Andrew Ng. Deep Learning Course 3 Structuring Machine Learning Projects 的重点笔记。
常用策略及考虑问题
常用的 ML 策略:
- 收集更多数据(collect more data)
- 收集更多样化的训练集(collect more diverse training set)
- 梯度下降训练更长时间(train algorithm longer with gradient descent)
- 尝试 Adam 算法(try Adam instead of gradient descent)
- 尝试更大的网路(try bigger network)
- 尝试小一点的网络(try smaller network)
- 尝试 dropout(try dropout)
- 加 L2 正则(add L2 regularization)
- 改善网络结构(network architecture)
- 激活函数(activation functions)
- 隐藏单元数量(number of hidden units)
- …
要考虑的几个问题:
- 训练集上拟合良好 fit training set well on cost function
- 训练开发集上拟合良好 fit training-dev set well on cost function
在训练集和开发/测试集来自不同分布时考虑 - 开发集上拟合良好 fit dev set well on cost function
- 测试集上拟合良好 fit test set well on cost function
- 现实世界中表现良好 performs well in real world
另外,调优要注意的是,尽量用 正交化(Orthogonalization) 的手段,比如说 early stopping 其实不是一个优先的选择,因为它不那么正交化,会同时影响模型对训练集的拟合以及开发集的表现,同时影响了两件事情,对误差分析造成干扰。
评价指标
单实数评价指标(Using a single number evaluation metric)
用单实数评价指标,能够提高比较各种模型的效率,便于优化模型。 一个简单的例子是用 precision 和 recall,我们知道二者不可兼得,也就是比较哪个模型好的时候我们会发现 A 的 precision 高,B 的 recall 高,选哪个呢?这时候不妨引入 F1 来综合 precision 和 recall。
满足和优化指标
如果有多个评价指标,可以选择线性组合,如 cost = accuracy - β*time,也可以选其中一个为 optimizing metric,其他为 satisfying metrics。
例子:
我们更关心准确率,所以准确率是优化目标,同时希望耗时不要太长,所以运行时间是满足指标,最后整体指标就是在 100ms 运行时间的条件下准确率的大小。
什么时候改变评价指标?
模型在 metric + dev/test 上表现很好,但是在实际应用中表现不好的时候,就应该考虑改变 metric 了。
假设现在有两个算法:
- 算法 A: 喵咪图片识别误差是 3%,但是会把少儿不宜的图片分类为猫
- 算法 B:误差是 5%,但是不会给用户推送不健康的图片
我们的 dev + metric 偏好 A,但我们的用户偏好 B,两者存在分歧,这时我们就需要改变评价指标了。根据上面的例子,假设原来的评价指标是: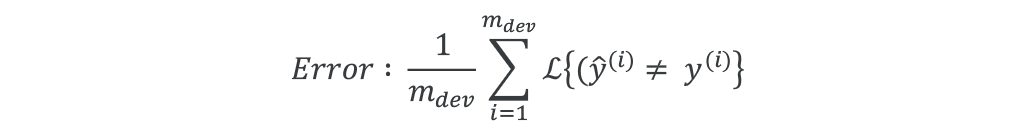
那么现在可以给“把少儿不宜的图片分类为猫”这个错误一个大的惩罚权重,当然前提是先把这些少儿不宜的图片标注好。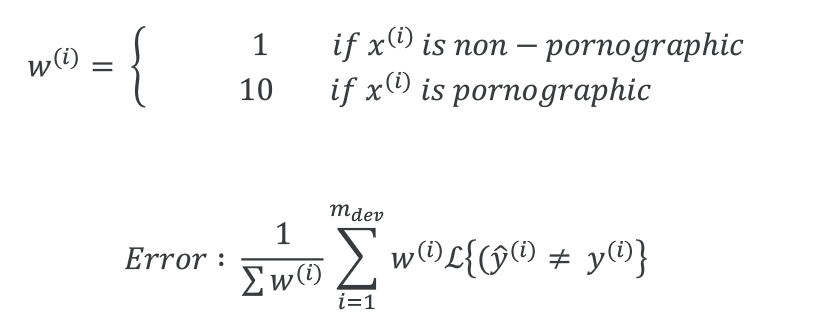
训练/开发/测试集
机器学习通常会把数据集分为训练/开发/测试集,这一篇讲一讲这三个子集扮演的角色。
最重要的一点是:
dev set + single metric => target(瞄准的目标)
开发集和测试集的选择通常是现实中希望去处理的数据,很重要的一点是 开发集和测试集必须服从同一分布。举个例子,复习考试,训练集是复习资料,开发集像是考试前的模拟试卷,测试集则是真实考卷,我们最终目标是在真实考卷(测试集)中取得好成绩,准备过程中优化的是模拟试题(开发集)上的成绩,而复习资料(训练集)的选择会影响我们逼近这个目标有多快。而如果开发集和测试集来自不同分布,比如说在英语模拟试卷上考了 99 分,但最后你去参加了语文考试,这不是白复习白训练了么~
训练/开发/测试集的大小
之前传统 ML 时代数据集比较小, 一般 < 10,000,所以 train/dev/test 的划分通常是 60%/20%/20%,而现在的数据量很大,动辄百万级,划分 40% 的数据处理做开发/测试集显然是浪费,所以比例可以是 98%/1%/1%。
可避免偏差 available bias 和Human-level performance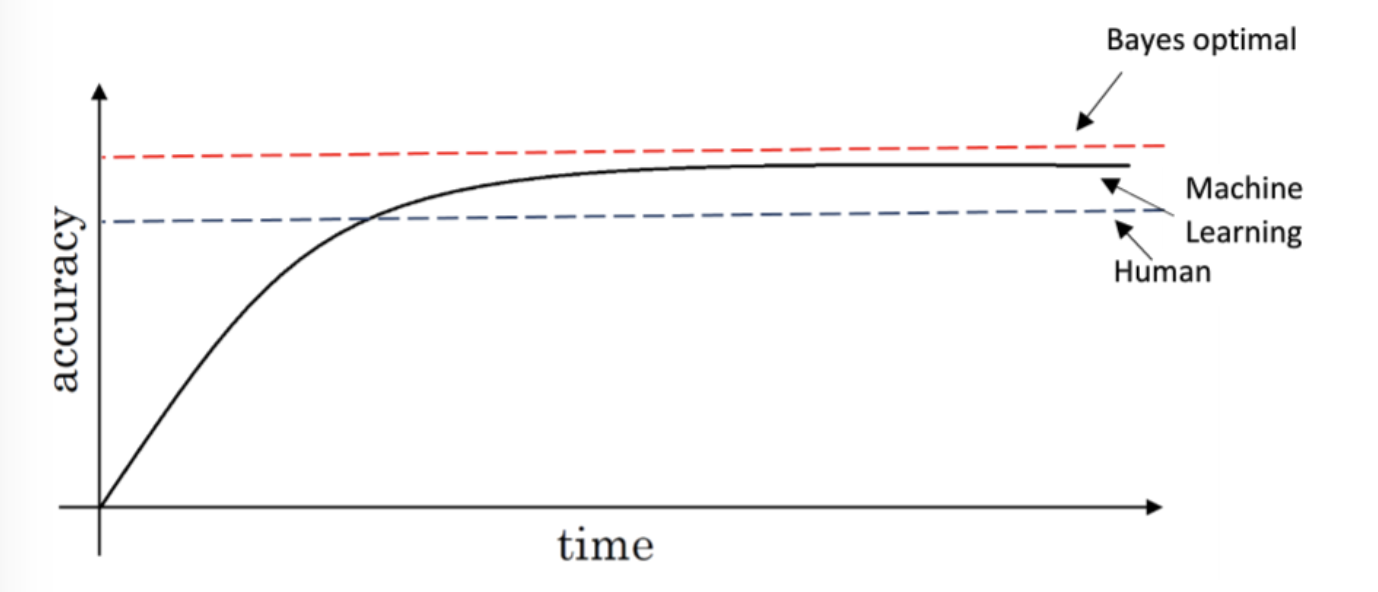
Humans error 与 Training Error之间的差距是 Avoidable bias,Training Error 与 Dev Error之间的差距是 Variance,提到过好多次啦,具体见 会议笔记 - Nuts and Bolts of Applying Deep Learning,这里简单附个图吧。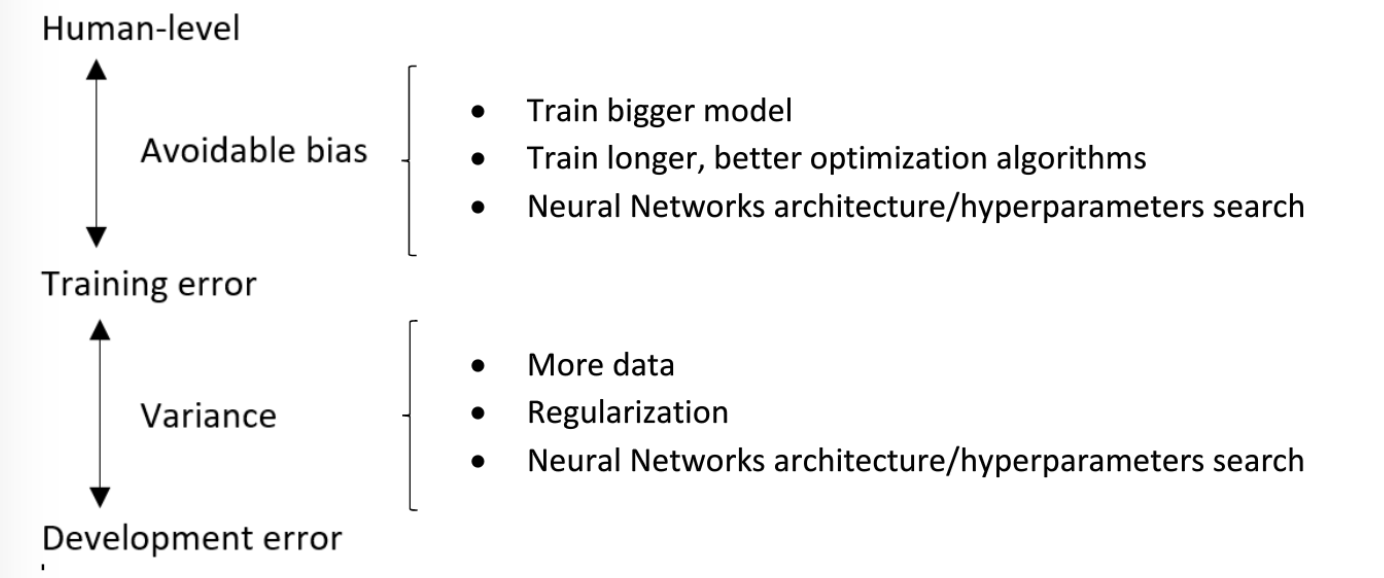
误差分析
误差分析 的作用在于弄清楚误差最主要来自哪个部分,然后给未来的工作指明优化方向,便于解决主要矛盾,节省时间。
还是猫分类器的例子,假设我们分析模型的预测结果后发现,预测错误的数据中有一部分狗的图片被错误标成了猫。这时可能会想着设计一些处理狗的特征/分类的算法功能来提高猫分类器。然而,假如 100 个错误标记的开发集样本中,只有 5 个是狗,那么这意味着你针对狗的算法提高最终也只能优化误差的 5%,比如原来误差是 10%,最好的情况也只是优化到 9.5%,这是优化上限。
把误差的来源以及在总误差的占比列个表统计,就能清楚的发现解决哪类误差对模型优化帮助最大。这个过程中可能会发现新的错误类型,比如滤镜导致的误差。
统计完成后根据误差占比、问题难度、团队的时间精力,来选择其中优先级高的几个进行优化。
如果训练数据中有一些标记错误的例子怎么办?
如果这种误差是 随机误差,人没有注意而随机产生的,那么不用花太多时间修复它们,只要数据集足够大,对最后的结果不会有太大影响,因为深度学习算法对随机误差有一定健壮性(robustness)。
但如果这种误差是 系统性误差,比如把把所有白色的狗都标注成了猫,那么问题就大了,学习之后所有白色的狗都会被分类成猫,这就需要重新标记了。
如果开发/测试集中有一些标记错误的例子怎么办?
在误差分析中加一列 incorrectly labeled,然后看是否值得修正这些标记错误的例子

如果人工错误标记引起的错误样本比例是 0.6%,而总体开发集误差是 10%,那么应该集中精力解决剩下的 9.4%,而如果总体开发集误差是 2%,那么就应该考虑去纠正这些人为错误了。
但要注意的是,不管要不要纠正人为误差,都要同时作用在开发集和测试集上,确保两者服从同一分布。同时,也可以考虑再次检查那些分类正确的例子,因为本来 no 的例子可能被标记成了 yes,不过正常情况下判断错的次数比判断对的次数要少的多,所以检查这部分数据花的时间也长的多。
训练/测试集来自不同分布
如果训练集的分布和开发/测试集不一样怎么办? 这种情况并不少见。比如说,我们有网上爬取的猫的图片 20w,但只有用户在手机 APP 上传的图片 1w。
这时候,可能会想到把这 21w 条数据 shuffle 然后来划分,这样的好处是训练/开发/测试集来自同一分布,但是!你会发现开发/测试集上的很多图片都来自网页下载,这并不是我们真心关心的数据分布,也就是说,只有一小部分的数据是我们的模型真心要瞄准、要优化的目标,而实际上我们大部分精力都在优化网页下载的图片!
再回顾一下核心思想,开发集/测试集是真正关心的要优化的目标数据。所以更恰当的做法是,把手机上传的一半图片 5k 条划给训练集,剩下的 5k 条全部划分为开发/测试集。
要注意的是,训练/测试集来自不同分布会对 方差/偏差分析 造成影响,因为这不再是正交化的分析了。比如说
- training error 1%
- dev error 10%
如果训练集和开发集来自同一分布,很简单,这是出现了高方差的问题。但如果训练集和开发集来自不同的分布,那么可能这里就不是高方差的问题了,造成这种情况的原因有两种:
- 算法看不到开发集数据,难以泛化
- 训练集和开发集来自不同的分布
我们需要知道哪个因素影响更大,才能判断是不是高方差的原因。这时需要定义一个新的数据集 training-dev set,通过随机打散训练集,分出一部分训练集和开发集一起作为训练-开发集,这样的话,training-dev set 和 training set 来自同一分布,同时 trainging-dev set 和 dev/test set 也来自同一分布。
现在只在训练集上训练模型
- training error 1%
- training-dev error 9%
- dev error 10%
这就是方差问题,模型泛化能力差。
- training error 1%
- training-dev error1.5%
- dev error10%
这时候就是 数据不匹配问题(data mismatch problem )了。
也就是说,当训练集和开发/测试集来自不同分布的时候,我们需要考虑下面 5 种 error:
- human error: 0%
- training error: 10%
- training-dev error: 11%
- dev error: 20%
- test error: 20%
这个例子就是 高方差+数据不匹配 问题。

如果误差分析显示有数据不匹配的问题该怎么办
- 可以人工做误差分析,了解训练集和开发测试集的差异
- 收集更多与开发集、测试集相似的训练数据,人工数据合成
比如 clear audio + car noise => synthesized in-car audio

