介绍一种 cache-like memory network。
涉及论文:
- Learning to Remember Translation History with a Continuous Cache
相关博客:
比较传统的 NMT 把文档当做一系列独立的句子来进行翻译,忽略了句子之间的关系,或者说是忽略了篇章信息,这样会带来两个问题:
- 一致性问题(inconsistency)
如时态一致性问题,以及术语选择的一致性问题,这些通常都需要联系上下文/篇章信息 - 歧义问题(ambiguity)
NMT 基本的翻译单位是词向量,也是通过 word-by-word 的方式产生翻译的。向量表示的泛化问题会导致歧义进一步放大,如机遇/挑战,教师/培训这些词在空间里比较靠近,很容易导致翻译错误

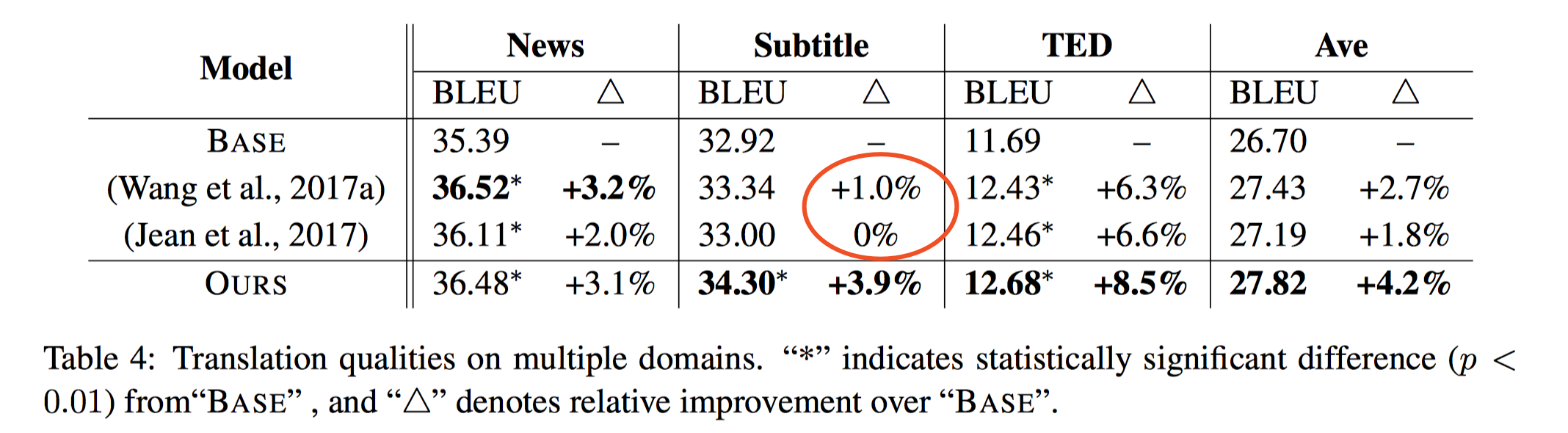
在 SMT 中,引入 cross-sentence 的作用对解决上面两个问题非常有效,因此 NMT 方面也有人做了一些尝试,比如说用分层 RNN 来总结前 K 个 source sentences 的语境信息(Wang et al. 2017a),或者用额外的 encoder 和 attention model 来动态选择聚焦前一个 source sentence 的某个部分 (Jean et al. 2017),这些方法有一定效果,但是都只考虑了单语的信息,没有用到目标端的信息,并且仍然是从 discrete lexicon 中产生 context,词级别的错误会继续传递下去,这在口语字幕的语料上表现的更为明显(不能得到多大改善)。另外,这两个模型计算量也很大,不利于 scale。
这篇论文用到了 cache-like memory networks 的思想,用一个额外的 cache model 把源端表示作为 KEY,目标端表示作为 VALUE,从 memory 里定位相关的信息,然后把相关信息也作为输入,翻译时能得到更多方面比如说时态的信息。这样的好处 一是可以规模化,通过 cache 获得更长的历史信息,二是因为用的是 internal representation (并且是 attention 后的片段信息)而不是单词,能缓解错误传播的问题,也考虑进了目标端的信息。
与 Standard NMT 的对比如下:
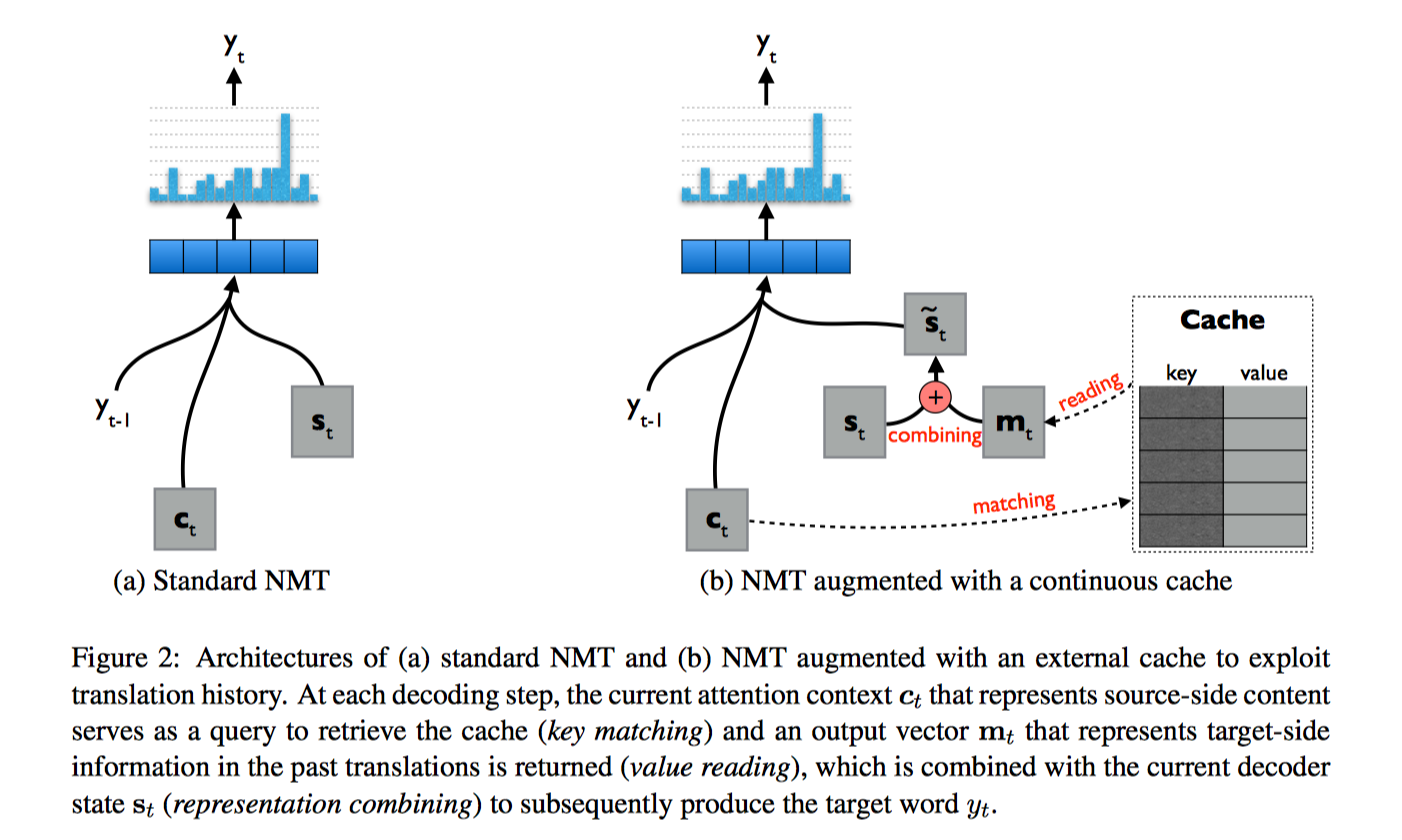
主要还是读取/写入 cache 的过程。
Reading from Cache
Key Matching
cache lookup 最简单用点积来做,也可以加中间转换矩阵或者用 attention 方法,不过点积最简单高效,不用学新的参数也能学到相似度
$$P_m(c_i|c_t)={exp(c^T_tc_i)\over \sum^I_{i’=1}exp(c^T_tc_i’)}$$
$c_t$ 是 t step 的 attention context,$c_i$ 是 cache 里第 i 个位置的 representation,I 是 cache slots 的总量
Value Reading
得到概率分布后对每个 value 进行加权
$$m_t=\sum_{(c_i, s_i) \in cache} P_m(c_i|c_t)s_i$$
$P_m(c_i|c_t)$ 可以解释为给定 source side context $c_t$,从 cache 里检索得到相似的 target-side info $m_t$,答案是和过去产生的相似的 target words 相关的语境
Representation Combining
用原始的 decoder state $s_t$ 和当前的 output vector $m_t$ 进行线性组合,相当于 GRU 里的 update gate
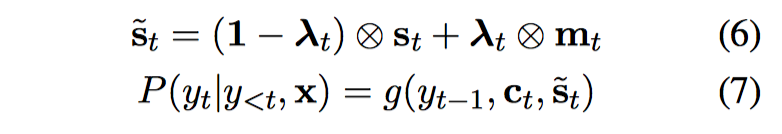
其中 lambda 是一个动态调节的 weight vector,在每个 decoding step 都要重新计算
$$\lambda_t = \sigma (Us_t + Vc_t+Wm_t)$$
U(dxd), V(dxl), W(dxd) 是参数矩阵
Writing to Cache
在整个句子翻译完后,再写入 cache,写入 cache 的内容包括
- generated translation sentence
{$y_1,…,y_t…,y_T$} - attention vector sequence
{$c_1,…,c_t,…c_T$} - decoder state sequence
{$s_1,…,s_t,…,s_T$}
如果 $y_t$ 在 cache 里不存在,那么会选择一个空的 slot 或者覆盖一个 LRU(least recently used) slot,key 是 $c_t$,value 是 $s_t$,indicator 是 $y_t$
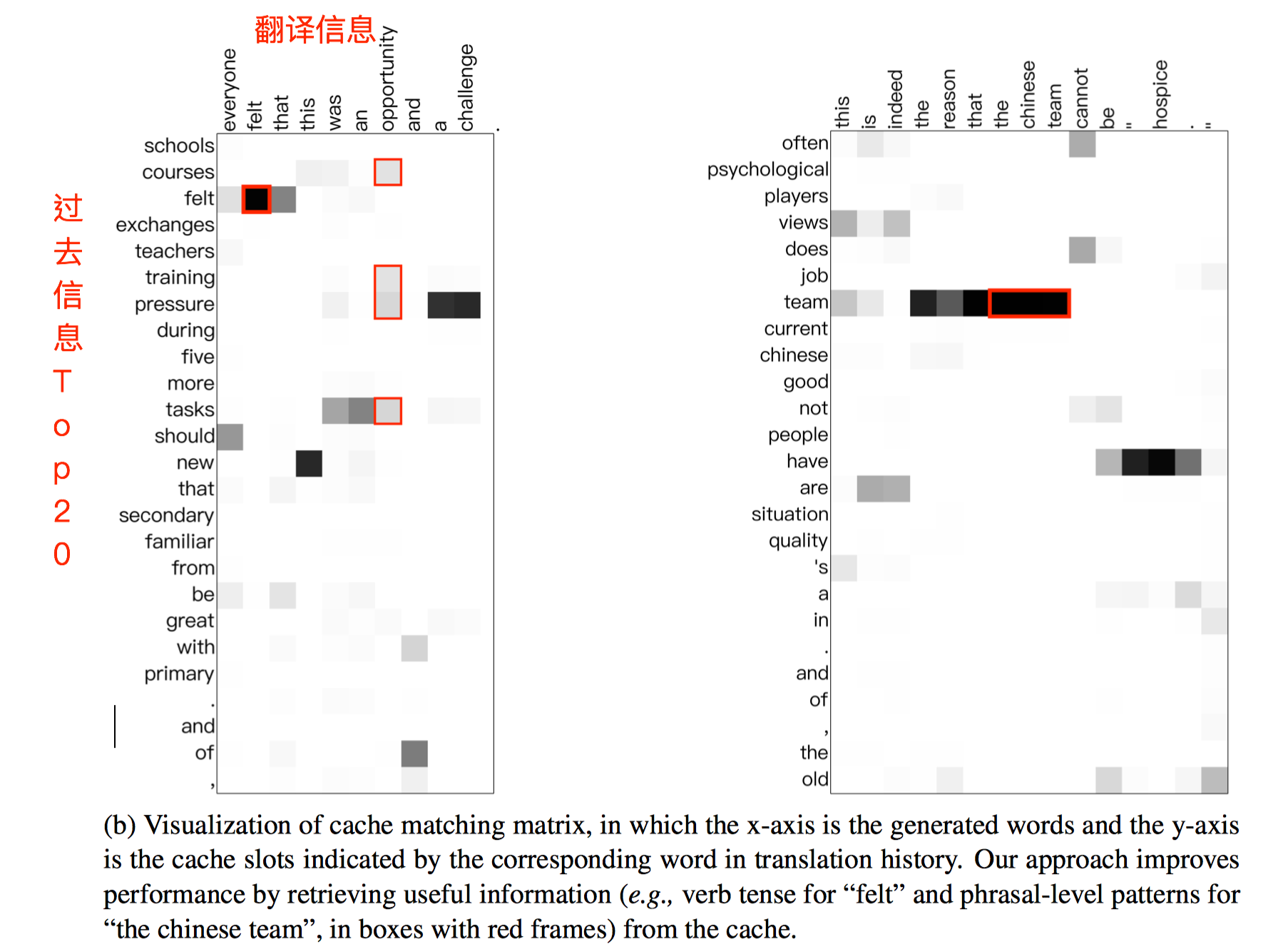
如果 $y_t$ 已经存在,那么更新 key, value,$k_i=(k_i+c_t)/2, \ v_i=(v_i+s_t)/2$,像是一个 exponential decay,每一次更新之前的 key, value 都会减半,基本逻辑是最近的历史会有更高的重要性。通过可视化图可以看一下效果:
小结
理解下来还是非常简单的。亮点还是 cache 的设计,一方面用到了历史信息,另一方面用到了源端和目标端的信息,并且是单词粒度之上的信息(attention context vector)。

