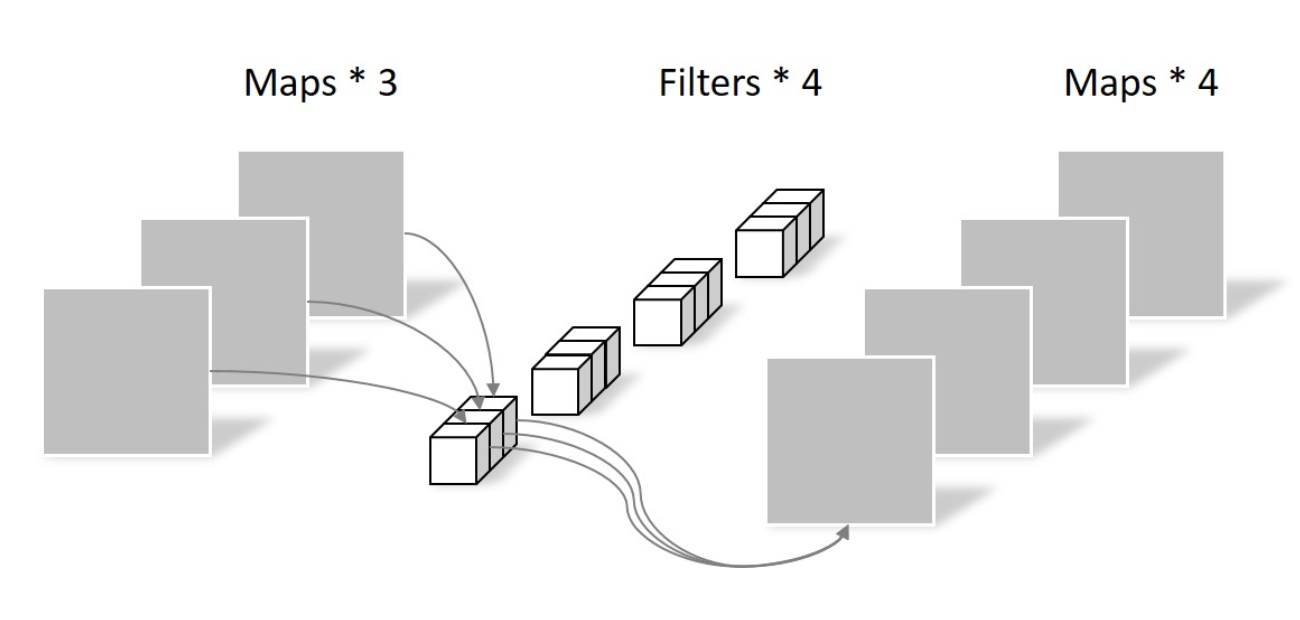 Self-attention-layer 用的是多头注意力机制(head=8),常用的也不多说了。
Self-attention-layer 用的是多头注意力机制(head=8),常用的也不多说了。
注意的是这里每个基本运算(conv/self-attention/ffn)之间是 残差连接,对输入 x 和操作 f,输出是 f (layernorm(x))+x,也就是说某一层的输出能够直接跨越几层作为后面某一层的输入,有效避免了信息损失
4 个卷积层,1 个 encoding block - Context-query attention layer
几乎所有 machine reading comprehension 模型都会有,而这里依旧用了 context-to-query 以及 query-to-context 两个方向的 attention,先计算相关性矩阵,再归一化计算 attention 分数,最后与原始矩阵相乘得到修正的向量矩阵。相似度函数这里用的
$$f(q,c)=W_0[q,c,q⊙c]$$
对行、列分别做归一化得到 S’ 和 S’’,最后 context-to-query attention 就是 $A=S’Q^T$,query-to-context attention 就是 $B=S’S’’^TC^T$,用了 DCN attention 的策略 - Model encoder layer
和 BiDAF 差不多,不过这里依旧用 CNN 而不是 RNN。这一层的每个位置的输入是 [c, a, c⊙a, c⊙b],a, b 是 attention 矩阵 A,B 的行,参数和 embedding encoder layer 相同,除了 cnn 层数不一样,这里是每个 block 2 层卷积,一共 7 个 block - Output layer
再次和 BiDAF 相同
$p1=softmax(W_1[M_0; M_1]), p2=softmax(W_2[M_0; M_2])$
目标函数:
$$L(\theta)=-{1 \over N} \sum^N_i[log(p^1_{y_i^1})+log(p^2_{y_i^2})]$$
其中 $y^1_i$ 和 $y^2_i$ 分别是第 i 个样本的 groundtruth 的开始和结束位置
Data Augmentation
CNN 速度快所以有条件用更多的数据来训练啦,然后进一步增强模型的泛化能力啦。这里数据增强的基本 idea 就是通过 NMT 把数据从英文翻译成法文(English-to-French),另一个翻译模型再把法文翻回英文(French-to-English)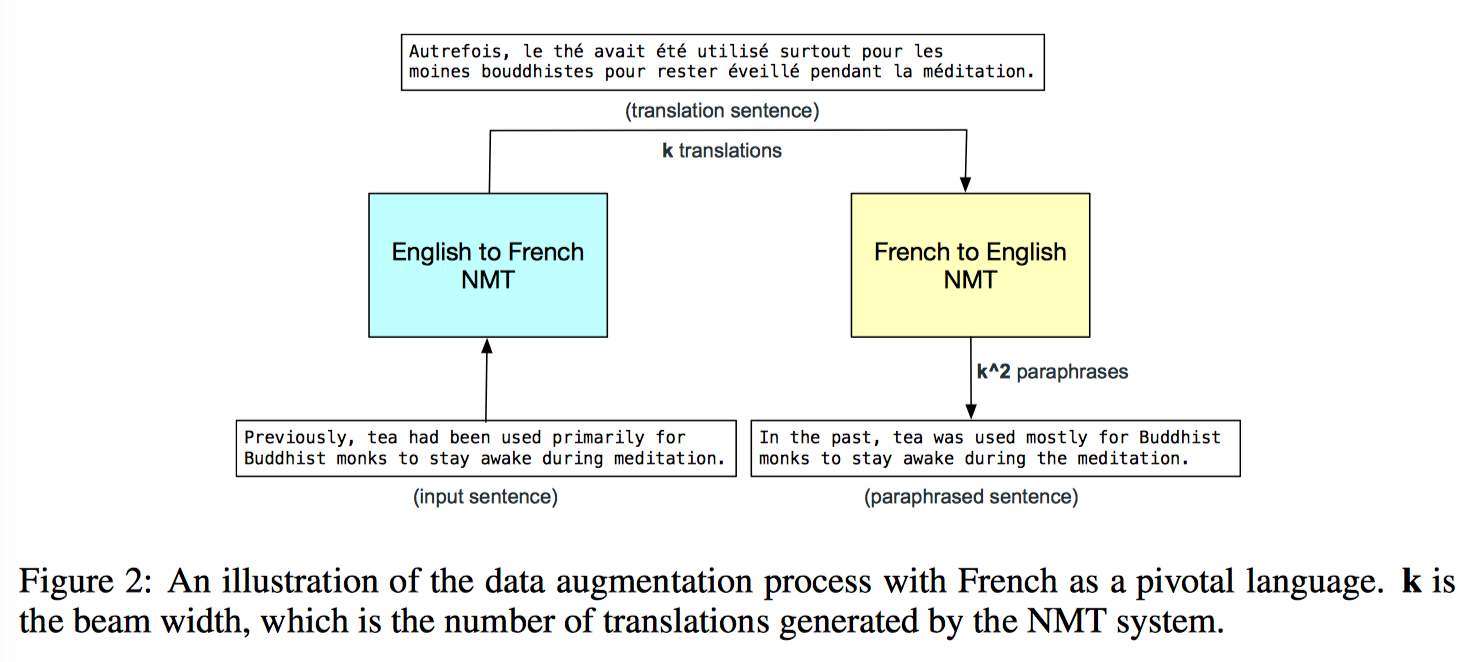
看图说话,对段落中每个句子先用 English-to-French 模型的 beam decoder 得到 k 个法语翻译,然后对每一条翻译,都再经过一个 reversed translation model 的 beam decoder,这最后就得到了 k^2 个改写的句子(paraphrases),然后从这 k^2 个句子中随机选一个
具体到 SQuAD 任务就是 (d,q,a) -> (d’, q, a’),问题不变,对文档 d 翻译改写,由于改写后原始答案 a 现在可能已经不在改写后的段落 d’ 里了,所以需要从改写后的段落 d’ 里抽取新的答案 a’,采用的方法是计算 s’ 里每个单词和原始答案里 start/end words 之间的 character-level 2-gram score,分数最高的单词就被选择为新答案 a’ 的 start/end word
这个方法还可以从 quality 和 diversity 改进,quality 方面用更好的翻译模型,diversity 方面可以考虑引入问题的改写,也可以使用其他的数据增广的方法(Raiman&Miller, 2017)
实验结论是英文语料:法语语料:德语语料是 3:1:1 的比例时效果最好,EM 提升了 1.5,F1 提升了 1.1

