回国后参加的第一场大规模的人工智能峰会,感觉收获还是很多的,对部分之前学过的东西做了一遍梳理,对当前工业界的发展现状有了一定了解,对学术界的最新进展有了些体会,最后还结识了一批志同道合的朋友,值回票价。这一篇作为峰会的笔记,记录一些我认为重要的东西,有些零散,参加的场次有限,看官们见谅~
AI 发展前沿
这一部分各位演讲嘉宾从宏观角度概括了下 AI 的发展现状。
AI 的典型任务和应用
潘云鹤——中国工程院院士,国务院学位委员会委员、中国科学技术协会顾问、中国图象图形学学会名誉理事长、中国计算机学会理事、中国人工智能学会副理事长。中国智能CAD领域的开拓者,创造性地将人工智能引入CAD技术。
主要介绍了 AI 行业的一些基本情况,像人工智能的典型任务、应用、重点方向之类,毕竟是刚开场的演讲,听的比较仔细。
人工智能应用的 7 个基本领域:
- 机器定理证明(逻辑和推理) — 仿解题者
主要是研究计算机进行逻辑推理 - 机器翻译(自然语言理解) — 仿译者
研究计算机自然语言理解 - 专家系统(问题求解和知识表达) — 仿专家(医生,维修者)
研究问题求解和知识表达 - 博弈(树搜索) — 仿弈者
最早的时候研究搜索,后来逐渐转化为神经网络 - 模式识别(多媒体认知) — 仿认知者
主要用于视觉、听觉或者各种各样媒体的认知 - 学习(神经网络) — 仿初学者
主要是研究神经网络 - 机器人和智能控制(感知和控制) — 仿生物动作
主要是研究和模拟人的感知和控制
形成了符号学派、连接学派、行为学派。
AI 从萌芽到现在的蓬勃发展期间出现了三次低谷,得到的教训大致是驱动 AI 的发展主要是靠创新、软件和知识,而非硬件,知识不能靠专家手工表达,要靠从环境中自动学习
一些新的技术已经初露端倪,表现在近几年 AI 技术的前沿中,主要有
- 大数据智能
DeepMind 已为谷歌挣钱,提高了谷歌 15% 的用电效率 - 基于网络的群体智能
群智计算按难易程度分为三种类型:实现任务分配的众包模式(Crowd-sourcing),较复杂、支持工作流模式的群体智能(Complex workflows),以及最复杂的协同求解问题的生态系统模式(Problem solving ecosystem)
大规模个体通过互联网参与和交互,可以表现出超乎寻常的智慧能力,是解决开放复杂问题的新途径,成功的如 AppStore,Wiki 百科等 - 跨媒体推理
在语言、视觉、图形和听觉之间语义贯通,是实现联想、推理、概括等智能的重要关键 无人系统
无人系统迅猛发展的速度远快于机器人,因为类人和类动物的机器人,往往不如机械进行智能化和自主化升级来的高效
如 (海康)智能分拣机器人,泊车机器人
AI 的基础和目标: 模拟人的智能 => 人机融合 => 群体智能
直接上图了
The Rise of AI And The Challenges of Human-Aware AI Systems
Subbarao Kambhampati——AAAI主席,亚利桑拿州立大学教授,同时也在很多的国际机构任职,主要研究自动化的决策机制,特别是在人工感知的人工智能领域。
同样讲了 AI 进展,不过划分方式略有不同。
提供了一个很有意思的视角, AI 系统的发展过程和人的学习过程是截然相反的。为什么呢?因为在有 conscious theories 的基础上编程更容易,毕竟 cognitive/reasoning intelligence 一直在发展嘛,还因为我们并没有特别意识到/了解 perceptual intelligence,为什么当今的 AI 能够走入千家万户的视野呢?正是因为 perceptual abilities 让 AI 不再是瞎的聋的,现在的 AI 可以更加的智能,可以存在在各种载体之上,如智能手机,智能音箱,汽车等等。
教授还指出了几个研究方向:从小数据中学习、机器的常识、不完整性和交互。
模式识别研究回顾与展望
谭铁牛——中国科学院院士、英国皇家工程院外籍院士、发展中国家科学院院士、巴西科学院外籍院士,发表专著11部、文章500多篇,还有100多项发明。获得了一系列的国家级的奖,现在是中国图象图形学会理事长、中国人工智能学会副理事长。
主要讲了模式识别的 基本概念/发展现状/研究方向。深深的觉得 ppt 做的实在很棒,讲的也很棒,感觉最棒的!直接上图!
模式识别的现状:
- 面向特定任务的模式识别已经取得突破性进展,有的性能已可与人类媲美;
- 统计与机遇神经网络的模式识别目前占主导地位,深度学习开创了新局面;
- 通用模式识别系统依然任重道远;
- 鲁棒性、自适应性和可泛化性是进一步发展的三大瓶颈。
现有模式识别的局限性:
- 鲁棒性
容易收到对抗样本的攻击
如 CV 中的局部形变/旋转变化/光照变化/遮挡/背景凌乱/多样性/尺度变化 - 自适应性差
不能自适应开放环境下数据分布的快速变化 - 可解释性差
人在判别过程中可以轻易使用具有逻辑关系的规则;机器特别是深度学习常作为黑箱模型,无法为高风险应用提供具有说服力的决策
在人工智能非常火爆的时候,模式识别领域有如下值得关注的研究方向:
- 从神经生物学领域获得启发的模式识别
神经元(类型、发放特性、突触可塑性)/神经回路(前向、侧向、后向连接)/功能区域(多任务协同、注意、记忆机制)/学习机制(人的学习特性和学习过程)
学习过程:发育学习、强化学习
学习方法:迁移学习、知识学习
学习效果:生成学习、概念学习(e.g., Bayesian Program Learning) - 面向大规模多源异构数据的鲁棒特征表达
考虑如何在跨景跨媒、多源异质的视觉大数据中找到具有较好泛化性和不变性的表达
e.g., 定序测量特征(Ordinal Measure) - 结构与统计相结合的模式识别新理论
- 数据与知识相结合的模式识别
- 以互联网为中心的模式识别
AI 学术前沿
这一场主要分析了学术界的各位的最新研究进展
Smart Robotic Systems that Work in Real Outdoor Environments
金出武雄——机器人领域的鼻祖级专家,卡耐基梅隆大学的创始人,同时也是非常著名的荣誉教授,主要研究机器人工、机器人学,享誉全世界的指路者。
虽然是自家学校的,还是木有认真听。开头主要讲了一个例子,在车上加一个 smart headlight,使得雨滴在图片里面的成像变得很淡,可以毫无障碍在雨雪天的夜晚出行, 因为他一开始就在讲汽车灯光在下雨天各种反射怎么怎么样……然后我就……就没兴趣了TAT……
A society of AI Agents 群体智能的社会
汪军, 伦敦大学学院(UCL)计算机系教授、互联网科学与大数据分析专业主任。主要研究智能信息系统,主要包括数据挖掘,计算广告学,推荐系统,机器学习,强化学习,生成模型等等。他发表了100多篇学术论文,多次获得最佳论文奖。是国际公认的计算广告学和智能推荐系统专家。
讲多智能体怎样竞争怎样协作怎样通讯。从多智体群体的特征切入,介绍多智体的强化学习特性。同一环境下,不同的智体既可以单独处理各自的任务,又可以联合在一起处理优化一个主要的目标方程(一般是长期的 reward 方程)。强化学习的优点就是在没有足够训练数据时,系统会和环境进行交互,得到反馈信息,交互过程中不断学习,在应用上比较灵活
Multi-agent reinforcement learning(MARL) 的应用有互联网广告的机器招标(Machine Bidding in Online Advertising),通过对投放广告后的用户的反馈的不断学习,就可以帮助企业精准找到目标用户。再如 AI 玩星际游戏(AI plays StarCraft)等,主要考虑的是智体的通讯问题,多个智体之间怎么合作,达到双向联通。
其他的应用比如宜家的商场设计,需要模拟人的行为流向,同时让环境跟着用户的变化而变化,把路径安排最优,来优化用户的停留时长(stay)和购买金额(purchase) ,再比如迷宫的设计,一方面给定一个环境,让智体通过强化学习找到最优的策略走出来,另一方面是当智体的智能水平不再提高时,就可以来优化环境,使它更难出去。
多智能强化学习的研究仍然处于非常初步的阶段,主要有两个问题
- Problem1: current research is limited to only less than 20 agents
许多现实场景中的多智体数量可以达到百万、甚至千万级,比如 uber 的场合怎么办?共享单车怎么办? - Problem2: the environment is assumed to be given and not designable
不是去学环境的设计,而是让人工智能更加适应环境,而很多情况下,很多环境也需要有适应的过程,比如说宜家,强化学习的环境,根据用户的变化,变化环境。用随机 agents 模拟人在店铺走的情况,收集人力图,反馈到铺面设计,来最大用户停留时间/用户消费
怎么处理百万级的 agent,一种方法是从自然界中找灵感,可以学习生态学/生物学的 self-organisation(自组织)理论,当一些小的智体遵循这个规则的时候,就会体现一个种群的特质。这些模型可以用宏观的事情解决宏观的问题,但是缺少一种微观的方法去观察这个世界。老虎和羊的模型 Lotka-Volterra model the dynamics of the artificial population 描述了相互竞争的两个种群数量之间的动态关系。汪军教授在此模型上做了一个创新,提出了老虎-羊-兔子模型(Tiger-sheep-rabbit model),给智体强化学习能力以后,就和 LV 模型中的猞猁抓兔子的动态显现十分相似。当智体之间联合一起优化某一个目标或单独优化自己的目标,作为一个群体,他们就有了内在的规律。如果找到这些规律,对开发智体模型是非常有帮助的。
计算机视觉专场
Video Content 3C: Creation, Curation, Consumption
梅涛,微软亚洲研究院资深研究员。
CV understanding 问题分为几个层次(or 不同粒度):
从图像到视频的变换,实际是从二维到三维的变换,除了要理解每一帧的图片的 object,还要理解帧/物体在 cross, multiple-frame的动态运动。
视频内容的生命周期大致可以分为三个部分,即视频的创作(creation)、处理(curation)和消费(consumption)。

Creation
先来看一下视频是怎么产生的。首先把 Video 切成一个个的 shots(镜头/段落),每个镜头 group(组合) 成一个 story(scene),每一个镜头还可以细分成 sub-shots,每个 sub-shot 可以用 key-frame 来表示。通过这种分层的结构可以把 video 这样一个非线性的东西分成一个 structure data,这就是做 video summarization 的前提。
Video summarization 分两种,static summary 和 dynamic summary。
- static summary: automatic selection of representative video keyframes(e.g., 5 keyframes)
主要是选择具有高度代表性的 keyframe 来表示视频,一个 5 分钟的 video 给你 5 个 keyframe 你就知道这个视频讲了什么 - dynamic summary: automatic generation of a short clip for fast preview(e.g., 30 second)
8 分钟的 video 生成 30 秒的 highlight,概括 video 的所有内容。spots video 知道哪些 segment 是最 hightlight 最精彩的,你最应该看哪部分

Video Creation 的涉及的技术还有 stabilization and photography,怎么把拍的抖动的 video 变得平稳,怎么分辨 video 中的物体哪些是静止的哪些是动态的,然后产生 animation;另外和文字结合的技术/应用如 video generation,给出文字,来产生一个 video,像给一个动作,video 能展示这个动作。
Curation
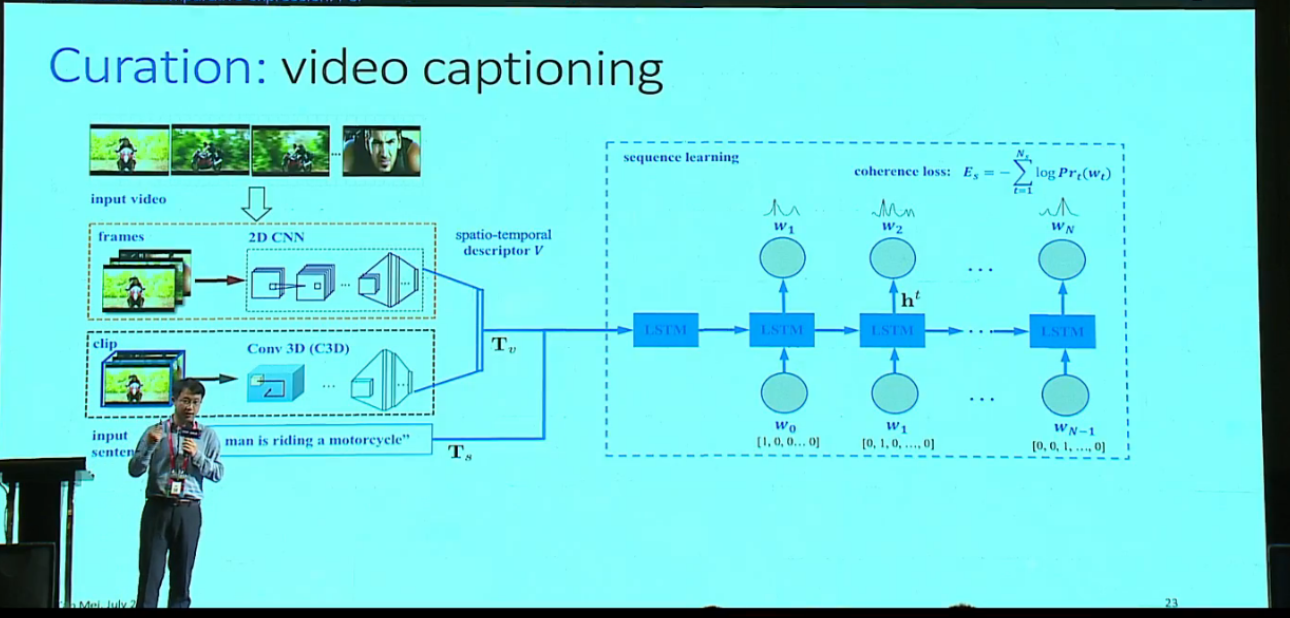

Curation 涉及的技术还有 pose estimation from RGB video,应用比如说智能健身教练,通过把动作分解来告诉你哪一个动作是不准确的;还有在 video captioning 方面的应用,可以把视频描述做的更生动,比如说原来只能识别一群人(a group of people),加上 pose estimation 可以识别一群人在跳舞(a group of people are dancing)。还有auto-commenting,给视频自动评论,把原有的 caption 变成有人的情感对话的 comments,比如说棒球比赛的动图,可以产生

Video caption 的经典方法是2D/3D CNN 学一个 video 的表达,然后做一个 embedding,把 embedding 的结果加上 text embedding 放到 rnn 去学。如果加上一个 relevant loss,结果还会与内容相关
Consumption
最后一个环节是 Video Consumption,应用像 video instagram,可以给 video 加上 style,或者说滤镜,变成 stylist video;也可以做 style transfer,比如说把油画的 style transfer 到自拍/风景照中;还有的应用像 segmentation,把人抠出来放到另一个场景里,把异地情侣放到一个房间里聊天;更难一点的还可以做 storytelling,把很多视频中的图像组合成一个吸引人的故事讲给观众听;另外还有 video advertising,来分析广告应该放什么位置,什么时间段选什么广告(是不是和插入点信息相关),比如说广告和内容可以无缝衔接,也可以在故事高潮的时候/最 boring 的时候放广告。视频广告主要有两种度量方式,一个是 discontinuity,来衡量一个广告插入点的故事情节是否连续;另一个是 attractiveness,来衡量一段原始视频的内容是否精彩。这两者的权衡同事也就是广告商(advertiser)或用户(viewer)需求的权衡。
产业落地和产业化路径
下一个是演讲者是中山大学教授、商汤科技执行研发总监林倞老师,又是母校,主题是 深度驱动的人工智能:从学术创新到产业落地,主要还是介绍了下商汤现在的主要业务。再下一个演讲者是魏京京,图麟科技 CEO,主题是 计算机视觉的产业化路径,也就不多说了。
X 数据驱动的 Seeta 视觉引擎与平台
山世光,中科院计算所研究员、博导,基金委优青,CCF青年科学奖获得者,现任中科院智能信息处理重点实验室常务副主任,中科视拓创始人、董事长兼CTO,任IEEE,TIP,CVIU, PRL,Neurocomputing,FCS等国际学术刊物的编委。
主要记录几个点,原文可以看 中科视拓CTO山世光:如何用X数据驱动AI成长 | CCF-GAIR 2017&version=12020610&nettype=WIFI&fontScale=100&pass_ticket=fYv8LK1dmtHud6qxDzyk0NQoTcNdpkYbWuD9vGD4pepNxlPLVOKnmpPFU3ig4ZlD)
增强学习适合:可以自动判断对错的领域
例如:棋类、游戏类
视觉、听觉、理解、情感,通通不太行
深度学习适合:好数据肥沃、可以归纳学习的领域
- 数据采集、获取、标注便利的领域,例如视觉,语音,互联网+行业
- 需要演绎推理的领域非常困难,理解需要演绎和引申,没有太多可作为的地方
X 数据有五个含义:
- 大数据
大数据驱动的视觉引擎的设计; - 小数据
在很多场景下,我们获得智能的能力并不是依赖于大量的数据学习,反而是一些小数据,所以要考虑的十四,怎样在小数据的情况下使得我们的算法也能够有效果。通常的思路自然是迁移学习,最简单的是做 finetune 模型,把一个已经训练好的模型,再用小量的数据做调整和优化,使得它适应这些小数据所代表的应用场景。另一个思路是多模态的数据,实现跨模态的比对和融合利用; - 脏数据
很好理解了,现在的数据都有大量的噪声,要雇人在大量的数据中把它们标注出来太不容易了,干脆就基于有噪声的数据实现机器学习。所以山世光等人在今年提出具有“自纠错学习”能力的深度学习方法,在深度学习的过程中,一边去学习算法,一边去估计哪些样本的标签可能是错误的,把一些可能错误的标签修正过来,从而得到更好的算法。
这里的脏可能还有另一层含义,比如说图像识别中有遮挡的情况,山世光等人也提出了一个算法,能够把面部的遮挡部分、脏的部分补出来,补出来之后再去实现感知。把这两个过程迭代起来,形成联合的学习,这个工作发表在去年的 CVPR 上面,取得了非常不错的效果。 - 无监督数据
比如说特定的物体没有标注数据,怎样利用没有标签的数据来训练模型。解决方法如 Bi-shifting 深度模型,实现从源域到无监督目标域到知识迁移。(M.Kan, et al, ICCV2015) - 增广数据
通过对已有少量数据进行修改的方式,来生成大量数据。有两类方法,一种是模型方法,比如说 3D 重建,另一种是 GAN 方法。




AI 未来发展需要注意的三个问题:
- 鲁棒性
鲁棒性可能是 AI 和视觉智能一个最致命的问题 - 多模态数据协同
对于人来说,除了眼睛之外,我们有很多其它信息来对我们的智力发育提供帮助,包括语音、姿态、动作、以及背后有大量的知识库作支撑。因此,人本身是需要一个多模态系统协同工作的鲁棒AI,这带给我们一个思路,AI的成长和发育也需要多模态 - 基于小样本的自主学习
AI 发育的非常重要的一点,就是如何基于小数据甚至是 0 数据完成智能的发育和后天的学习。比如说我跟大家描述一下某个人长成什么样子,你并没有见过这个人,你并没有见过这个人的照片,我们称为0数据,你如何能够识别这个人,是对AI的一个挑战。类似这样的应用场景,将来会有非常多的研究空间。
圆桌对话
五位圆桌嘉宾包括:中科院计算所研究员、中科视拓董事长兼 CTO 山世光、阅面科技 CEO 赵京雷、图麟科技 CEO 魏京京、瑞为智能 CEO 詹东晖以及臻识科技 CEO 任鹏。
感觉最有意义的一个问题是:你觉得人工智能技术在落地过程中最大的难点是什么。几位嘉宾一致同意说是闭环。最核心的是市场需求和当前技术达到的闭环,产品结果和客户需求有差距,要怎么迭代。做产品的时候有很多取舍的东西,要去平衡你的功能、性能,满足客户的指标、期望,最后在产品设计和成本相关的这些方面,其实一个核心就是闭环。创业过程中最关键的不是你有什么技术,而是你把已有的技术跟他的痛点结合,这个问题不是技术的问题,基本上就是商业问题,需要付出的努力不是做技术的来做的,而是你要接地气,围着客户做讨论、设计和服务,让他慢慢接受你,这是很痛苦的,也是做技术创业需要转换的地方。我们所谓的技术完美,当然我们希望「快、准、稳」。快是随便找一个很烂的芯片就可以做;准是什么情况下都能工作;稳是不会出现差错,这样落地和闭环就不会出现难题了,但是我们现在真的做不到。比如刚才说的万分之一,很多时候是达不到的,在这个阶段最难的是怎么去找到客户的需求和技术的边界能够结合的应用,再配合上其他的一些条件,能够满足用户的需求。刚才几位说得都对,技术不完美还是一个很大的障碍。
CV+圆桌对话:算法不是唯一考量,创业公司的商业闭环才是最大难点
机器学习专场
AI in games
田渊栋,Facebook 人工智能研究院研究员
游戏平台,作为虚拟环境,是非常好的一个数据来源。因为量大,无穷尽,获取速度快,有科学的平台可以提供重复科研的环境。游戏数据的特点:
- infinite supply of fully labeled data
- controllable and replicable
- low cost per sample
- faster than real-time
- less safety and ethical concerns
- complicated dynamics with simple rules
像围棋,非常简单的规则可以得到一个很有意思的过程,可以从过程中抽取一些概念,得到一些人类推理的知识。然而现实生活中规则太多,不一定是个很好的研究开端。
游戏平台作为数据做研究也存在一些问题:
- Algorithm is slow and data-inefficient
人玩游戏玩几盘就好了,计算机要大量的数据,虽然道最后计算机可以玩的很好 - require a lot of resources
研究限于比较大的公司 - abstract game to real-world
游戏能不能扩展到现实世界是个很大的问题
让游戏更真实 => 现在的游戏越来越真实,和现实生活非常接近 - hard to benchmark the progress
显而易见,解决方案是:
=> better algorithm/system
=> better environment
这两个都是目前游戏 AI 的研究方向,还有 domain transfer,也是一个研究方向。
Even with a super-super computer, it is not possible to search the entire space.
很多人以为机器能够搜索游戏的所有可能,所以能胜过人类,其实这是一个误解。我们能做的是有限搜索,从当前局面出发,哪一步是最好的,extensive search => evaluation
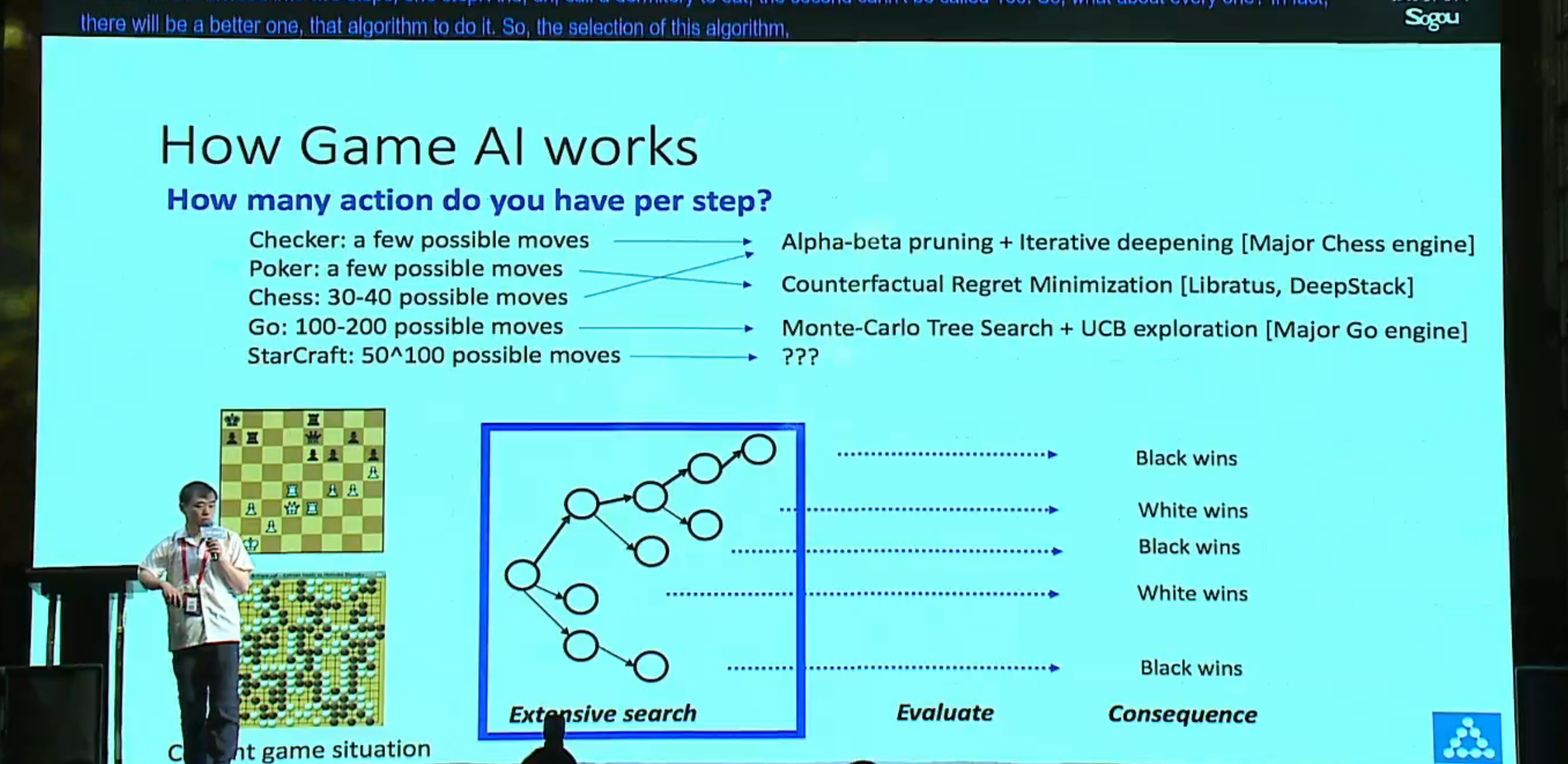
星际这样的游戏,可能的步数是指数级的,怎么做还是个开放性的问题
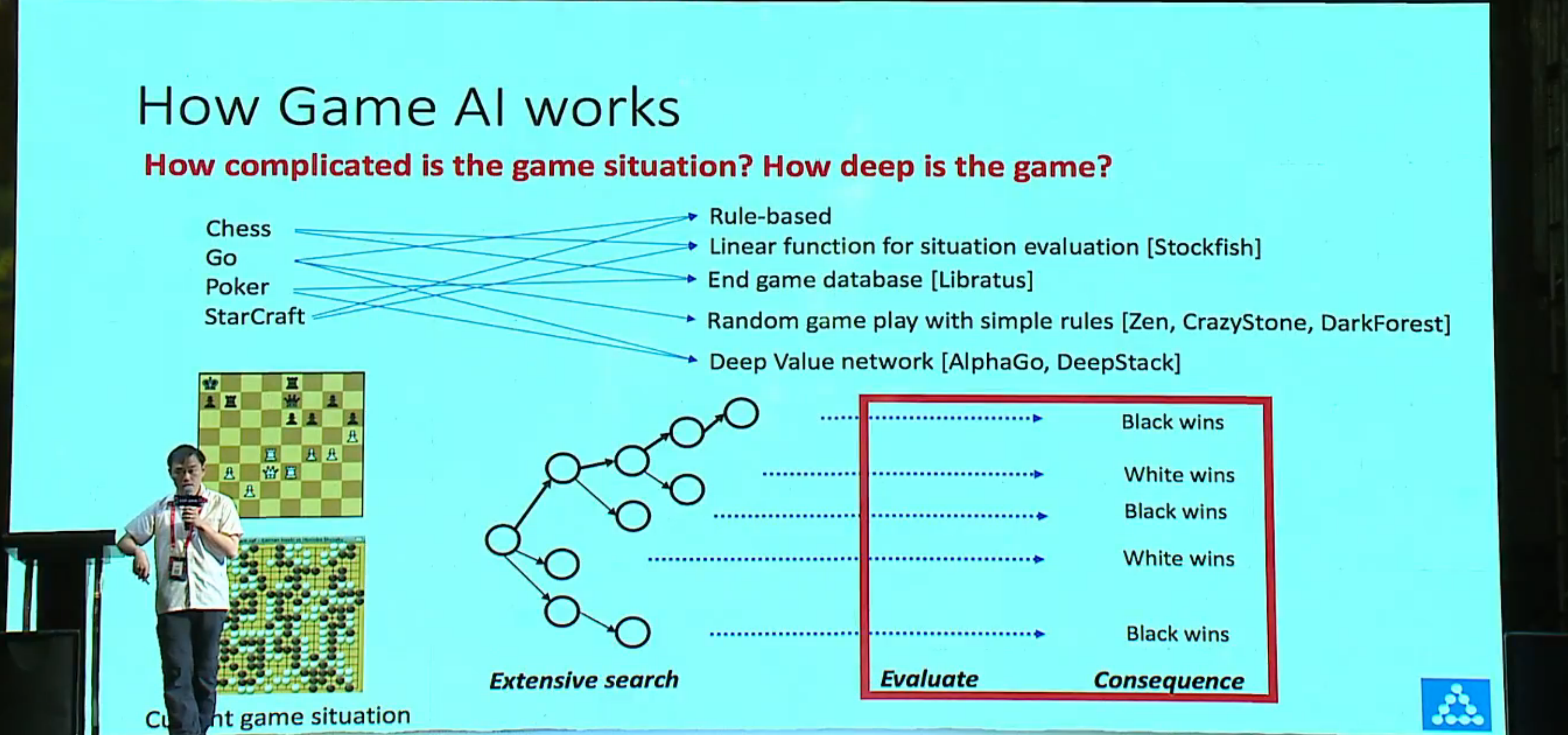
围棋用深度学习的方法 CNN 学出评估函数。怎么估计下一步怎么走?怎么评估?
How to model policy/value function?
traditional approach
- Many manual steps
- Conflicting parameters, not scalable
有些时候规则是冲突的,大师没办法直观的告诉 ai 什么时候用哪条规则,有的时候是看直觉的,ai 没法学 - require strong domain knowledge
deep learning
- End-to-end training
lots of data, less tuning - minimal domain knowledge
amazing performance
Case study: AlphaGo 依靠 Monte Carlo Tree Search, aggregate win rates, and search towards the good nodes. 从根节点一路找最大概率走到叶节点,这样的好处是如果发现有些招数很糟糕,那么走了两步就不会继续往下走了,如果发现有些招数不错,可能会一路走下去,走个五六十层,这样可能会发现一些很有意思的招数。
主要策略思想
Policy network: 根据大量人类棋谱学出来
Value network: 网络自己学,把状态中某个步骤拿出来,给每个状态提供一个标定,拿出来训练
future work
- richer game scenarios
multiple base(expand? Rush? Defending?)
more complicated units 精细控制每个决定,现在智能控制9个 - more realistic action space
Assign one action per unit - model-based reinforcement learning
MCTS with perfect information and perfect dynamics also achieves ~70%
现在游戏都是慢慢摸索的,然而对复杂的游戏需要对游戏有大致估计 - self-play(Trained AI versus Trained AI)
自对弈
互联网数据下的模型探索
盖坤博士,阿里,P9,阿里妈妈精准展示广告投放
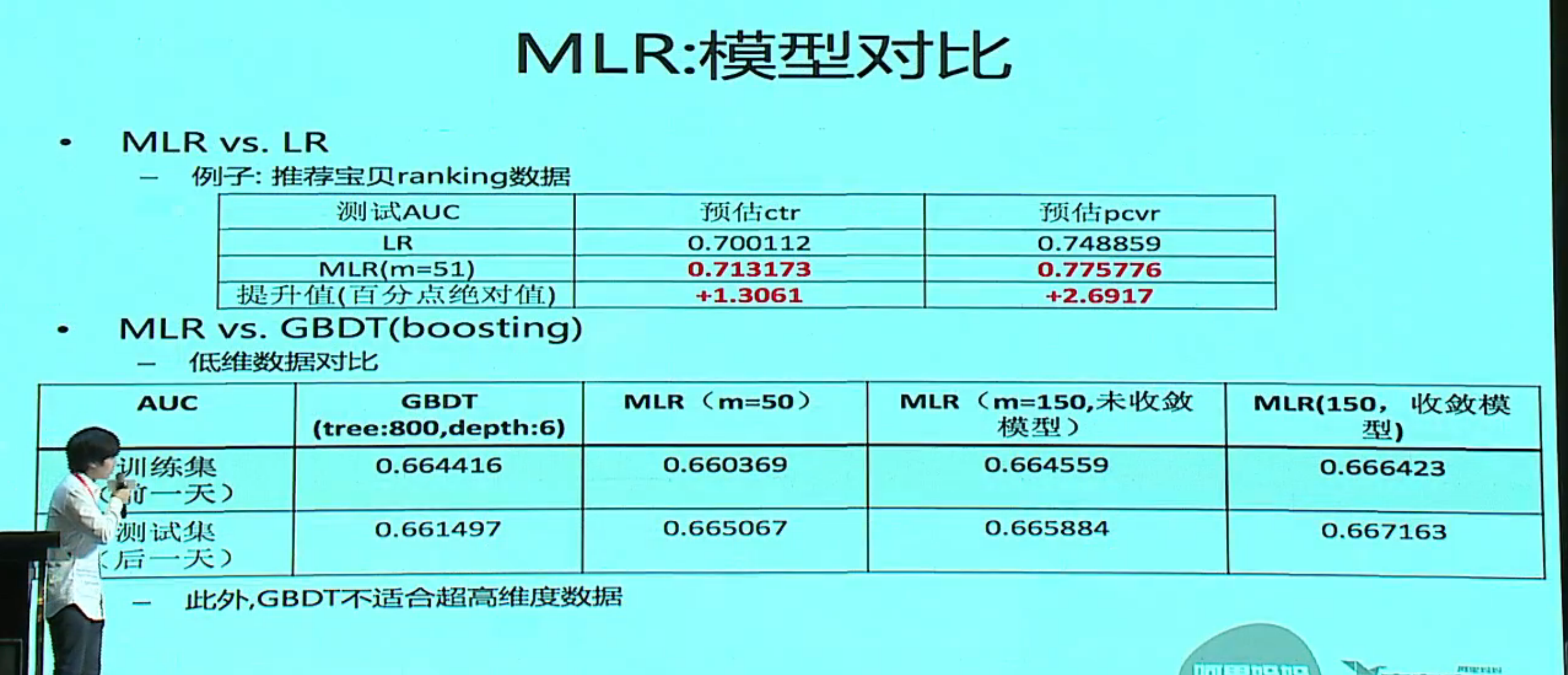
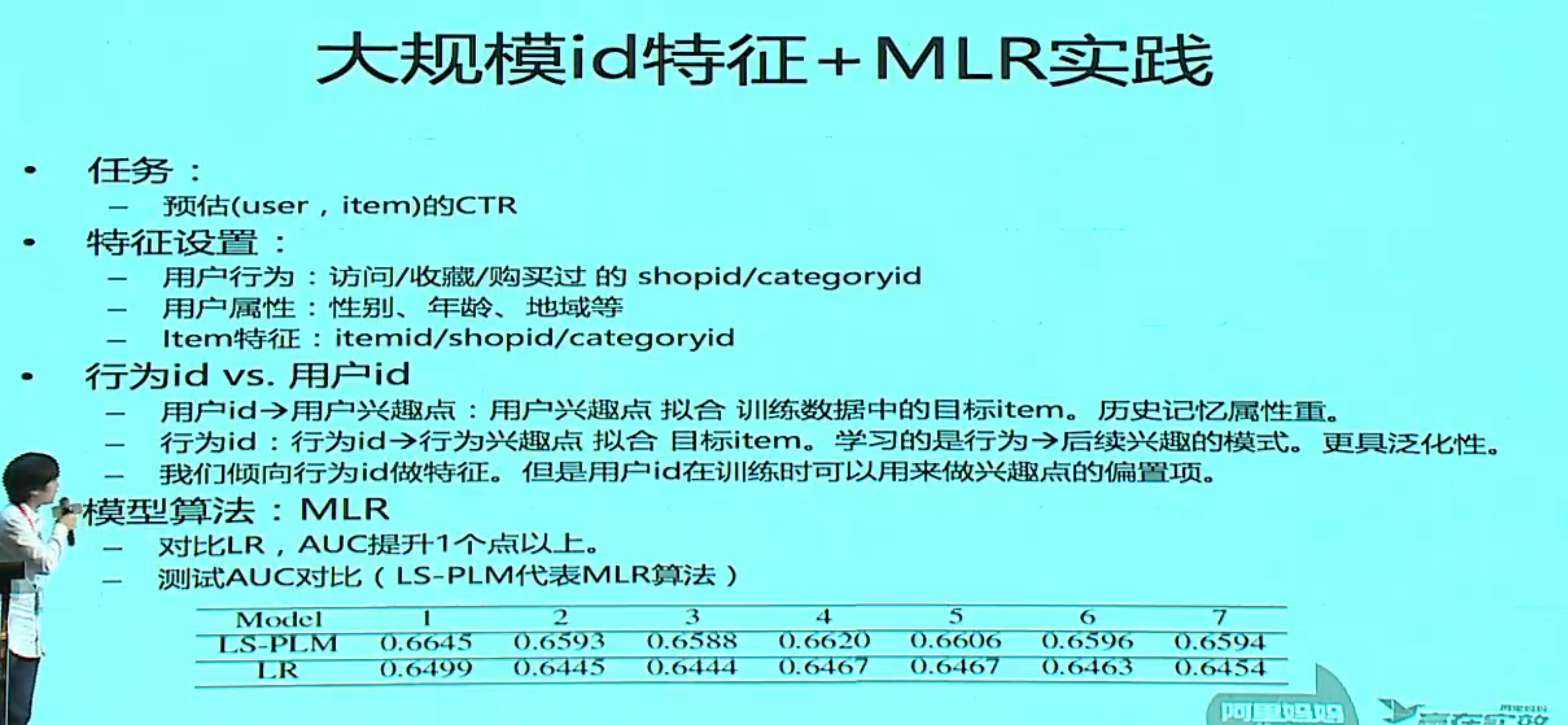
Learning Piece-wise Linear Models from Large Scale Data for Ad Click Prediction
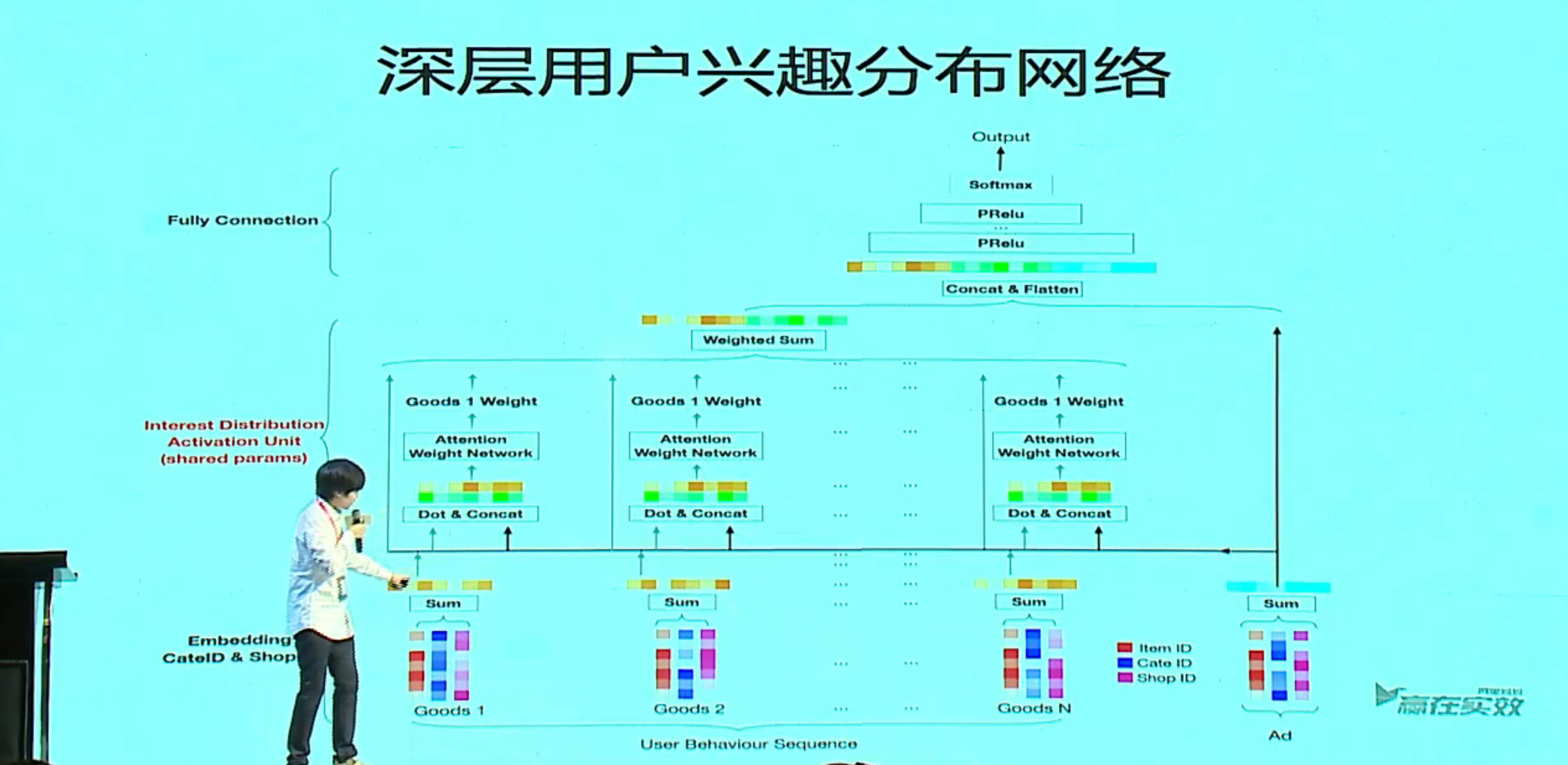
Deep Interest Network for Click-Through Rate Prediction
互联网数据和经典模型
互联网数据业界经典的处理方法,典型问题:CTR 预估(点击率预估)
数据特点
- 样本量大 百亿样本
- 特征维度大 无损表示
id 特征,原始特征,稀疏的鉴别式特征,轻松超十亿级
原始特征,用户特征+物料特征
加上交叉特征,笛卡尔积之类的,轻松上千亿 - 稀疏数据
经典做法
- 简单线性模型 Logistic Regression
线性模型+sigmoid一个非线性变换,变成一个概率模式 - 稀疏正则 L1-Norm 特征筛选
压制不太重要的特征 - 处理非线性:人工特征工程
LR 是线性模型,能力有限,要挖掘非线性特征,只能做人工特征,笛卡尔积,做交叉,做种种特征
问题
- 人工能力有限,很难对非线性模式挖掘完全重复
- 依赖人力和领域经验,方法推广到其他问题的代价大:不够智能
已有的非线性模型
- Kernel 方法(kernel svm)
复杂度太高,一般来说光存储 kernel 矩阵就是数据量平方级 - Tree base 方法(如 GBDT)
在低维强特征上表现非常好,但在大规模弱特征上(如 id 特征)表现不行
实际上是树的缺点,假如说是 user id, item id 两个信息,建树会带来一个灾难,每个叶子节点在一维特征上做 split,意味着来判断某个特征是不是 id,跟到叶子路径:if(user id == useri && item id == itemj) 条件判断,变成了根到叶子的组合判断,就变成了一个记忆,判断为记忆历史行为,缺乏推广性 - 矩阵分解(Topic Model, LDA 等)
适用于两种 id 的情况,不适合多种 id 输入 - Factorization machines
只拟合有限次关系(二次关系)
无法拟合其他非线性关系:例如三种特征的交叉,值的高阶变换等
我们需要的特性
- 足够强的非线性拟合能力
- 良好的泛化能力
- 规模化能力
分片线性模型和学习算法 MLR
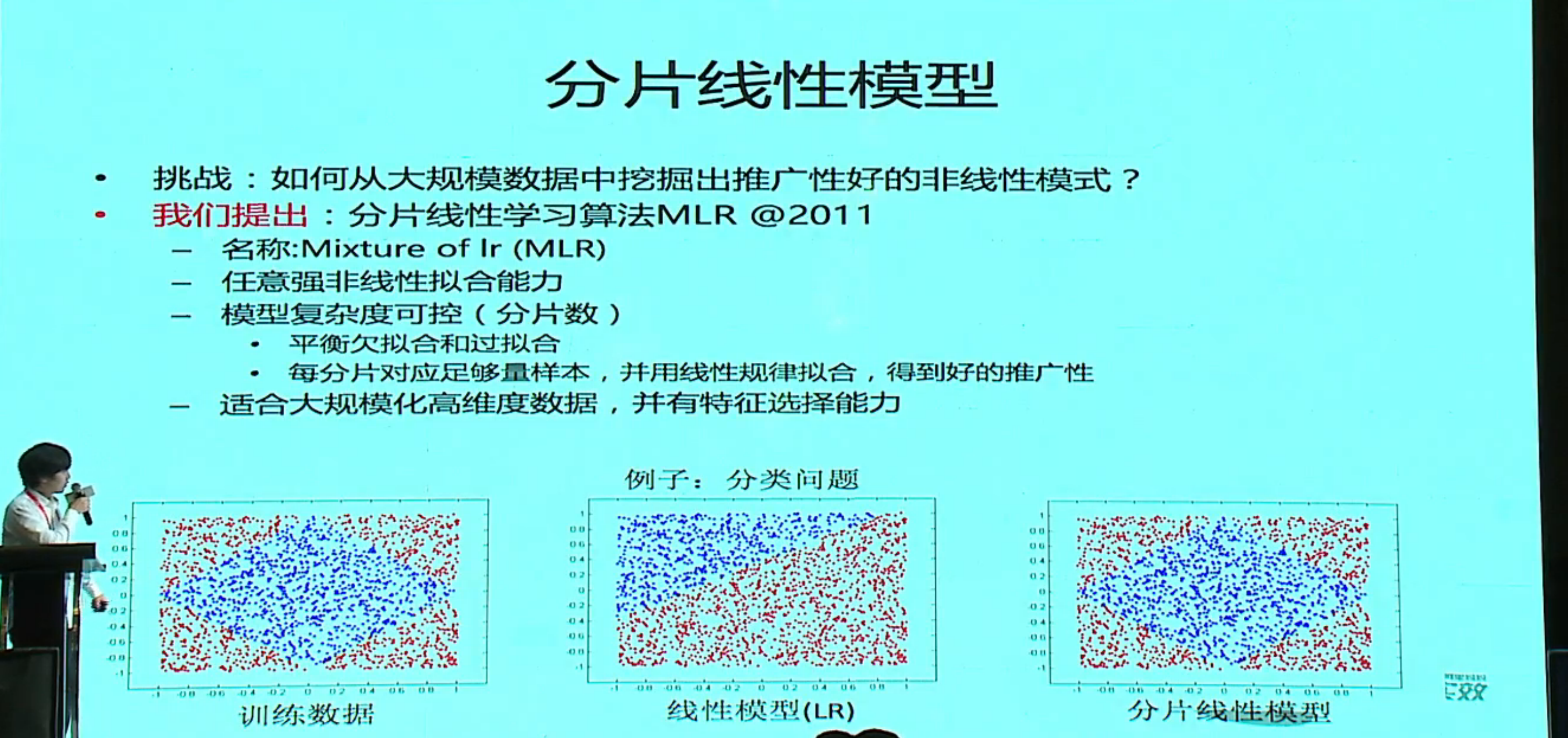
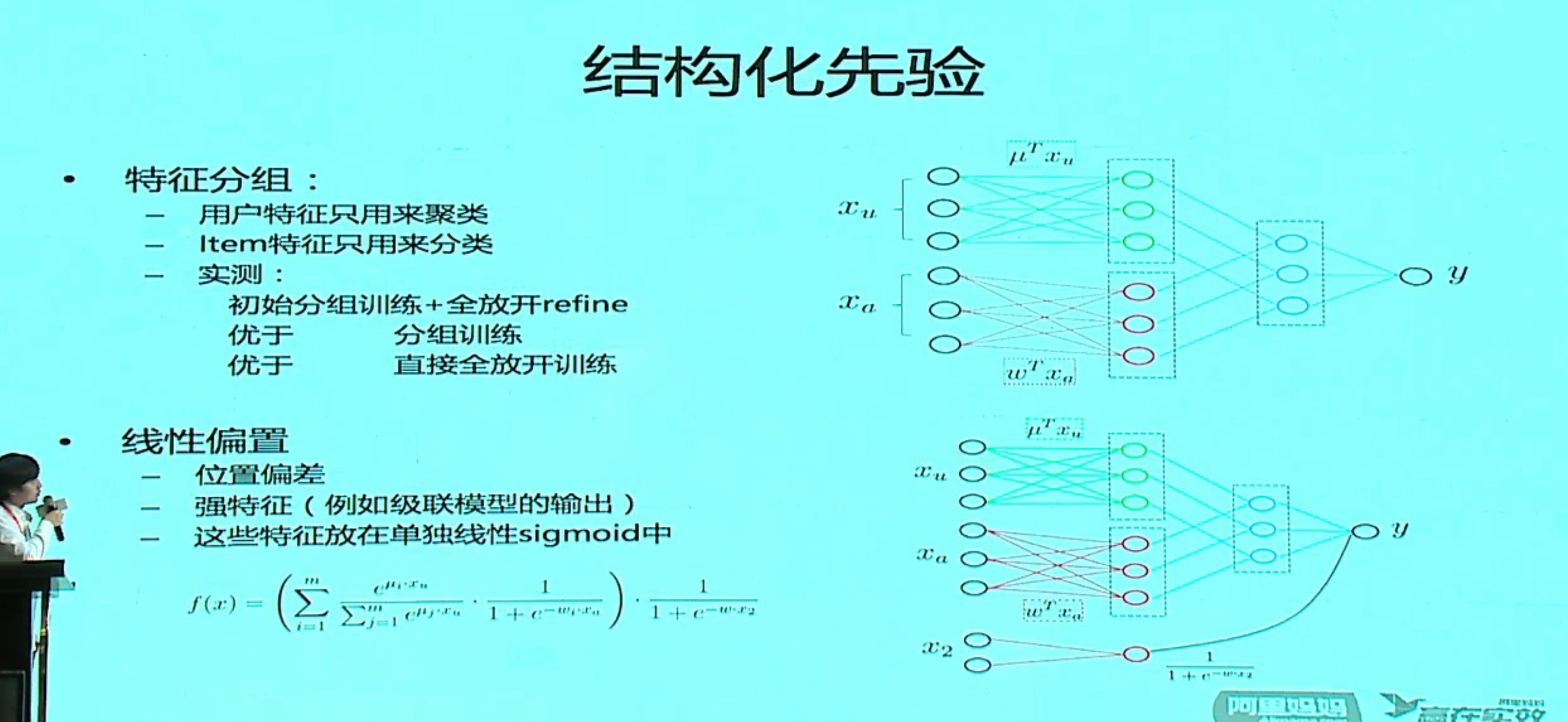
分片数为 1 就是一个线性模型,分片数过多会过拟合,实际过程中是用一个搜索的方法来确定分片数。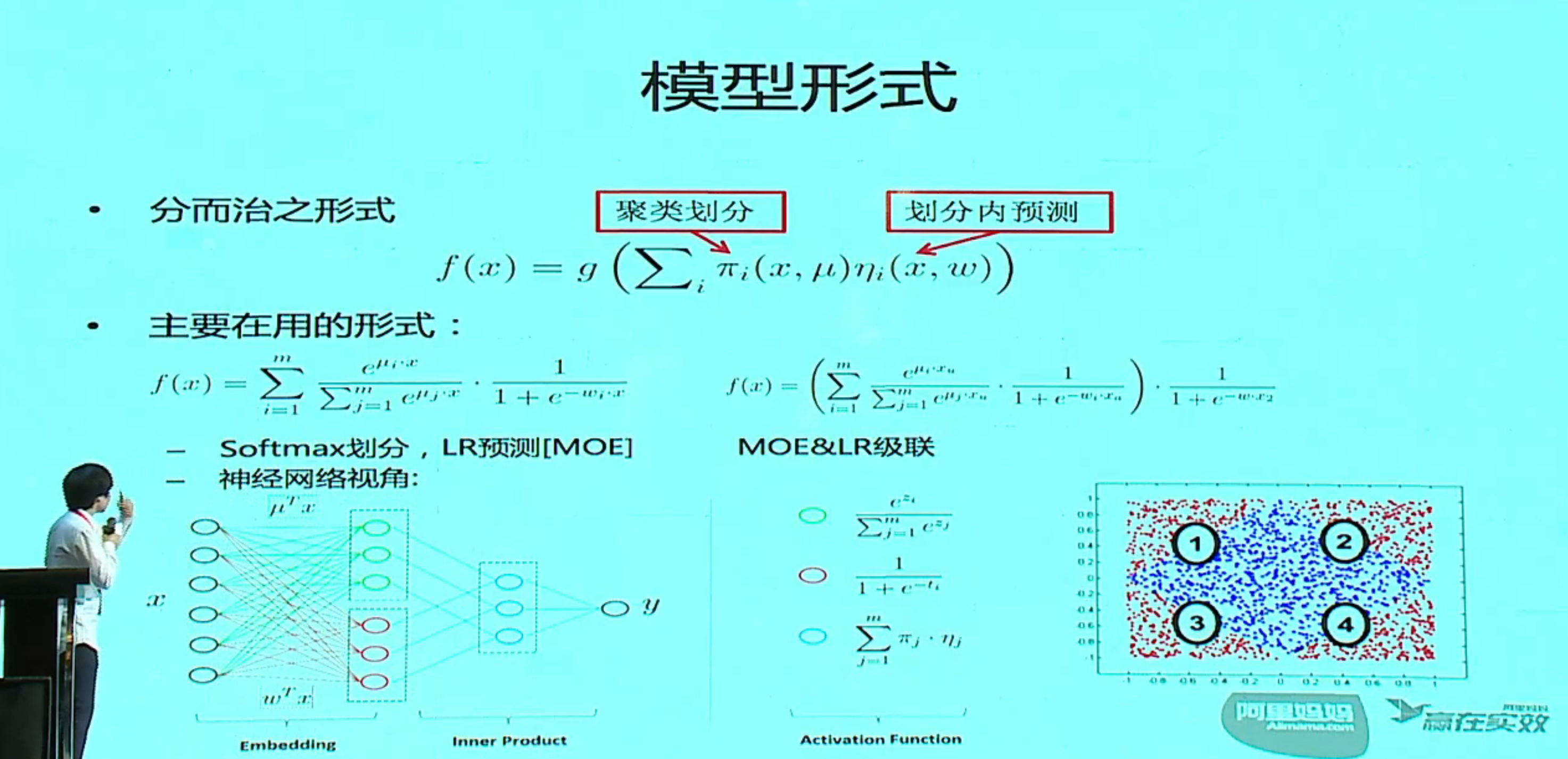
分片用 softmax,预测模型用 LR,实际就是一个 MOE 模型,外面再加一个 LR 级联



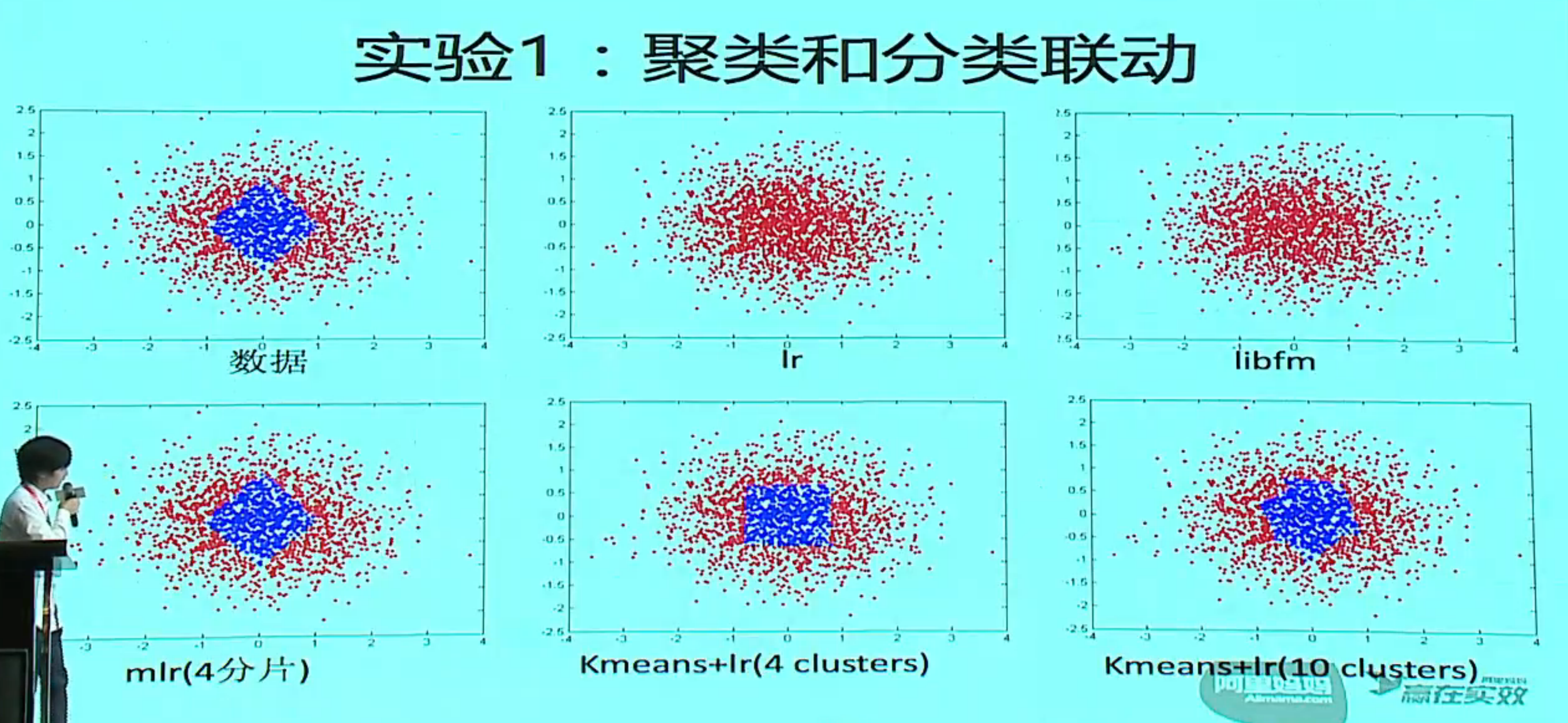
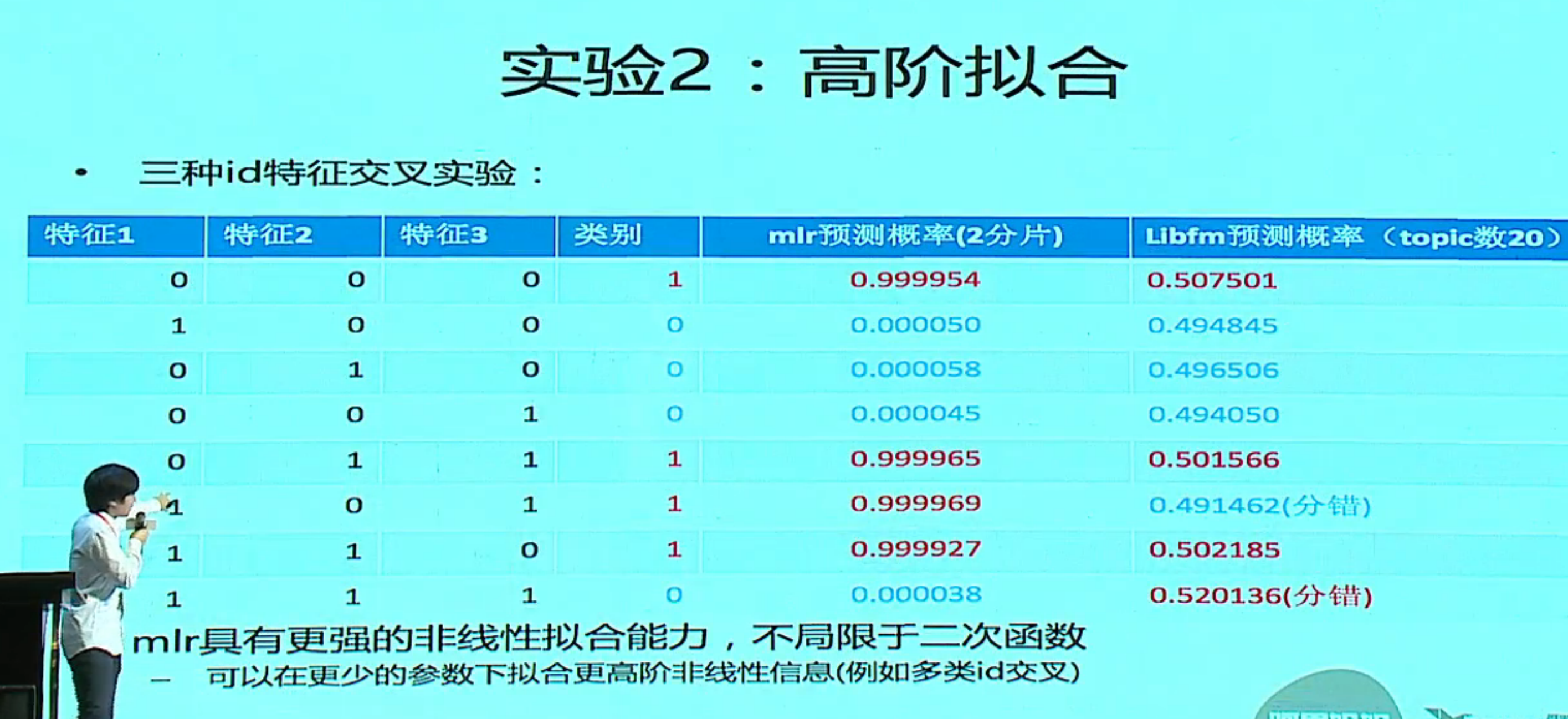
大规模 ID 特征 + MLR 实践


深层用户兴趣分布网络


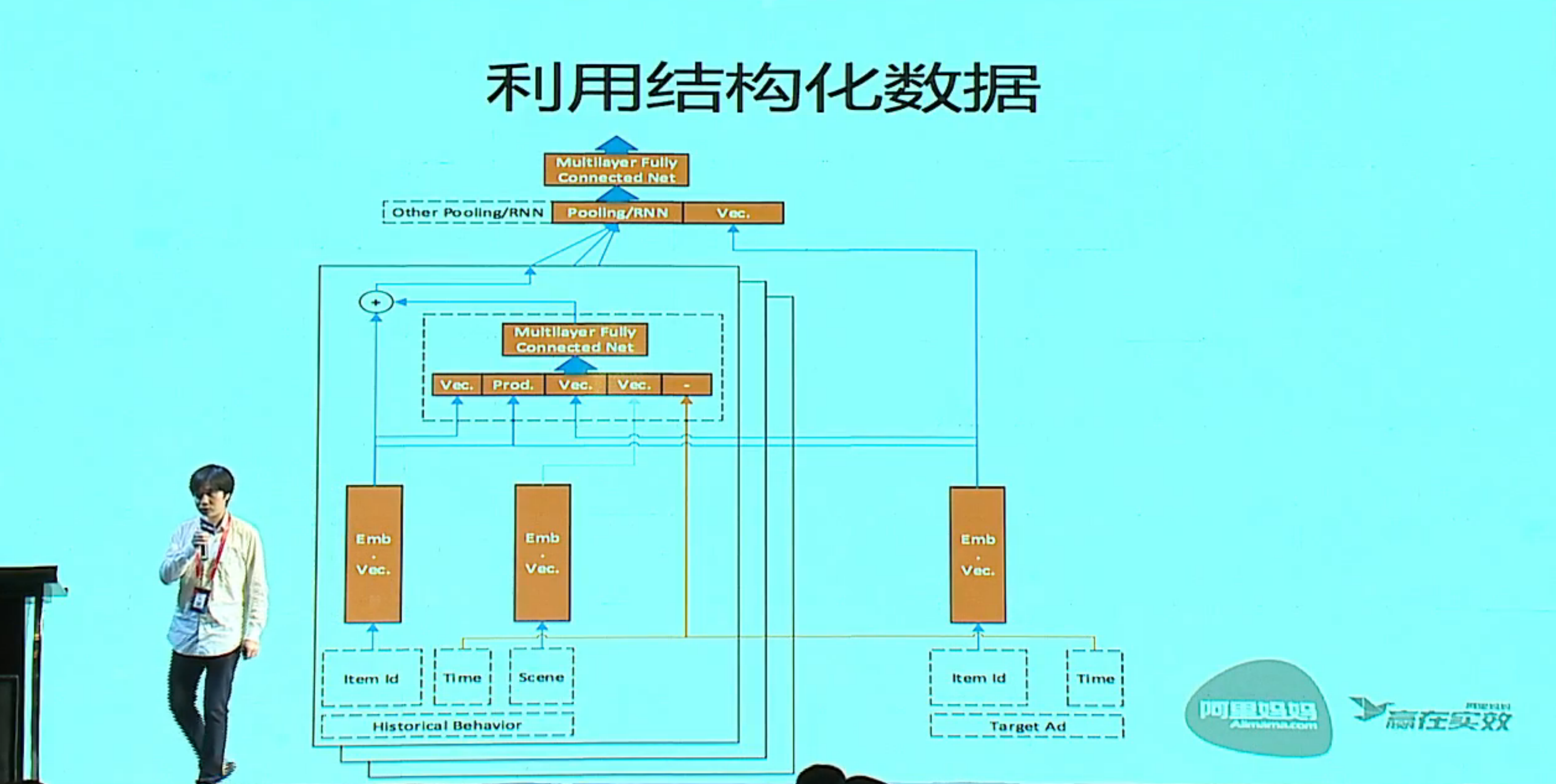

认知分析-透过机器重新审视商业本质
杨洋,商业认知分析平台iPIN创始人兼CEO。创办iPIN前,杨洋曾在美国国家旅游与电子商务实验室(NLTeC)从事搜索引擎研究,曾师从世界著名信息科学家Rajiv Banker和Pei-yu Chen从事多年大规模众包集智数据分析和研究,并获得博士学位,曾任哈尔滨工业大学管理学院副教授。此外还有过多次互联网创业经历,并曾在NASDAQ上市公司YY Inc.担任全球化负责人。
人对信息的处理过程,感知 -> 认知 -> 分析 -> 决策。人类对认知的理解还不是很成熟,这也是人工智能的天花板之一,如何让机器去掌握人类常识。
从生物学/物理学/哲学/社会学/经济学/市场心理学/神经科学各个角度阐述了什么是认知。比如说在我们看来,信任/不信任是同一个维度的问题,然而神经科学发现不是,你可以同时信任一个人,不信任一个人,可以爱一个人,同时恨一个人。无论哪个领域,整体的逻辑差不多是:
认知是真相在具体场景下的投影
实现机器认知的条件
- 信息可靠
- 信息充分
- 精细建模
如何对小规模数据敏感,dl 很难达到 - 不懂就“问”
机器能主动发问
还讲了一些具体应用,个人发展应用类的如完美志愿,涉及到生涯规划,用机器学习的方法来看人是怎么发展的,让机器去学习总结大量的(潜)规则,再如前程导航,SCCT 理论来规划你的人生;企业发展应用如人才分析引擎,把不可矢量的东西都矢量化,从认知层面去做计算,等等。
用人工智能打造教学机器人提升十倍教育效率
栗浩洋 「非你莫属」BOSS,社交APP「朋友印象」创始人,国内第一家人工智能自适应网络教育公司「乂学教育」创始人。黑马会上海会长,黑马连营主任导师,央视二套「实战商学院」导师,第一财经《中国经营者》特约嘉宾,《商界时尚》杂志封面人物。曾先后被福布斯、第一财经、i黑马、36Kr等100多家媒体采访报道。
总体逻辑,实现有教无类,教无定法,因材施教。
MOOC & 传统教学无区别对待所有的学生和所有知识点,每个人的起点和终点不一样,然而老师教的是线性的。智适应系统,能精确侦测不同学生的知识漏洞,利用知识状态空间+知识空间理论来精准定位学生知识点掌握状态,还可以从大量数据中发现强关联的知识点和弱关联知识点。同时,精准把知识点分拆定位;又由于每个学生掌握一个知识点所需的时间是不同的,逻辑方向是不同的,所以要做个性化的匹配和学习内容推荐
个性化匹配
- 学生画像+内容侧写
- 机器学习+概率图模型
- 个性化学习内容和路径匹配
哎,感觉把我们当投资人或者顾客了。。
智能助手专场
这一场本来应该是我最感兴趣的一场,无奈嘉宾讲的都很泛,可能是因为中间设计的技术太多,没法展开吧。
远程语音交互的技术挑战和商业思考
陈孝良,北京声智科技有限公司。
人机交互的升级大致来说分三个时代,最开始是PC互联网时代,主要依赖键盘、鼠标,后来是移动互联网时代,以智能机为代表,大量依赖触摸屏,到现在的AI互联网时代,以远程语音交互为主要交互方式,当然这不是唯一的,还有其他的方式辅助。
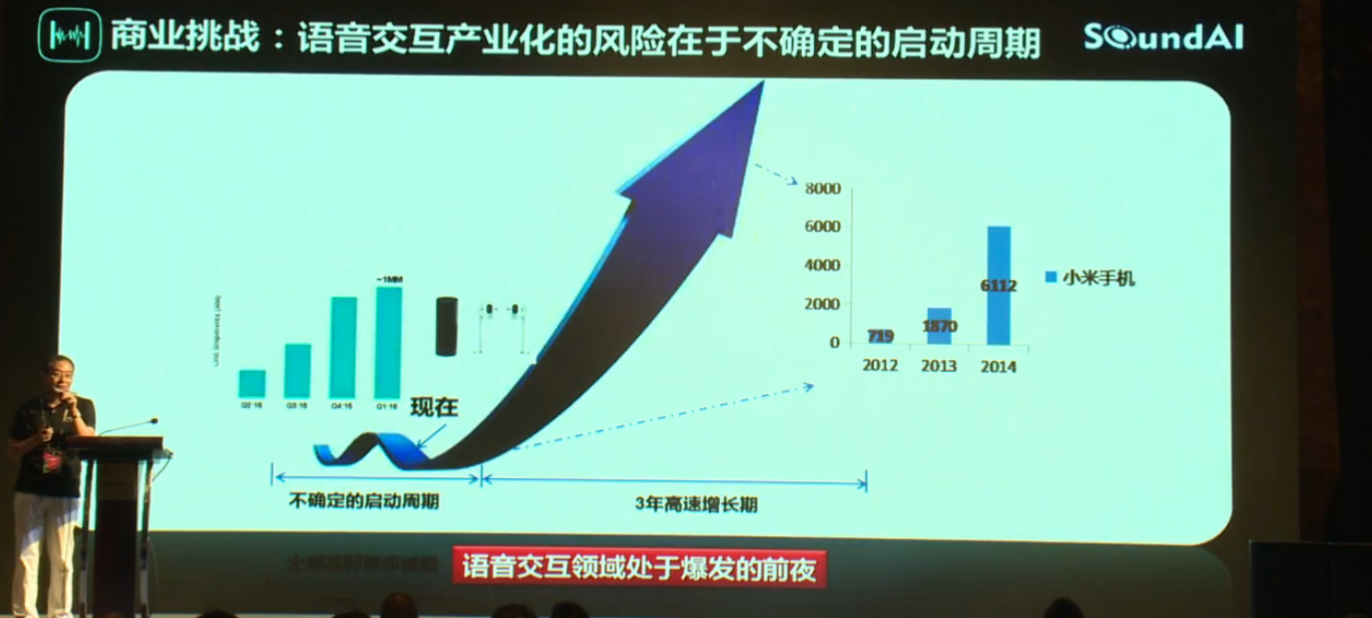
技术挑战: 远场语音交互技术瓶颈在于声学和场景
近场可以近似理解为只是实验室的理想环境,远场要考虑更多
- 语音识别率 95%,但用户体验不好
行业目标:以语音控制模式打造极致(速度、精度)产品体验
核心瓶颈:远场语音识别、远场场景适配、NLP 精确反馈 - 语义理解技术有本质性突破
行业目标:拟人化,全功能型产品,实现听你所言,知你所想
核心瓶颈:声光电多种传感的融合,NLP 技术的实质性突破
技术挑战:
- 器件
需要升级,然而麦克风的性能、精度,核心技术不在国内,标量麦克风=>矢量麦克风,国内相对落后 - 芯片
- 算法
如离线关键词识别(语音唤醒)、离线声纹识别(Voice ID),AEC 回声消除,Adaptive Beamforming, Speech Dereverberation,声源定位技术,孤立样本学习,深度强化学习 - 商业
语音交互产业化的风险在于不确定的启动周期,到了启动周期爆发时间就只有三年
产品,内容和服务,标准和知识产权,

对话即应用:过去仍在,未来已来
戴帅湘,蓦然认知 CEO前百度主任架构师,并长期担任百度 Query 理解方向负责人,荣获第一个百度语义技术的最高奖。
感觉讲的更多是 IoT 的内容,讲了未来发展趋势,几个融合
- VOI 和 GUI 的融合
GUI 人适应机器,处理简单的、特定的任务,VOI,机器适应人,可以处理相对模糊的,复杂的任务 - 多场景融合
关注长尾的需求 - 设备之间的协同
比如说车+家的互联,把家里的空调调到24度 - 知识和服务的融合
设备时代结束,助手时代到来
刘耀平,暴风TV CEO,被誉为“互联网电视第一人”。
听到(DSP) => 听清(ASR) => 听懂(NLP) => 做到(SKILL)
介绍了暴风家庭助手,感觉像 echo show 的中文版,视频看上去不错,不知道真正体验如何。
讲了未来趋势:
- 多设备协同计算(多助手),未来一定是助手与助手之间的联网和协同,
- 多屏协同服务,服务在多屏呈现,屏幕无处不在
- 跨空间场景迁移
未来会产生家庭社交平台,人与助手,助手与助手,人与人的交互。
AI+专场
机器写稿技术与应用
万小军,北京大学计算机科学技术研究所研究员。
运用到机器写稿技术的主要单位有
- 媒体:新华社、头条、南都等
- 互联网企业:微软、百度、腾讯、头条等
- 科研院所
写稿类型一般有体育、财经、民生、娱乐新闻,以及绝句、诗歌等。
原创 vs 二次创作
机器写稿有两种方式,一种是原创,一种是二次创作。原创一般是之前没有稿件,只有结构化的数据,借助结构化的数据去生成新的稿件。比如说写一个天气预报的报道,或者年报、财报都直接可以从数据中生成。而关于一个已经有相关报道的事件,我们可以借助这些报道进行一些拼凑、改写成为新的稿件,这就是二次创作。
基础技术研究
- 自动文摘
- 自然语言生成
- 文本推荐
- 文本复述
应用技术研究
- 新闻资讯自动生成
- 新闻综述自动生成
- 用户评论自动生成
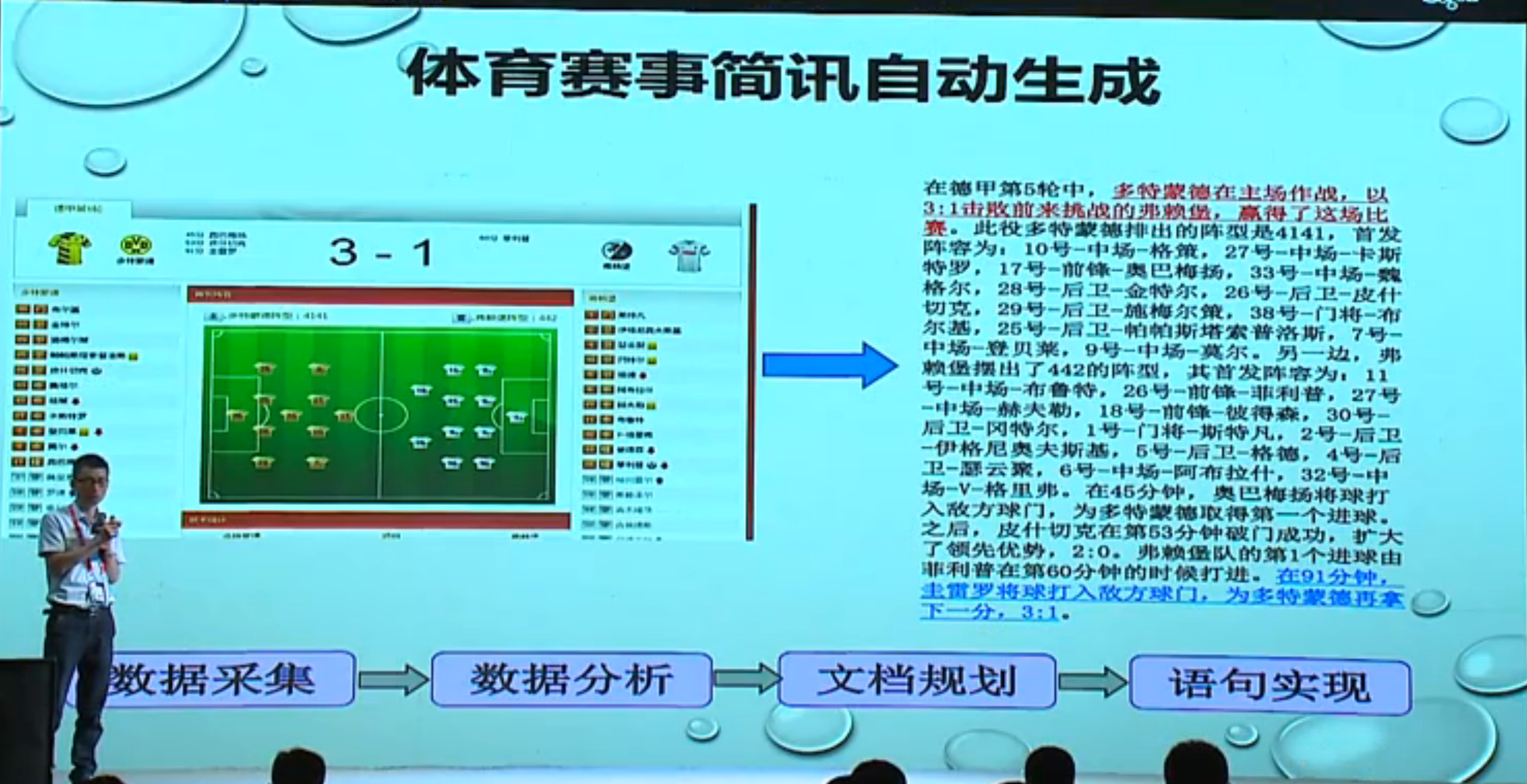

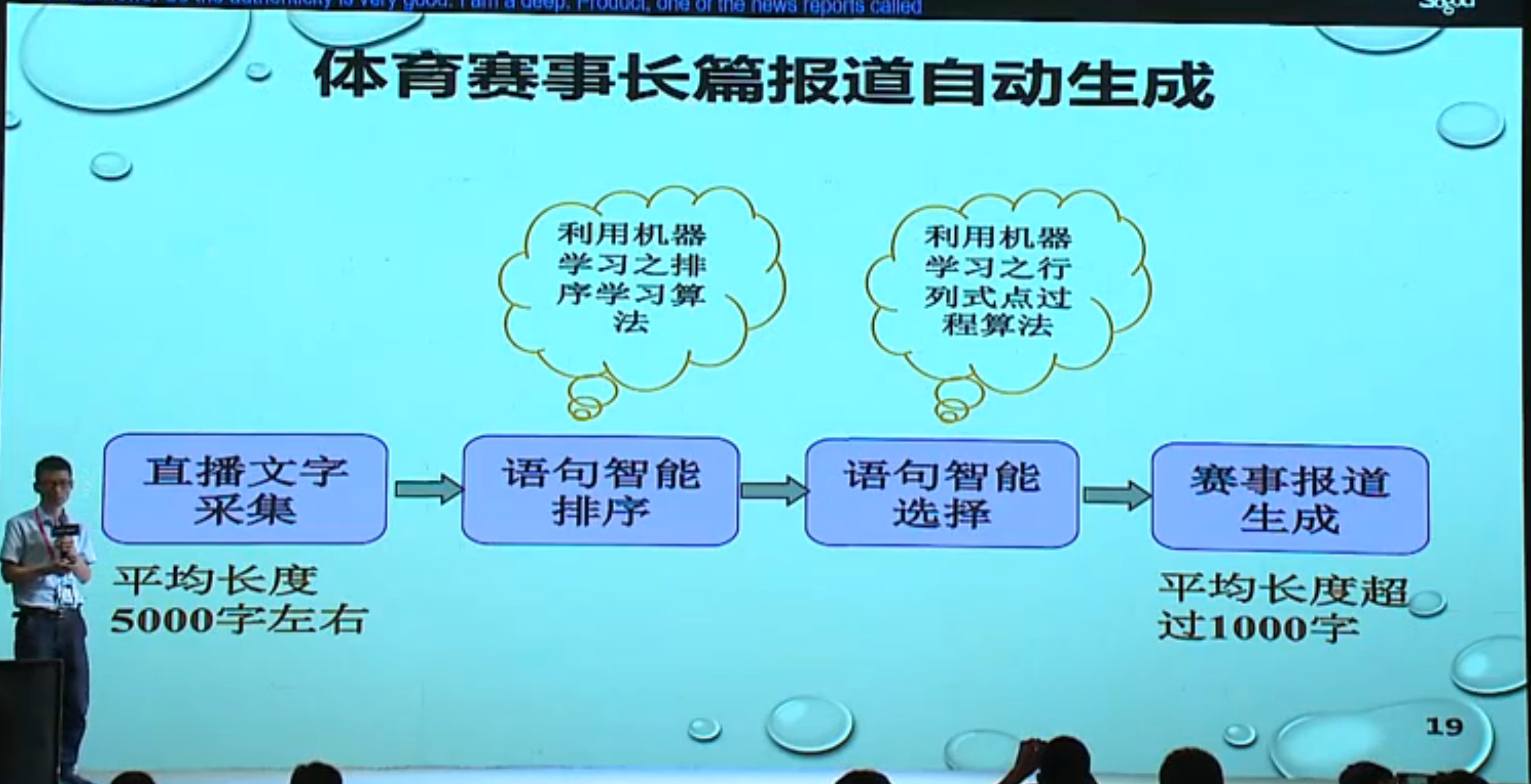
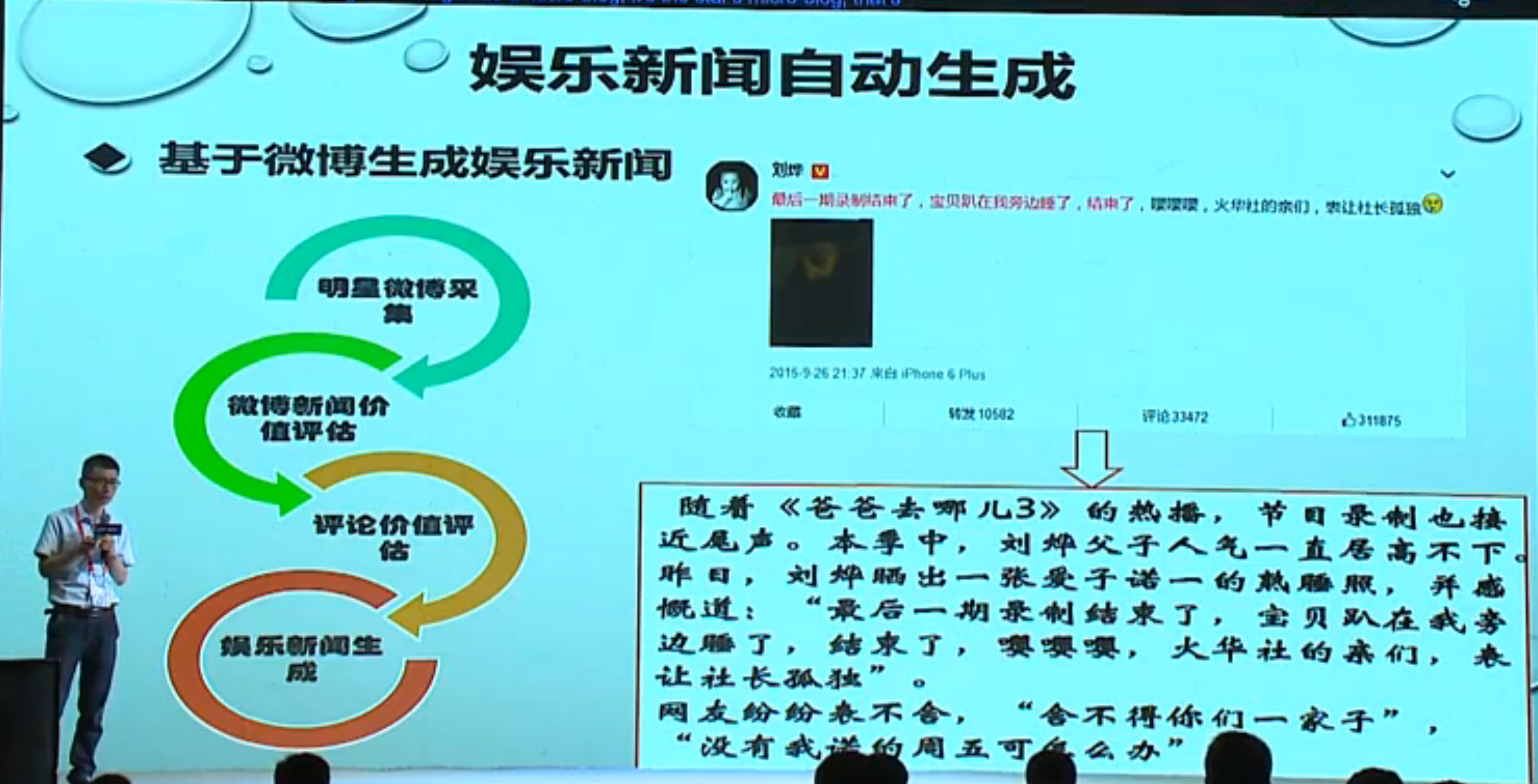
一些应用:
- 看明星的微博,判断是否有新闻价值,如果有,结合微博、评论信息、背景信息,生成新闻;
- 新闻资讯的生成,长短可控,几十字、上千字的简讯/资讯;
- 新闻综述自动生成:根据同一事件的多篇新闻报道,自动生成篇幅较长的事件综述。用 wikinews 做的实验,主要过程:新闻采集 =》(子话题选择)段落划分 =》段落排序 =》段落选择与合并
- 用户评论自动生成,根据制定的用户观点数据(产品特性+评分),自动生成对应的产品评论,基于深度学习模型,根据产品特性和评分,生成自然语言的评论

趋势展望
- 让稿件具有态度和立场,更加人性化
- 通过推理与归纳,撰写深度报道
智影:AI 让视频更简单
康洪文,慧川智能 CEO
感觉很酷炫的样子,通过明星识别、场景识别、行为识别以及视频标签化后,可以根据文字来自动生成配套的视频。举个应用的例子,如果微信公众号的很多文章都可以配上配套的短视频,是不是很棒!
小结
结尾引用某嘉宾的话,未来的世界无商业不智能,无智能不商业。从消费和生产两方面来看,消费互联网解决了高效的流通,产业互联网解决了正确的生产。看吧,我们赶上了最好的时代,同志们加油~ (P.S.最后和来自各大高校的童鞋以及雷锋网的小伙伴们面了个基,可惜奕欣姐姐嫌弃合照就不上图了。。)

