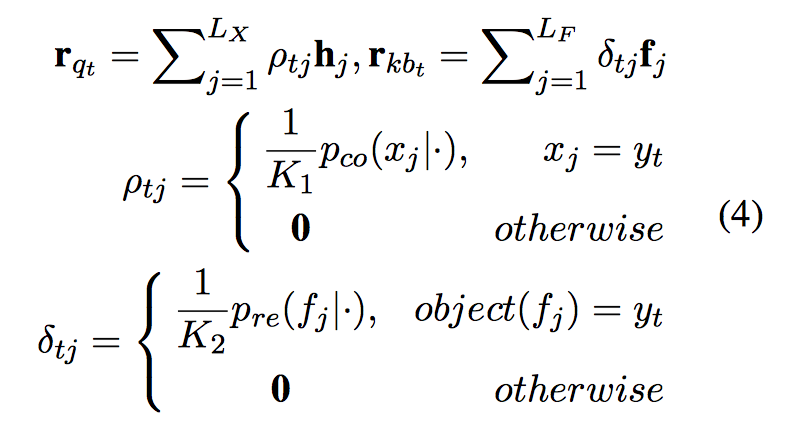关于 Point Network & CopyNet 的几篇论文笔记。
普通的 Seq2Seq 的 output dictionary 大小是固定的,对输出中包含有输入单词(尤其是 OOV 和 rare word) 的情况很不友好。一方面,训练中不常见的单词的 word embedding 质量也不高,很难在 decoder 时预测出来,另一方面,即使 word embedding 很好,对一些命名实体,像人名等,word embedding 都很相似,也很难准确的 reproduce 出输入提到的单词。Point Network 及 CopyNet 中的 copy mechanism 就可以很好的处理这种问题,decoder 在各 time step 下,会学习怎样直接 copy 出现在输入中的关键字。
涉及到的论文:
- Pointer Networks. NIPS 2015
- Incorporating Copying Mechanism in Sequence-to-Sequence Learning. ACL 2016.
- Get To The Point: Summarization with Pointer-Generator Networks. ACL 2017
- Generating Natural Answers by Incorporating Copying and Retrieving Mechanisms in Sequence-to-Sequence Learning. ACL 2017
Pointer Network(Ptr-Net)
主要来解决传统 Seq2Seq 中 output dictionary 大小固定(fixed prior)的问题。思路非常简单,实际上就是 attention Seq2Seq 的一个简化版本,不过产生的不是输出序列,而是指向输入序列的一堆指针(或者从输入序列中挑选一个元素进行输出)。论文解释了这种结构可以用来解决 旅行商(Travelling Salesman Problem)、凸包(convex hulls) 等问题。
结构对比: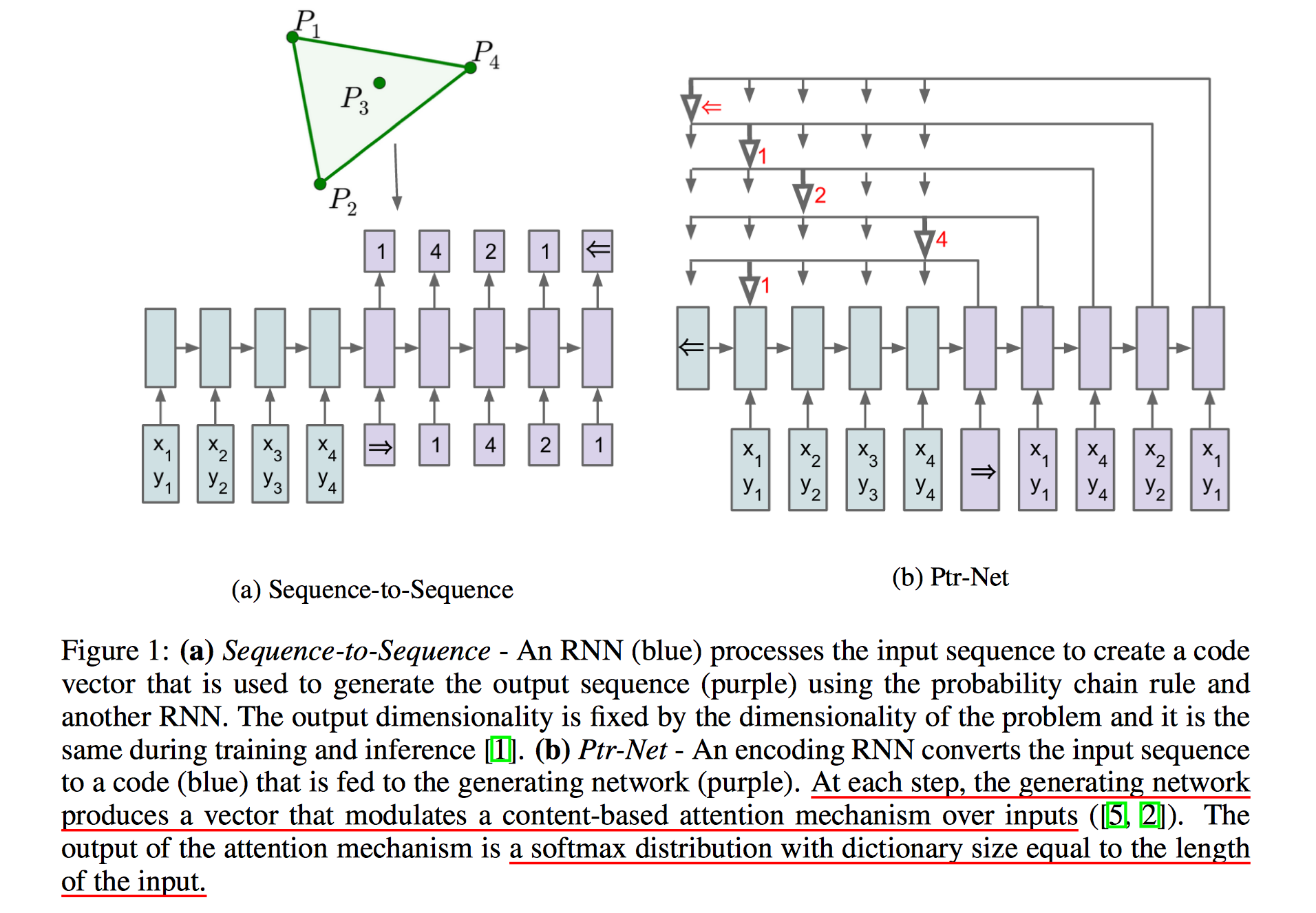
还是先来看一下经典的 attention-based seq2seq, 在每一个 decoder step,先计算 $e_{ij}$ 得到对齐概率(或者说 how well input position j matches output position i),然后做一个 softmax 得到 $a_{ij}$,再对 $a_{ij}$ 做一个加权和作为 context vector $c_i$,得到这个 context vector 之后在固定大小的 output dictionary 上做 softmax 预测输出的下一个单词。
经典 Attention: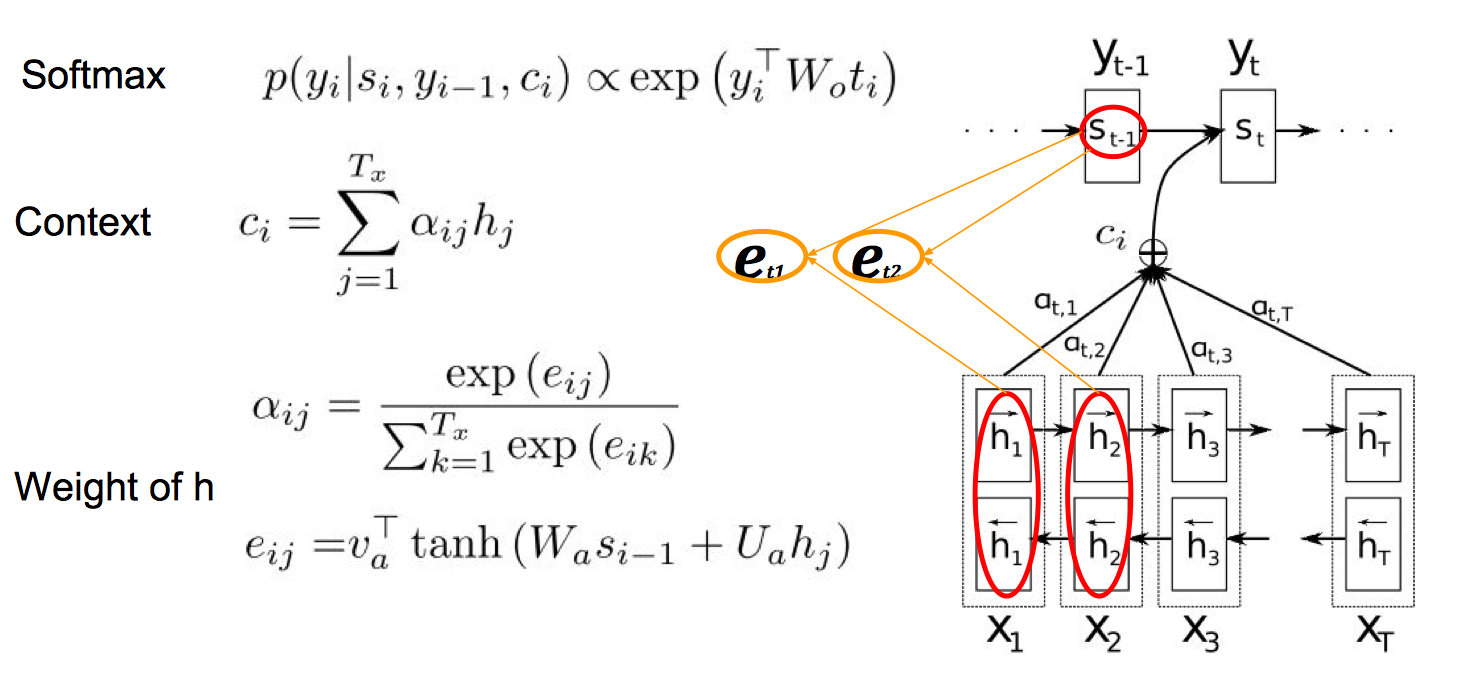
而 Ptr-Net 不过是简化了后面的步骤,有了 $e_{ij}$ 后直接做 sofmax,可以得到一系列指向输入元素的指针 $a_{ij}$,最直观的用法就是对输入元素进行排序输出了。
CopyNet
CopyNet 实现的是能够把输入中的部分信息原封不动的保留到输出中,相当于一个 refer back。一个简单的例子:
|
|
这个”毛毛”,可能是 OOV,也可能是其他实体或者是日期等很难被 decoder “还原” 出来的信息,CopyNet 可以更好的处理这类的信息。
那么问题主要有两个:
- What to copy: 输入中的哪些部分应该被 copy?
- Where to paste: 应该把这部分信息 paste 到输出的哪个位置?
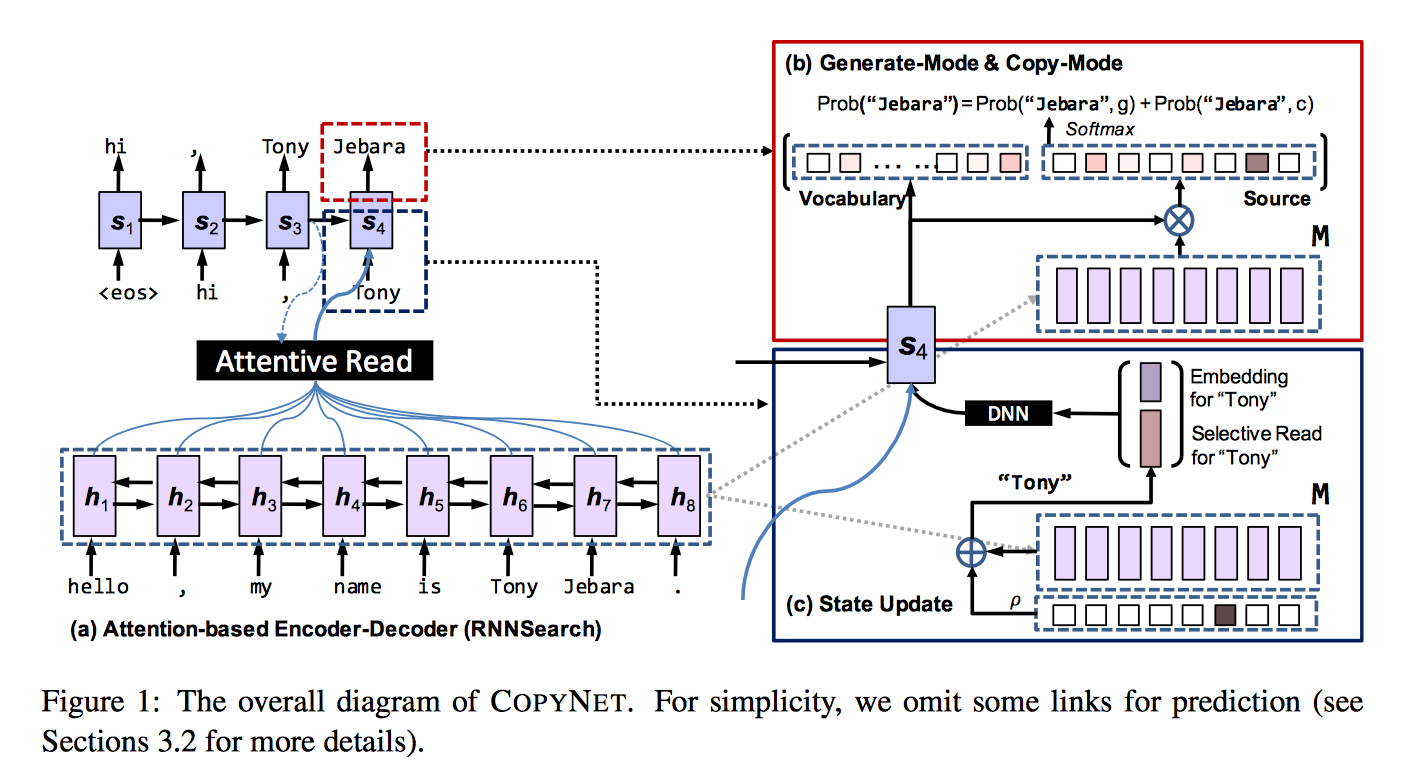
框架还是基于 attention-based encoder-decoder,不过在 decoder 的时候,做了部分改进,总的来说,下一个单词的预测是由一个 generate-mode g 和 copy-mode c 的混合概率模型决定的。
$$p(y_t|s_t, y_{t-1}, c_t, M) = p(y_t, g|s_t, y_{t-1}, c_t, M) + p(y_t, c|s_t, y_{t-1}, c_t, M) $$
要实现 CopyNet 需要有两个词汇表,一个是通常意义的高频词词汇表 V={$v_1,…,v_N$} 加上 OOV,另一个是在输入中出现的所有 unique words X={$x_1, …, x_{T_S}$},这部分可能会包含没有在 V 里出现的单词,也就是 OOV 单词,第二个词汇表用来支持 CopyNet,最终输入的词汇表是三者的并集 $V ∪ UNK ∪ X$。
对 encoder 部分(双向 RNN) 的输出 $h_1, …, h_{T_S}$,记做 M,M 其实同时包含了 语义 和 位置 信息。decoder 部分对 M 的读取有两种形式:
- Content-base
Attentive read from word-embedding - location-base
Selective read from location-specific hidden units
两种模式对应的 score function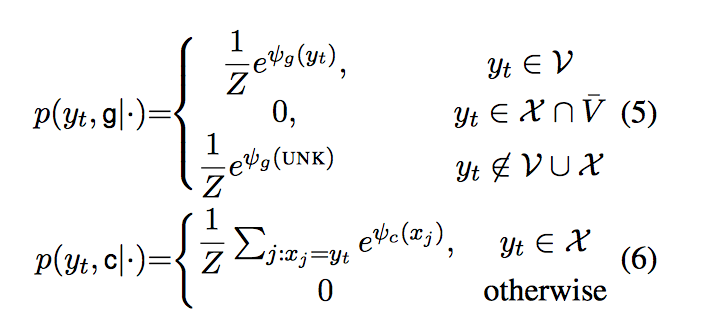
$$
\begin{aligned}
φ(y_t=v_i) &= v_i^TW_os_t, \ \ \ \ v_i ∈ V ∪ UNK \\
φ(y_t=x_j) &= σ(h_j^TW_c)s_t, \ \ \ \ vi ∈ V ∪ UNK \\
\end{aligned}
$$
$φ(y_t=v_i)$ 和普通的 RNN encoder-decoder 计算相同,$φ(y_t=x_j)$ 将 $h_t$ 和 $s_t$ 映射到了同一个语义空间,$\sigma$ 发现用 tanh 比较好,注意 $p(y_t, c|・)$ 的计算加总了所有 $x_j=y_t$ 的情况。
$s_t$ 的更新:
在用 $y_{t-1}$ 更新 t 时刻的状态 $s_t$ 时,CopyNet 不仅仅考虑了词向量,还使用了 M 矩阵中特定位置的 hidden state,或者说,$y_{t-1}$ 的表示中就包含了这两个部分的信息 $[e(y_{t-1}); ζ(y_{t-1})]$,$e(y_{t-1})$ 是词向量,$ζ(y_{t-1})$ 和 attention 的形式差不多,是 M 矩阵中 hidden state 的加权和
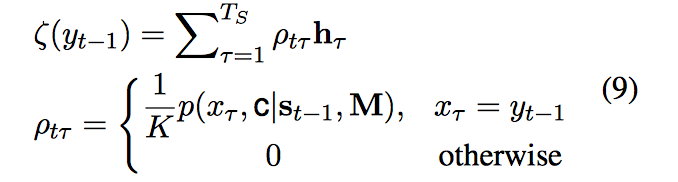
K 是 normalization term,直观上,是去找输入中也出现 $y_{t-1}$ 的单词对应的 hidden state,考虑到 $y_{t-1}$ 可能在输入中出现多次,$ρ_{tT}$ 更关注这些多次出现的词。
整条路径:
$$ζ(y_{t-1}) \longrightarrow{update} \ s_t \longrightarrow predict \ y_t \longrightarrow sel. read \ ζ(y_t)$$
一些结果:
Get To The Point: Summarization with Pointer-Generator Networks
Copy 机制在文本摘要中的应用。传统 attention-based seq2seq 存在下面两个问题
- 无法正确产生文中的事实细节
e.g. Germany beat Argentina 3-2
尤其是对 OOV 或者 rare word。在训练中不常见的单词的 word embedding 质量也不高,很难 reproduce,而即使 word embedding 很好,对一些命名实体,像是人名之类的,含义都很相似,也很难准确的 reproduce 出来
所以作者引入了一个 pointer-generator network,在 generation 的基础上,加入了 copy 输入中的一些词的能力来提高摘要的准确性,相当于引入了部分 extractive summary 的能力 - 倾向重复一些词组
e.g. Germany beat Germany beat Germany beat…
主要是因为 decoder 过程太过依赖于上一个单词,而不是 longer-term 的信息,所以一个重复的单词会 trigger 出死循环,比如上面这个例子就陷入了 Germany beat Germany beat Germany beat… 的死循环,产生不出 Germany beat Germany 2-0 这样的句子
所以有了 coverage,来追踪哪些部分已经被 summarize 过了,之后的 attention 就不会注意这些部分
Pointer-generation network
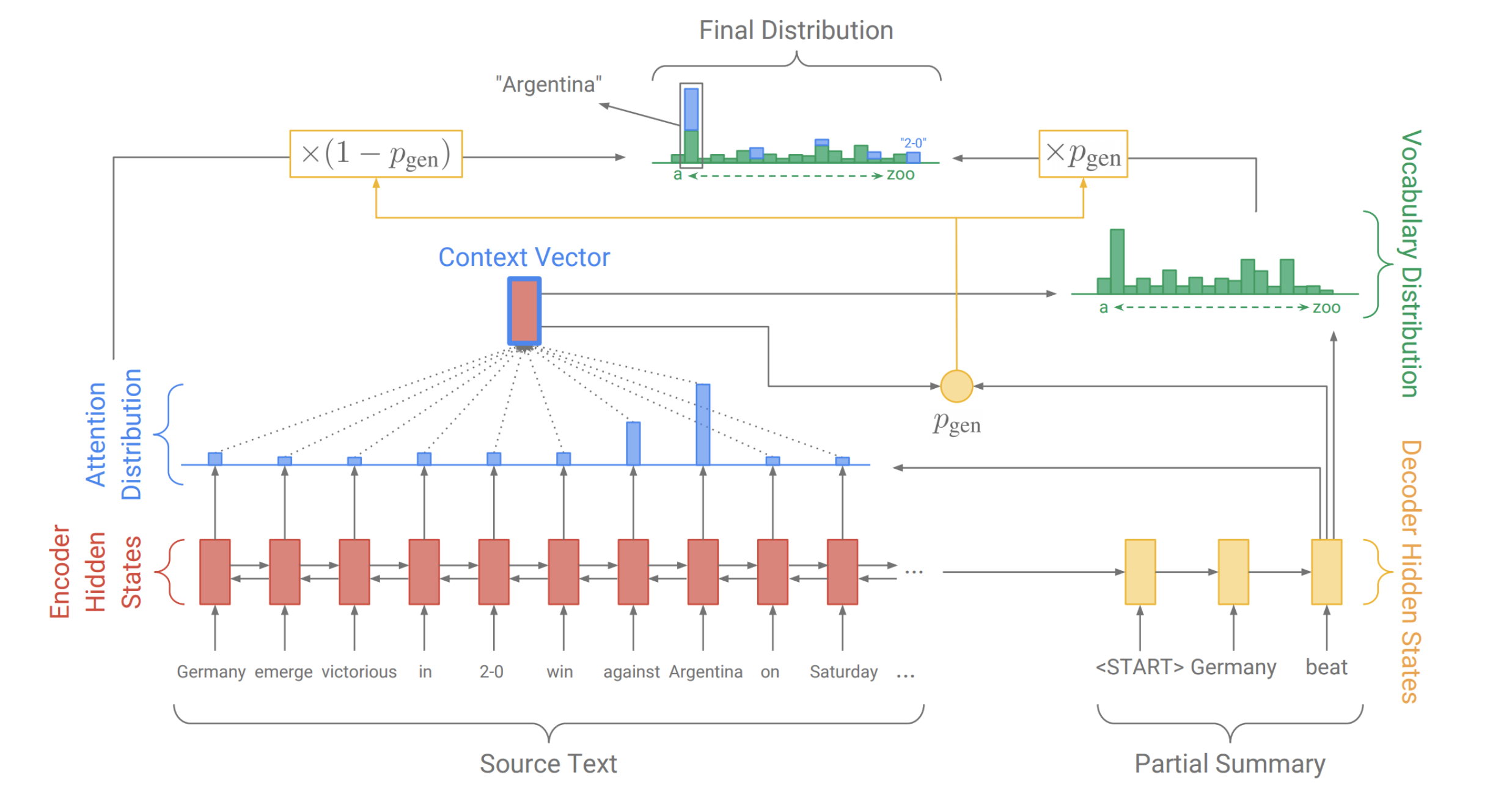
上图展示了 decoder 的第三个 step,预测 Germany beat 后面一个单词,像之前一样,我们会计算一个 attention distribution 和 vocabulary distribution,不过同时,也会计算一个产生概率 $p_{gen}$,是 0-1 间的一个值,表示从 vocabulary 中产生一个单词的概率,相应的 $1-p_{gen}$ 就是从输入中 copy 一个单词的概率
$$
\begin{aligned}
P(w) &= p_{gen}P_{vocab}(w) + (1-p_{gen})\sum_{i:w_i=w}a_i^t \\
p_{gen} &= \sigma(w^T_{h^*}h^*_t + w^T_ss_t+w^T_xx_t+b_{ptr}) \\
\end{aligned}
$$
其中 $h^*_t$ 是 context vector,在前面我们用的是 $c_i$ 来表示。如果 w 是 OOV, 那么 $P_{vocab}=0$,如果 w 没有在输入中出现,那么 $\sum_{i:w_i=w}a_i^t=0$。
Coverage
用 attention distribution 来记录哪些部分已经总结过了,来惩罚再次加入计算的部分。decoder 的每个时刻,有一个 coverage vector $c_t$ 来将记录之前所有时刻 attention 的总和。
$$c^t=\sum^{t-1}_{t’=0}a^{t’}$$
这个 coverage 会作为 attention 计算的一个输入
$$e^t_i=v^Ttanh(W_hh_i+W_ss_t+w_cc^t_i+b_{attn})$$
对应的,有一个 coverage loss
$$covloss_t=\sum_imin(a^t_i,c^t_i)$$
整体的 loss 就是
$$loss_t=-logP(w^*_t)+\lambda \sum_i min(a^t_i, c^t_i)$$
Generating Natural Answers by Incorporating Copying and Retrieving Mechanisms in Sequence-to-Sequence Learning
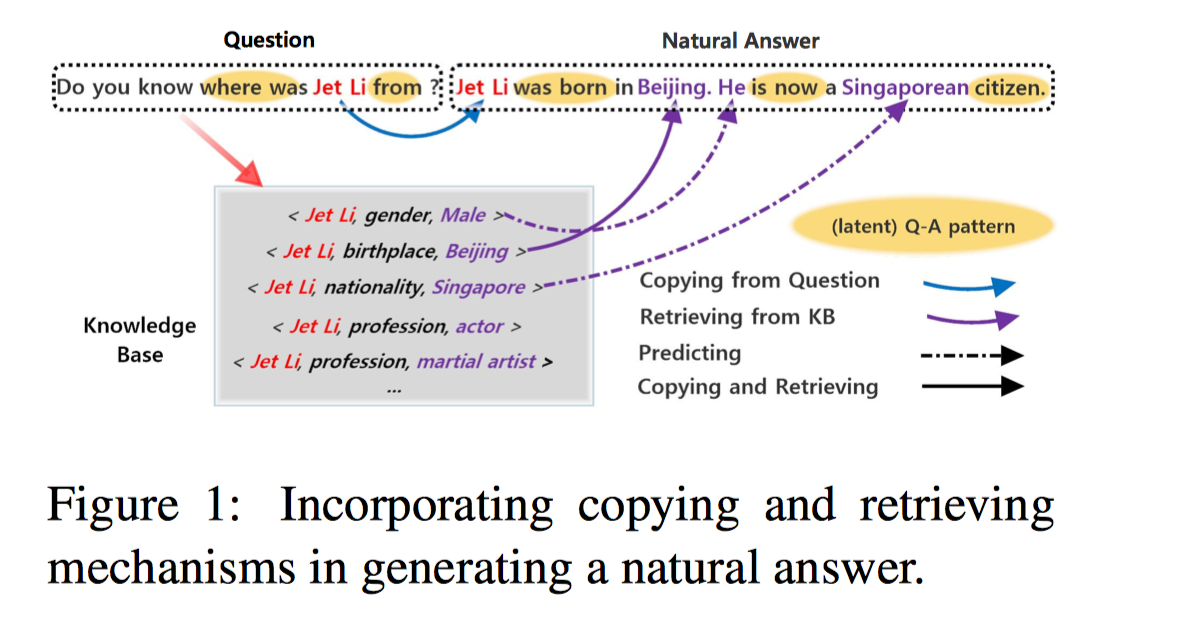
Copy 机制在问答系统中的应用。论文的模型用三种不同模式获取词汇并进行选取:用拷贝方式取得问句中的实体、用预测方式产生让答案更自然的连接词、用检索方式获取相关事实 并结合多个相关事实产生复杂问句的自然形式的答案。
|
|
传统的 QA 系统只会返回 A1,一个孤零零的实体,这对用户并不友好,A2 才是自然语言形式的答案。COREQA 利用 拷贝(copy)、检索(retrieval)和预测(prediction) 从不同来源获取不同类型的词汇,产生复杂问句的自然答案。
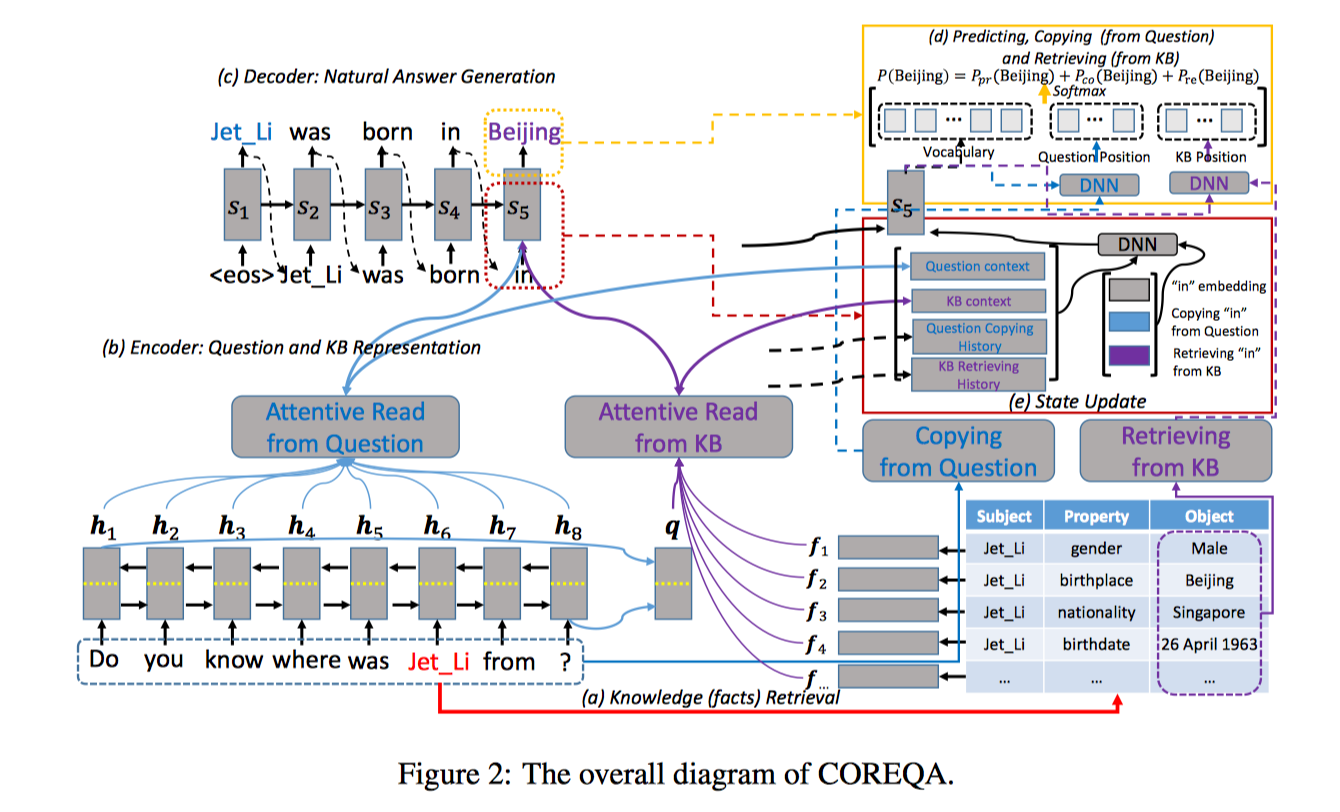
具体过程,以 Do you know where was Jet Li from 这个问题为例来说明:
- 知识检索: 首先识别问题中的包含的 topic entities。这里我们识别出的 topic entity 是 Jet Li 。然后根据 entity 从知识库中检索出相关的三元组(subject, property, object)。针对李连杰这个实体,我们可以检索出(Jet Li, gender, Male),(Jet Li, birthplace, Beijing),(Jet, nationality, Singapore) 等三元组。
- 编码(Encoder): 将问题和检索到的知识编码成向量
问题编码: 双向 RNN(Bi-RNN),把前向和后向对应的 hidden state 拼接起来形成每一时刻的 short-term memory $M_Q={h_t}$,两个方向 RNN 的最后一个向量拿出来拼在一起就得到向量 q 来表示整个问题
知识编码: 使用了记忆网络(Memory Network),对知识检索阶段得到的知识三元组 spo 分别进行编码得到 $e_s, e_p, e_o$,拼接成一个 $f_i$ 来表示这个三元组,所有这些三元组向量形成一个 list,用 $M_{KB}$ 表示
分数计算: $S(q, s_t, f_j) = DNN_1(q, s_t, f_j)$ - 解码(Decoder): 根据 $M_Q$ 和 $M_{KB}$ 来生成自然答案。单词预测有三种模式,predict-mode, copy-mode 和 retrieve-mode,predict-mode 和普通 seq2seq 原理相同,生成词汇表中的单词,copy-mode 从问句中复制单词,retrieve-mode 从知识库中选取单词。过程和 CopyNet 差不多,也有两种读取方式,一种是读取语义,一种是读取位置。
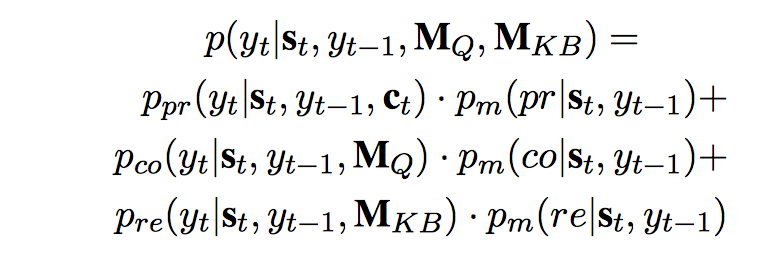
$p_{pr}, p_{co}, p_{re}$ 以及对应的 score function 和前面的 CopyNet 非常相似,包括之后的 state update 部分也和 CopyNet 差不多,不过是多了 $r_{kb}$ 而已。