QG 的应用还是挺广泛的,像是为 QA 任务产生训练数据、自动合成 FAQ 文档、自动辅导系统(automatic tutoring systems)等。
传统工作主要是利用句法树或者知识库,基于规则来产生问题。如基于语法(Heilman and Smith, 2010; Ali et al., 2010; Kumar et al., 2015),基于语义(Mannem et al., 2010; Lindberg et al., 2013),大多是利用规则操作句法树来形成问句。还有是基于模板(templates),定好 slot,然后从文档中找到实体来填充模板(Lindberg et al., 2013; Chali and Golestanirad, 2016)。
深度学习方面的工作不多,有意思的有下面几篇:
- Generating factoid questions with recurrent neural networks: The 30m factoid question-answer corpus
将 KB 三元组转化为问句 - Generating natural questions about an image
从图片生成问题 - Semi-supervised QA with generative domain-adaptive nets
用 domain-adaptive networks 的方法做 QA 的数据增强
论文笔记
神经网络做 QG 基本套路还是 encoder-decoder 模型,对 P(q|d) 或者 P(q|d, a) 进行建模。像是 17年 ACL 的 paper Learning to Ask: Neural Question Generation for Reading Comprehension,就是用一个基本的 attention-based seq2seq 模型对 P(q|d) 进行建模,并在 encoder 引入了句子和段落级的编码。
这一篇 Microsoft Maluuba 出的 paper 把 answer 作为先验知识,对 P(q|d, a) 进行建模。同时用监督学习和强化学习结合的方法来训练 QG,先用最大似然预训练一波,然后用 policy gradient 方法进行 fine-tune ,最大化能反映问题质量的一些 rewards。
Encoder-Decoder Model
基础架构是 encoder-decoder,加了 attention mechanism (Bahdanau et al. 2015)和 pointer-softmax coping mechanism (Gulcehre et al. 2016)。
Encoder
输入:
- document $D=(d_1, …, d_n)$
- answer $A = (a_1, …, a_m)$
$d_i, a_j \in R^{D_e}$ 是词向量。
在文档词向量后面拼了个二维特征表示文档单词是否在答案中出现。然后过 Bi-LSTM 对文档表示进行编码得到 annotation vectors $h_d=(h^d_1,…h^d_n)$,$h^d_i \in R^D_h$, $h^d_i$ 是每一时刻前向和后向 hidden state 的拼接。
接着对 answer 编码。主要根据 answer 在 document 的位置找到对应的 annotation vector,然后把它和 answer 的词向量拼接起来也就是 $[h^d_j;a_j], s<=j <=e$,s,e 表示 answer 在 document 的起始结束位置,经过第二个 biLSTM 得到 $h^a \in R^{D_h}$,$h_a$ 是两个方向 final hidden state 的拼接。
计算 decoder 的初始状态 $s_0 \in R^D_s$
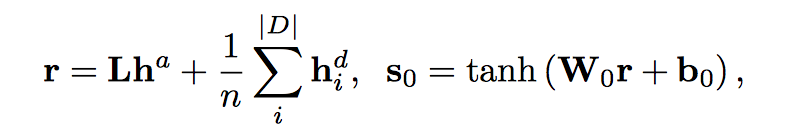
$L \in R^{D_h * D_h}, W_0 \in R^{D_s * D_h}, b_0 \in R^{D_s}$
Decoder
解码器产生输出,输出单词从 $p_\theta(y_t|y_{<t}, D, A)$ 分布中得到。
为了在问句中直接产生文档中的一些短语和实体,在 decoder 的时候采用了 pointer-softmax,也就是两个输出层,shortlist softmax 和 location softmax,shortlist softmax 就是传统的 softmax,产生 predefined output vocabulary,对应 copynet 中的 generate-mode,location softmax 则表示某个词在输入端的位置,对应 copynet 中的 copy-mode。
Decoder:
$$s_t=LSTM(s_{t-1}, y_{t-1}, v_t)$$
$v_t$ 是从 document 和 answer encoding 计算得到的 context vector,用了 attention 机制,$a_{tj}$ 同时可以用作location softmax。
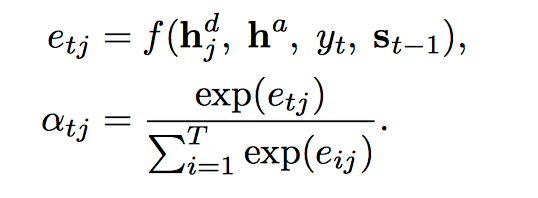
context vector: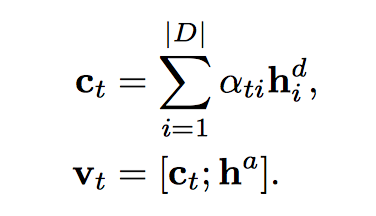
shortlist softmax vector $o_t$ 用了 deep output layer (Pascanu et al., 2013)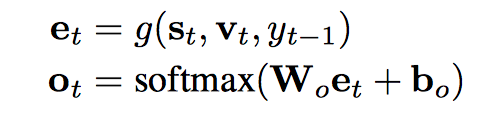
最后的 $p_t \in R^{|V|+|D|}$ 由 $z_t$ 对两个 softmax 输出进行加权和拼接得到。$z_t$ 由 MLP 产生,输入也是 $s_t, v_t, y_{t-1}$,两个隐层然后输出层 sigmoid 激活得到 $z_t$。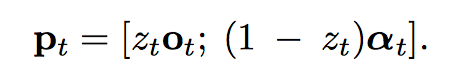
Training
三个 loss:
- negative log-likelihood
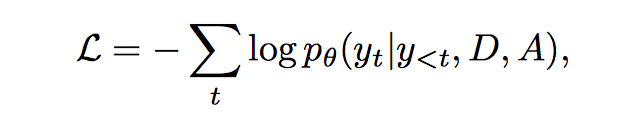 用了 teacher forcing,也就是 $y_{t-1}$ 不是从模型输出得到的,而是来自 source sequence
用了 teacher forcing,也就是 $y_{t-1}$ 不是从模型输出得到的,而是来自 source sequence - not to generate answer words in question
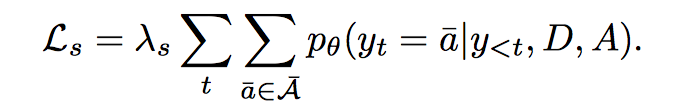 $\hat a$ 表示在 answer 中出现但没有在 groud-truth question 中出现的单词
$\hat a$ 表示在 answer 中出现但没有在 groud-truth question 中出现的单词 - Variety
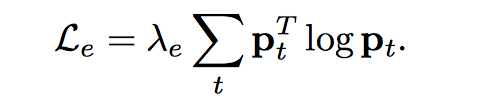 最大化信息熵来鼓励输出多样性
最大化信息熵来鼓励输出多样性
Policy Gradient Optimization
Teacher forcing 会带来一个问题,训练阶段和测试阶段的结果会存在很大差异。在训练阶段,tearcher force 使得模型不能从错误中学习,因为最大化 groud-truth likelihood 并不能教模型给没有 groud-truth 的 example 分配概率。于是就有了 RL 方法。在预训练一波 maximum likelihood 之后,使用一些和问题质量相关的 rewards,来进行 policy gradient optimzation。
Rewards
- Question answering
好的问题能被回复
把 model-generated question 喂给预训练好的 QA 系统(论文用的 MPCM 模型),然后用 QA 系统的 accuracy(比如 F1) 作为 reward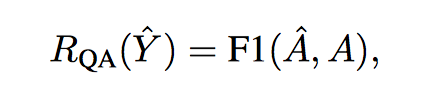
- Fluency (PPL)
是否符合语法,过一个语言模型计算 perplexity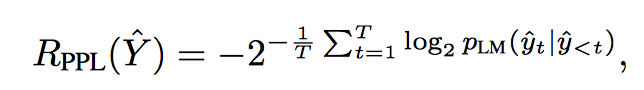
- Combination
两者加权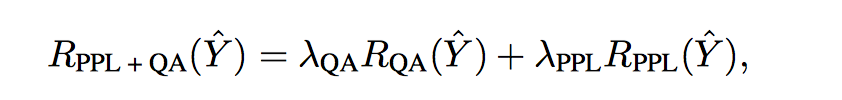
Reinforce
“loss”: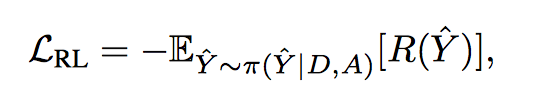
$\pi$ 是要训练的 policy,是action 的概率分布,action space 就是 decoder output layer 的词汇表,可以通过 beam-search 采样选择 action,采样结果通过 decoder teacher-force 还原得到 state,计算 reward 进行梯度更新。
Policy gradient: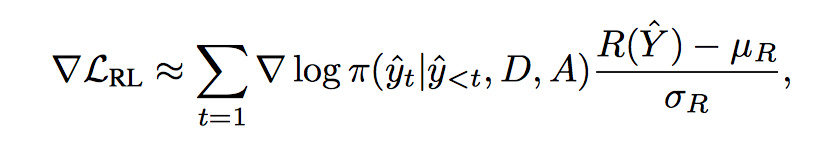
Evaluation
Baseline Seq2Seq 可以产生更符合语法更流畅的英文问题,但是语义可能更加模糊,这篇 paper 提出的系统可以产生更具体的问题,虽然没那么流畅。