介绍一下经典的 End-to-end 聊天模型及应用,包括检索式模型、生成式模型,以及 Google 邮件自动回复的应用。
主要涉及到下面几篇论文
- The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems
- A Neural Conversational Model
- Smart reply, automated response suggestion in email
- How NOT To Evaluate Your Dialogue System
- Zhengdong Lu & Hang Li, 2013, A Deep Architecture for Matching Short Texts
- Zongcheng Ji, et al., 2014, An Information Retrieval Approach to Short Text Conversation
- Baotian Hu, et al., 2015, Convolutional Neural Network Architectures for Matching Natural Language Sentences
- Aliaksei Severyn, et al., 2015, Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks
- Building end-to-end dialogue systems using generative hierarchical neural network models
Modular system vs end-to-end system
第一部分先简单比较一下对话系统中 modular system 和 end-to-end 的不同。
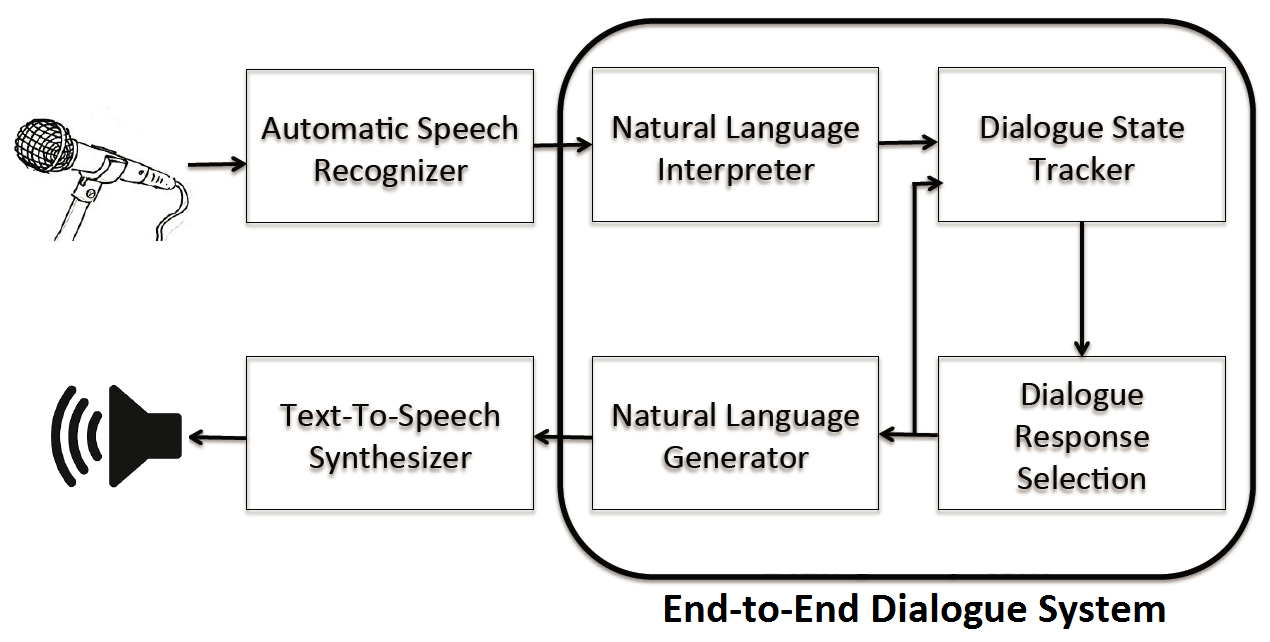
如上图,传统的一个对话系统由 Speech Recognizer, Language Interpreter, State Tracker, Response Generator, Natural Language Generator, Speech Synthesizer 这么多个子模块拼接而成,这种系统称为 Modular system,在系统中每个组件单独训练,来优化一个单独的中间目标(如 slot-filling)。而 end-to-end system 相当于用一个系统替代了上图中框起来的四个组件,来比较一下
Modular system vs end-to-end system
- 目标函数
modular system 有两个及以上的目标函数
end-to-end 通常只有一个目标函数 - 所需数据
modular system 更容易训练,需要的数据少
end-to-end 需要大量数据 - 人工标注
modular system 需要大量的人工的特征工程,需要预先定义 state, action spaces 等等
end-to-end 不需要预先定义的 state/action spaces - 效果
modular system 在 highly structured tasks/narrow domain 上的效果更出色,但泛化能力有限
end-to-end 在 general purpose 的效果上比较好
Retrieval-based models vs Generative models
对话模型分 检索式(Retrieval-based models ) 和 生成式(Generative models) 两种,检索式的聊天模型有一个预先定义好的模板库,给定一个 query,来从模板库里选择最好的 response。回复的产生依赖于模板库,不可能产生模板库没有的句子。而生成式模型不依赖于模板库,而是直接产生的,生成式模型的方法大多依赖于机器翻译的技术,但不是从一个语言翻译到另一个语言,而是从一个输入映射到回复。
两种方法都有利有弊,检索式模型得到的回复不会产生语法错误,但没法处理在模板库里不存在回复的用户输入,另外,检索式模型也很难结合上下文信息。而生成式模型更加的“聪明”,可以结合语境,然而更难训练,也更容易犯语法错误(尤其是长句),需要的训练数据也很大。
Retrieval-Based Models
可以看做是一个 检索/排序/匹配 问题,有一个预先定义好的模板库(看做是检索系统的文档集),给定一个 query,来从模板库里选择最好的 response,这里需要计算一个 score(query, response) 来衡量 query 和 response 的匹配程度,score 越高,response 越可能是一个合适的回复。response 也可以替换成标准 query,这就把问题转换为用户 query 和标准 query 的一个相似度计算问题,这里的 score 就是相似度分数。
需要学习的一个是语义表达,一个是 score 的计算。score 可以单独用传统方法做,也可以在神经网络的 MLP 层做,还可以在语义表达产生的过程中做。
有下面一些经典的论文,(Q, Q’),(Q, A) 或 (Q, D) 的匹配在这里统一表示为 (Q, D),D 可以是标准 query,可以是 answer,也可以是标准 query + answer
- Zhengdong Lu & Hang Li, 2013, A Deep Architecture for Matching Short Texts
DeepMatch,先用 (Q, D) 语料训练 LDA 主题模型,得到其 topic words,这些主题词被用来检测两个文本是否存在语义相关性(Localness);每次指定不同的 topic 个数分别训练 LDA 模型,得到几个不同分辨率的主题模型(Hierarchy),高分辨率的 topic words 更具体,低分辨率的更抽象,这可以避免短文本词稀疏带来的问题,并得到不同的抽象层级 - Zongcheng Ji, et al., 2014, An Information Retrieval Approach to Short Text Conversation
从不同角度构造匹配特征,作为 ranking 模型的特征输入,构造的特征包括:1)Query-ResponseSimilarity;2)Query-Post Similarity;3)Query-Response Matching in Latent Space;4)Translation-based Language Model;5)Deep MatchingModel;6)Topic-Word Model;7)其它匹配特征 - Baotian Hu, et al., 2015, Convolutional Neural Network Architectures for Matching Natural Language Sentences
基于 CNN,Q 和 D 分别经过多次一维卷积和池化,得到的固定维度的两个 sentence embedding,然后输入到 Siamese 结构的 MLP 层,得到文本的相似度分数。这种方法的监督信号在最后的输出层才出现,在这之前,Q 和 D 的 embedding 相互独立生成,可能会丢失语义相关信息,所以有第二种结构,在第 1 层卷积后就把 Q 和 D 做融合,融合方式是分别对 Q 和 D 做 1D 卷积,然后针对两者卷积得到的 feature map,构造其所有可能的组合(在两个方向上拼接对应的 feature map),这样就构造出一个 2D 的 feature map,然后对其做 2D MAX POOLING,多次 2D 卷积和池化操作后,输出固定维度的向量,接着输入 MLP 层,最终得到文本相似度分数。实验表明优于 DeepMatch - Aliaksei Severyn, et al., 2015, Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks
分别对 Q 和 D 做 wide 1D 卷积和 MAX 池化,得到文本的语义向量,接着通过 M 矩阵变换得到语义向量的相似度,然后把 Q 语义向量、Q&D 的语义相似度、D 语义向量、外部特征拼接成 n 维向量,输入一个非线性变换隐层,最终用 softmax 做概率归一化。用 softmax 的输出作为监督信号,采用 cross-entropy 作为损失函数进行模型训练
这里介绍的是 Dual-Encoder 模型(Ryan Lowe, et al., 2016, The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems),通过对偶的 RNN 模型分别把 context 和 response 编码成语义向量,然后通过 M 矩阵变换计算语义相似度,相似度得分作为监督信号在标注数据集上训练模型。
句子表达
先来看一下怎么表达 query 和 response。语义特征方面很容易想到 TFIDF,然而它忽略了词序,表达效果没那么强,所以考虑用 sentence embedding。sentence embedding 可以用 RNN/LSTM 来获取。还是 Encoder-decoder 的思想,不过这里把 decoder 给替换了成了另一个 encoder,也就成了 Dual-RNN 的结构。两个独立的 RNN 分别对 context/ query和 response 进行编码,每个 RNN 最后一个 hidden state 相当于是对整个 input(context/response) 的一个总结。
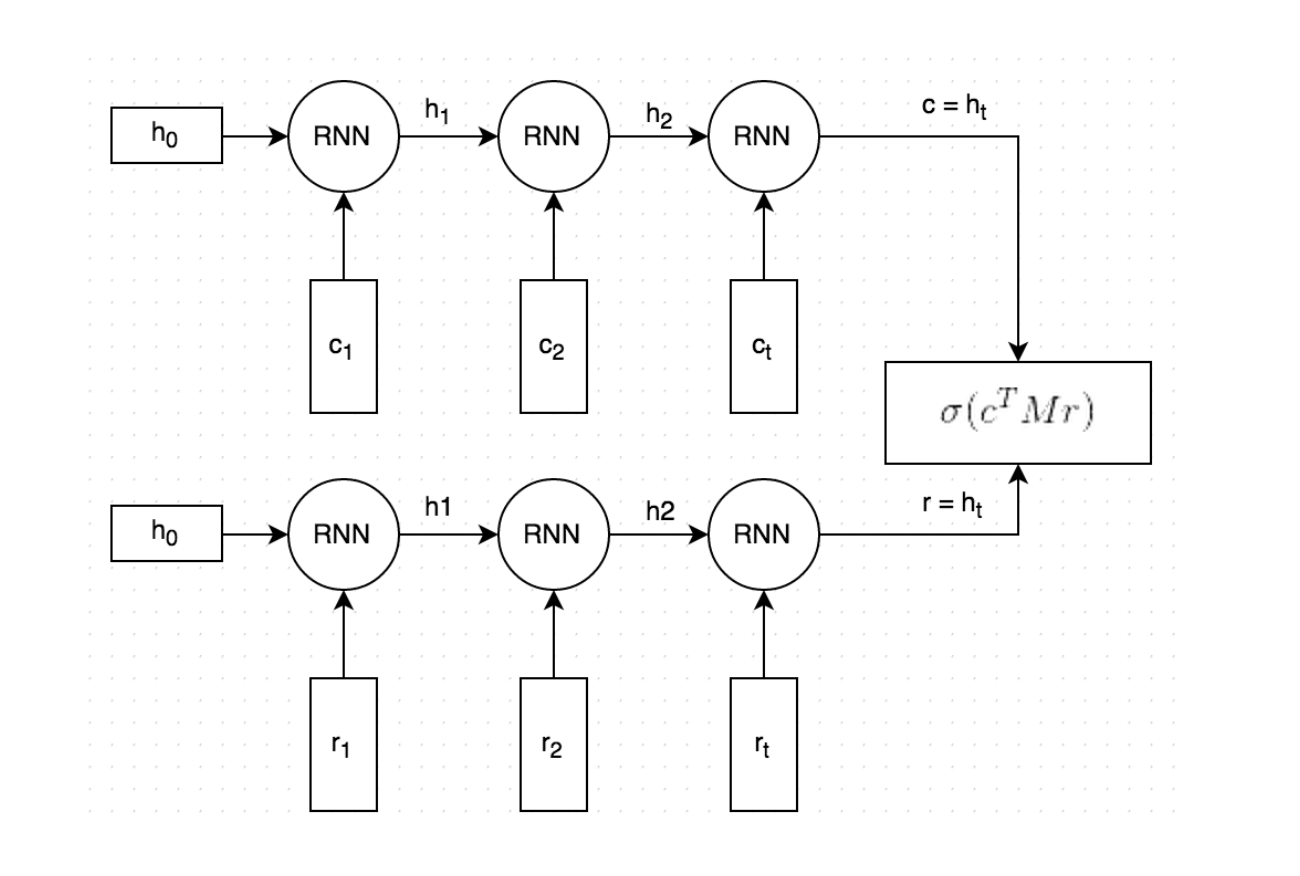
分数计算
模型的学习目标其实是一个 binary 分类器
$\sigma (score(Query, Response_true)) -> 1$
$\sigma (score(Query, Response_false)) -> 0$
先来看下如何计算分数。
$$p(flag=1|c,r,M)=\sigma(c^TMr+b)$$
这个过程可以看做是一个产生模型,给定 input response,用 $c’=Mr$ 产生一个 context (M 是 dxd 的参数矩阵),然后利用点乘来及计算这个产生的 context 和真实 context 的相似度分数,再用 sigmoid 将这个分数转化为概率,最小化交叉熵损失函数来将进行训练。
简单一个例子来理解这个过程,假设下图 5x5 的表格,i 行 j 列代表 $(query_i, response_j)$,我们希望对角线的 probability 最大,因为对角线对应着正确的 (query, response),真实的 label 是一个 identity matrix,我们的 prediction 是 5x5 的 score,现在对每一行进行 softmax cross-entropy 损失函数的计算,其实就相当于直接优化 retrieval metrics (Recall@k),即 (query, response) 在所有 pair 里的排名。
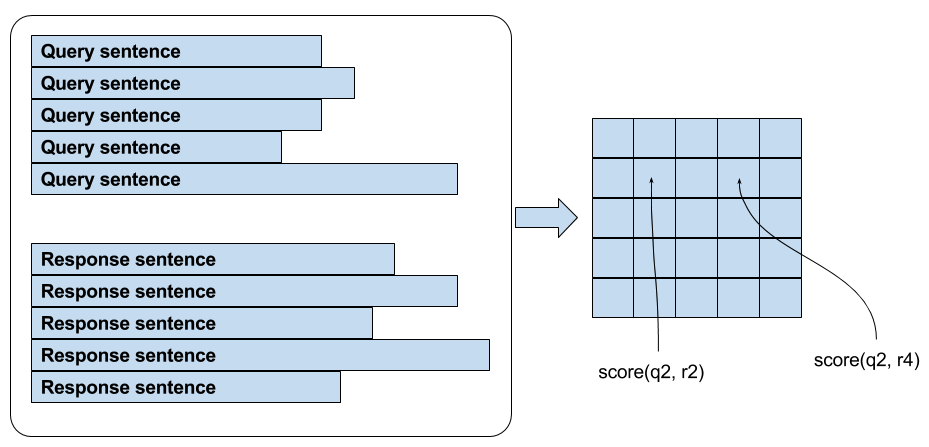
从代码角度理解一下,下面是训练阶段的一个 minibatch 过程,假设 minibatch 大小为 5
|
|
测试阶段,计算的是 Recall@k (给定一个 query,选择 k 个最有可能的 response,看正确的 response 在不在这 k 个里)。举个例子,从整个 test data/validation data 随机抽取 19 个错误答案,对每一个样本,计算 20 个 response 的 score,看真实回复的 score 是否排名前 k。response 矩阵连续的 20 行对应一个 query,第 1 行、21行、41行…对应真实的 response,其他是错误 response。将 query 复制 20 次,就得到 100x128 的 query 和 100x128 的 response (假设 rnn_dim=128),点乘得到每个 (query, response) 的 score,也就是 100x100 的矩阵,然后再 reshape 成 5x20 的矩阵,再计算 Recall@k
代码
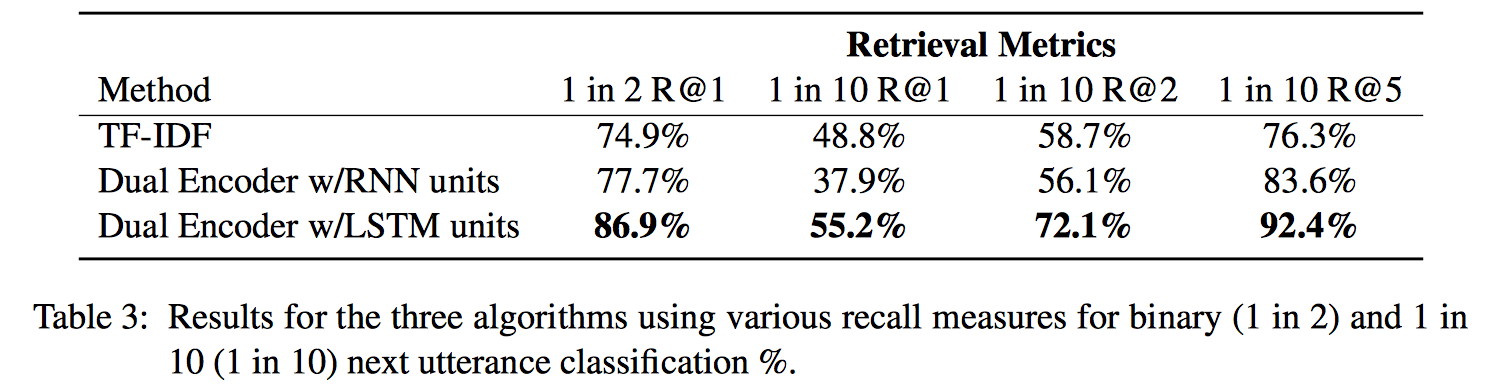
Generative Models
产生模型并不是从模板库里选一个分数最高的 response 出来,而是去自动生成这样一个 response。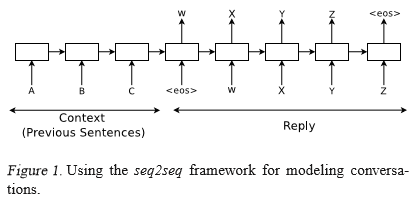
将 MT 问题中引入的 seq2seq 模型应用到对话任务上。给出 (query, response) 以后,seq2seq 对 query 进行编码,最后一个 hidden state 包含 query 的所有信息,结合开始标记 EOS 进行解码,得到 response。不过这种方法对上下文依赖考虑有限,HRED(Hierarchical Recurrent Encoder-Decoder) 为解决这个问题做了改进。
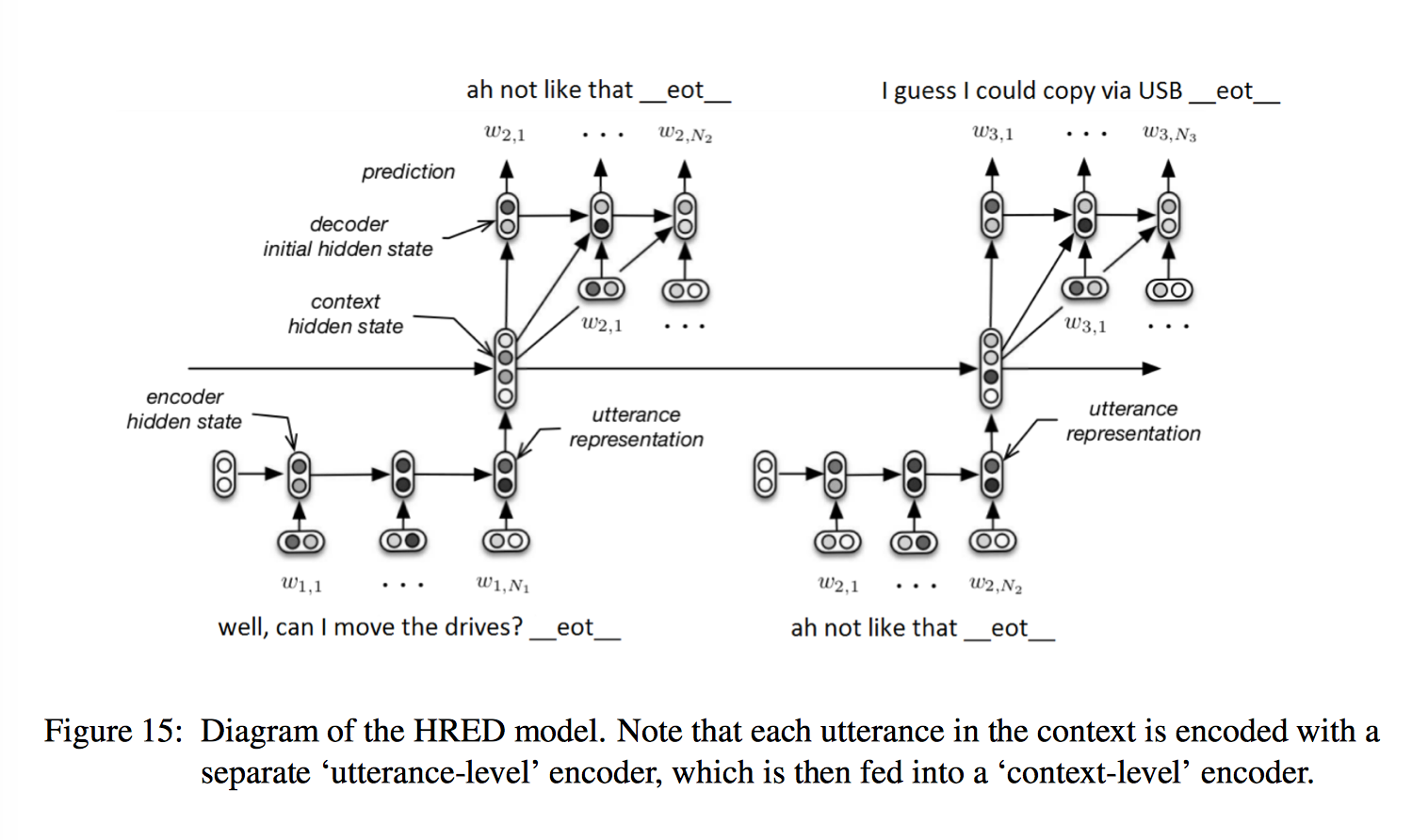
HRED 在传统 encoder-decoder 模型上,额外增加了一个 encoder,相比于普通的 RNN-LM 来说,考虑了 turn-taking nature,能够对上下文进行建模,有助于信息/梯度的传播,从而实现多轮对话。有下面三个阶段:
- encoder RNN
第一个 encoder 和标准的 seq2seq 相同,将一句话编码到固定长度的 utterance vector,也就是 RNN 的 last hidden state - context RNN
n 个句子的 utterance vector 作为第二个 encoder 也就是 context-level encoder 各个时间上的的输入,对应长度为 n 的 sequence,产生一个 context vector 实现对语境的编码,也就是 RNN 的 output (注意这里不是 last hidden state) - decoder RNN
上一个句子的 utterance vector 作为 response 的初始状态,目前为止产生的 context vector 和上一个单词的 word embedding 拼接作为 decoder 的输入
然而 HRED 相对于传统的 Seq2Seq 模型的提高并不明显,bootstrapping 的作用更加明显。一方面可以用 pre-trained word embedding,另一方面可以使用其他 NLP 任务的数据预训练我们的模型,使得模型的参数预先学到一些对自然语言的理解,再来学习聊天任务。

看上面的例子,可以发现 seq2seq 模型可以在一定程度上记住知识,理解语境,进行简单的推理(图左),然而并不能保留记忆和性格,对相同语义的不同表达会返回不同的答复(图右)。另外要注意的是,这个场景下 seq2seq 的训练目标和真实目标实际是不一样的,尤其在闲聊场景中。训练阶段关注的是真实 response 出现的概率和怎么最大化这个概率,而测试阶段或者说真实场景下,对话侧重于交流信息,以及长时间的连贯性,考虑到回复的灵活性(如一个 query 可以有多种合适的回复),以及经产生模型的自由度(并不需要在模板库里面选择回复,可以是全新的句子),因此使用合适的 Metric 来衡量产生的句子实际是非常困难的问题。
objective function being optimized does not capture the actual objective achieved through human communication, which is typically longer term and based on exchange of information rather than next step prediction
Metrics
Metrics 的设计目标是使得 metric 的判断和人为判断尽量相似。
Retrieval Metrics: Recall@k
Recall@k 是信息检索里的评估方法,给定一个 query,选择 k 个最有可能的 response,看正确的 response 在不在这 k 个里。
Generative Metrics
- 相对于机器翻译,对话中回复的选择空间大很多; 看起来完全无关的两句话都可以是合适的回复
- 而这两个正确的回复如果不看context的话,无论是从词频 还是语义来看都是不相关不想似的句子

Word Overlap-based Metrics
主要有 BLEU,ROUGE 和 METEOR,最初用于衡量机器翻译的效果。BLEU 主要看人为/测试的句子里的单词的 overlap (机器产生的待评测句子中的 ngram 正确匹配人工产生的参考句子中 ngram 与机器产生的句子中所有 ngram 出现次数的比值),加入 BP(Brevity Penalty) 惩罚因子可以评价句子的完整性。然而 BLEU 不关心语法,只关心内容分布,适用于衡量数据集量级的表现,在句子级别的表现不佳。
“BLEU is designed to approximate human judgement at a corpus level, and performs badly if used to evaluate the quality of individual sentences.”——wikipedia
ROUGE 是一种基于召回率的相似性度量方法,与 BLEU 类似,但计算的是 ngram 在参考句子和待评测句子的共现概率,包含 ROUGE-N, ROUGE-L(最长公共子句, Fmeasure), ROUGE-W(带权重的最长公共子句, Fmeasure), ROUGE-S(不连续二元组, Fmeasure) 四种,具体不多说。
METEOR 改进了 BLEU,考虑了参考句子和待评测句子的对齐关系,和人工判断的结果有更高的相关性。
Embedding-based Metrics
侧重比较生成的句子和真实样本的语义相似度。
- Embedding average score
将句中每个单词的词向量作平均来作为句子的特征,计算生成的句子和真实句子的特征的 cosine similarity - Greedy matching score
寻找生成的句子和真实句子中最相似的一对单词,把这对单词的相似度近似为句子的距离 - Vector extrema score
对句中单词词向量的每一个维度提取最大(小)值作为句子向量对应维度的数值,然后计算cosine similarity
Human judgement
“We find that all metrics show either weak or no correlation with human judgements, despite the fact that word overlap metrics have been used extensively in the literature for evaluating dialogue response models”
在 How NOT To Evaluate Your Dialogue System 这篇论文中,宣称和人工判断相比,上述的所有 metric 都是垃圾
- 在闲聊性质的数据集上,上述 metric 和人工判断有一定微弱的关联 (only a small positive correlation on chitchat oriented Twitter dataset)
- 在技术类的数据集上,上述 metric 和人工判断完全没有关联(no correlation at all on the technical UDC)
- 当局限于一个特别具体的领域时,BLEU会有不错的表现
Learning to Evaluate Dialogue Responses
可以尝试使用机器学习的方法来学习一个好的 metric,用语境 c,真实回复 r,机器回复 $\hat r$,训练一个 regression 模型,使得 score 和人工打分的 score 接近。
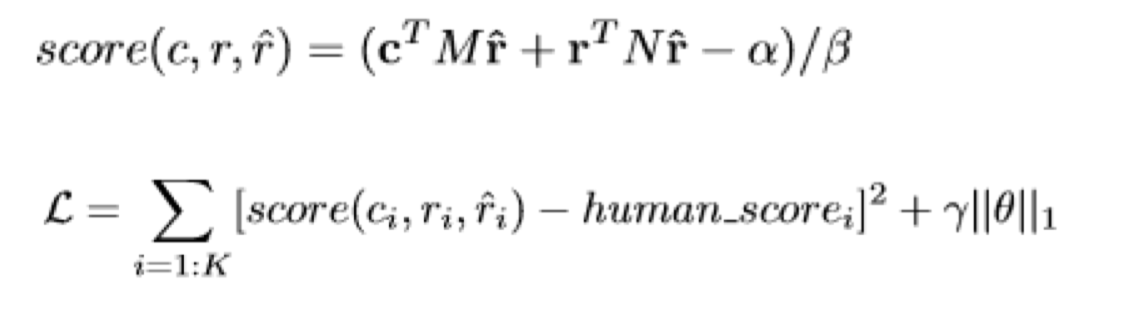
Application
讲一个生成式模型的具体应用,然而用预先定义好的模板库对生成的 response 做了一个限制。具体任务是如何对邮件进行自动回复。来自 Smart reply, automated response suggestion in email
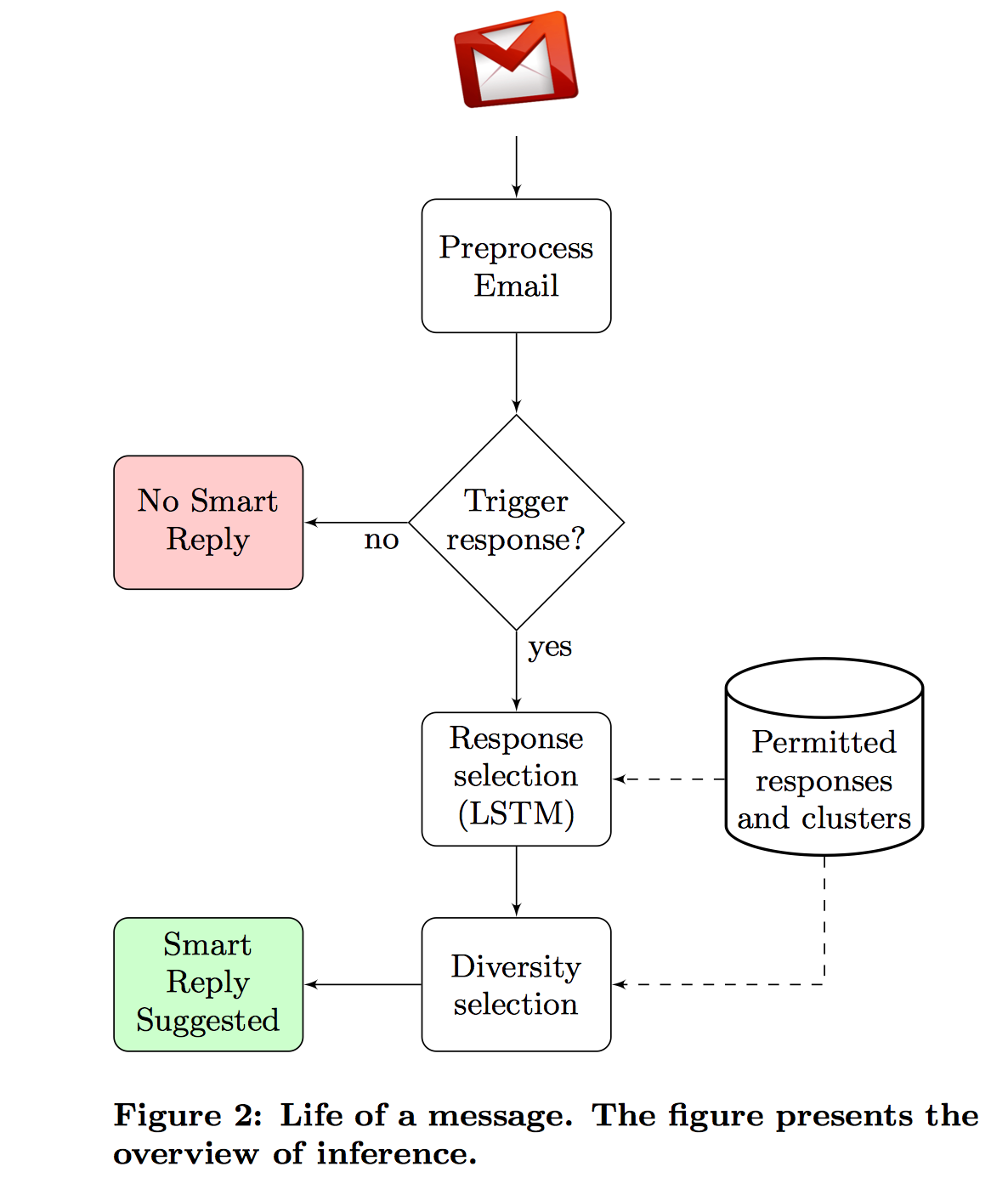
达到的目标是收到一封邮件,系统发现这个邮件适合 Smart Reply,就会自动推荐 3 个回复语句给用户选择。
框架面临的几个挑战是
- Response quality
怎么保证生成的回复的质量,如果质量不高,根本没有推荐的必要 - Utility
怎样选择推荐的回复,能最大化用户选中的概率 - Scalability
怎样提高效率,大规模处理 - Privacy
在开发系统的过程中怎么保护隐私,加密
如何应对上面的挑战,也是文章的亮点
- Response selection
对应 Scalability 问题
将模板库里的句子组织成一个 trie,从左到右用 beam search 的方法进行每次遍历,只保留在 trie 中出现的 hypothese,这样对每个 response candidate 评分的复杂度就由 O(Rl) 降到了 O(bl),R 是模板库的大小,l 是最长回复的长度,b 是 beam size - Response set generation
对应 Response quality, Scalability, 以及 Utility 问题
生成一个带 intent 标记的模板库,回复只从这个模板库里产生 - Diversity
对应 Utility 问题
去掉 generic 的回复,兼顾正面、负面回复,在得分最高的回复中,每个 intent 只选择一个回复 - Triggering model
对应 Utility 问题
Binary 分类器判断是否要 trigger 自动回复,不需要回复的,不适合短回复的
具体过程是,来一封邮件,首先看是否 trigger Smart Reply(采用一个 feedforward neural network),如果是,就跑一遍 LSTM,生成候选的 n 个 response。
特征方面,预处理后的邮件采取的特征有 unigram, bigram,发件方是否在收件方的地址簿里,是否在收件方的社交网络里,收件方是否在过去回复过发件方等等。稀疏特征类型(如 unigram, bigram)的 embedding 是单独训练的,然后每个稀疏类型特征下的 embedding 进行加总,再和 dense feature(如数值、布尔类型的特征)拼接作为输入。
重点看一下模板库的生成。
Response set generation
模板库的存在可以限制产生的 response 的范围,提高 response 的质量以及选择回复的速度。另外,这里模板库里的句子都有一个 intent 标记,而标记了 intent 类别的回复模板库可以增加回复的 diversity。
产生模板库用了 Expander graph learning approach,是一种半监督的方法。
搜集邮件数据后用传统 nlp 方法进行预处理,包括
- 去掉非英语的样本
- Tokenization
- 将内容分割成句子为单位
- 使用特殊符号替换不常用的单词(e.g. 人名,url,邮件地址)
- 去掉引用和转发的邮件部分
- 去掉问候和致敬部分
处理好的数据中只选择短的、最常出现的、匿名的回复。
首先利用 dependency parser 将类似的句子如 “Thanks for your kind update”,“Thank you for updating!”, , “Thanks for the status update” 等转换为 canonical 形式,即 “Thanks for the update.”
然后进行做语义聚类,每个 cluster 对应一个意图(intent).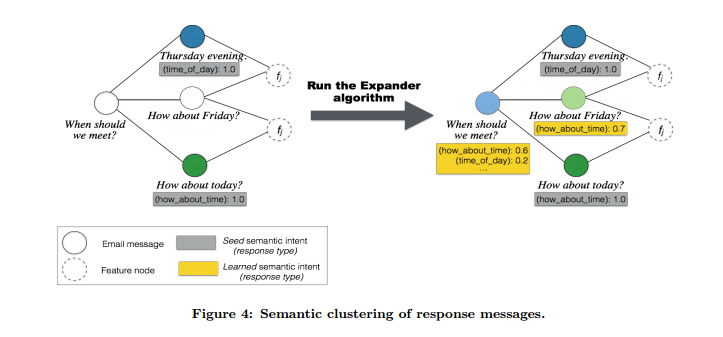
过程:
- 初始化: 标记~100个类别(cluster),每个类别~3个人工选择的样本
- 使用 (original, response), (response1, response2, feature) 对模板库里的样本建立关系
- 使用 Expander 算法给未标记的句子打标记
- 对于新的类别的发现,Iteration:
Inference: 用 label propagation 算法迭代 5 次推测未标记样本的 cluster 类别
Update: 从图中剩下的未标记的样本中随机 sample 100 个作为潜在的新类别,用 canonicalized representation 来标记
重新运行 label propagation 直到收敛(不再发现新的类别,或者每个类的成员不再变化) - 最后进行 Validation: 提取每个 cluster 的 top-k 个回复样本,人工验证

