CMU 11611 笔记。讲语篇分析的一些概念,包括 coreference, cohesion, speech acts 等。
Introduction
Discourse is the coherent structure of language above the level of sentences or clauses. A discourse is a coherent structured group of sentences.
Discourse Analysis 中文对应过来通常是语篇/篇章分析。前面讲到了语素级别的(morphemes)、词汇级别的(lexical)、短语级别的(segmentation)、句子级别的(syntactic parsing)种种概念及分析,现在到了 beyond sentences 这一级别,只有两句或两个句子/从句以上的句子,才被称为 discourse。广义来讲,discourse 其实有很多含义,大多都能归到下面三类。
- Language beyond sentences
语言学家(Linguistists)关注的概念,分析句子之间是怎么联系/衔接的,也是本篇的重点 - Language in use
可以理解为实际发生的对话(conversation),这是应用语言学家(Applied Linguistists)会关注的,比如说他们会来研究医患人员的对话来看医生是怎么在对话过程中建立权威的(结合 speech acts) - A broader range of social practice that includes nonliguistic and nonspecific instances of language
不止是语言学的内容,而是 linguistic + social practice + ideological assumption 结合的产物,社会学家对这个更感兴趣,会关注特定时间特定场景下的行为,比如来研究种族歧视等社会现象(结合 contexts)
具体见The Handbook of Discourse Analysis
语篇分析的应用很广泛,比如说自动文摘、自动作文评分、会议理解、对话系统等。
Coreference
一个重要的概念是 coreference,表示共指关系。自然语言的所指现象非常丰富,有不定名词短语(indefinite noun phrase)、有定名词短语(definite noun phrase)、代词(pronoun)、指示词(demonstrative)、单个复指(one-anaphora)等,所指对象类型有推理对象(inferrable)、不连续集(discontinuous set)和类属(generic)。下面主要以代词指代来讲共指的概念。
先来看下两个概念,anaphora 和 cataphora,两者都是指代,不同的是 referent 和 referring expression 出现的先后顺序
- anaphora: the use of a word referring to or replacing a word used earlier in a sentence
- cataphora: the use of a word or phrase that refers to or stands for a later word or phrase
E.g., Anphora
the old man 和 he 是 referring expression,在这个场景下也是 anaphora,都指代前面的 my grandfather,my grandfather 又称为先行词(antecedents)。
Referring expressions: the old man, he
Antecedents: my grandfather
E.g., Cataphora
先出现 She,再出现 She 指代的 Mary。
指代问题在单个句子或者多个句子中都会出现,这一章讲 discourse,只讨论多个句子中的指代消解问题(Reference Resolution)。
Pronoun reference resolution
看一个简单的代词指代消解的例子。
我们需要来判断 she 指代谁。
第一步,找到所有的 candidate referents,也就是名词短语。
直觉上看,She 必须是 Person,所以 morning, park 删除,John 是男性,gender 不符,删除,her dog 难以确定 gender,最有可能的是 Mary。这个例子非常简单,仅仅通过一致性约束就判断出了正确的 referent,很多场景比这复杂的多。下面先来看一下代词指代消解相关的一些规则/模型。
Filters: 句法和语义约束
根据下面的一些规则约束可以 排除 一些 candidate referents。
- Agreement constraints (一致性)
gender, number, person, animacy - Binding theory: reflexive required/prohibited (反身代词)
反身代词可以用于同指包含它的最近邻从句的主语,而非反身代词不能同指该主语
– John bought himself a new Ford. [himself=John]
– John bought him a new Ford. [him≠John]
– John said that Bill bought him a new Ford. [him≠Bill]
– J said that B bought himself a new F. [himself=Bill]
– He said that he bought J a new Ford. [both he≠J] - Selectional restrictions
选择限制,动词对论元(argument)施加的选择限制
John parked his car in the garage after driving it around for hours.
动词 drive 要求直接宾语是能够驾驶的事物,比如说 car
Preferences: 优先级
下面的一些偏好规则说明哪些 referents 有更大的可能性是正确的。
- Parallelism
- Sentence ordering: Recency
邻近话段引入的实体比较远话段引入的显著性更高 - Grammatical Role: subj>obj>others
- Repeated mention
Billy had been drinking for days.
He went to the bar again today. Jim went with him. He ordered rum. - Verb semantics
有些动词的出现会对其中一个论元的位置产生语义上的强调,这会造成对其后代词的理解偏差
John phoned/criticized Bill. He lost the laptop.
如果是 phone,明显应该是 John 丢了电脑,如果是 criticize,应该是 Bill 丢了。这被认为是动词的“隐含因果关系”,criticize 事件的隐含因果被认为是动词宾语,而 phone 被认为是动词主语
Discourse model
很多指代消解算法的第一步是建立 discourse model,discourse model 包含了 discourse 所指实体的表示以及它们所承担的关系,模型有两个基本操作,如下图所示,当第一次提到所指对象时,我们称它的表示为被唤起(evoke)而进入模型,之后当再次提及时,我们称从模型中访问(access)它的表示。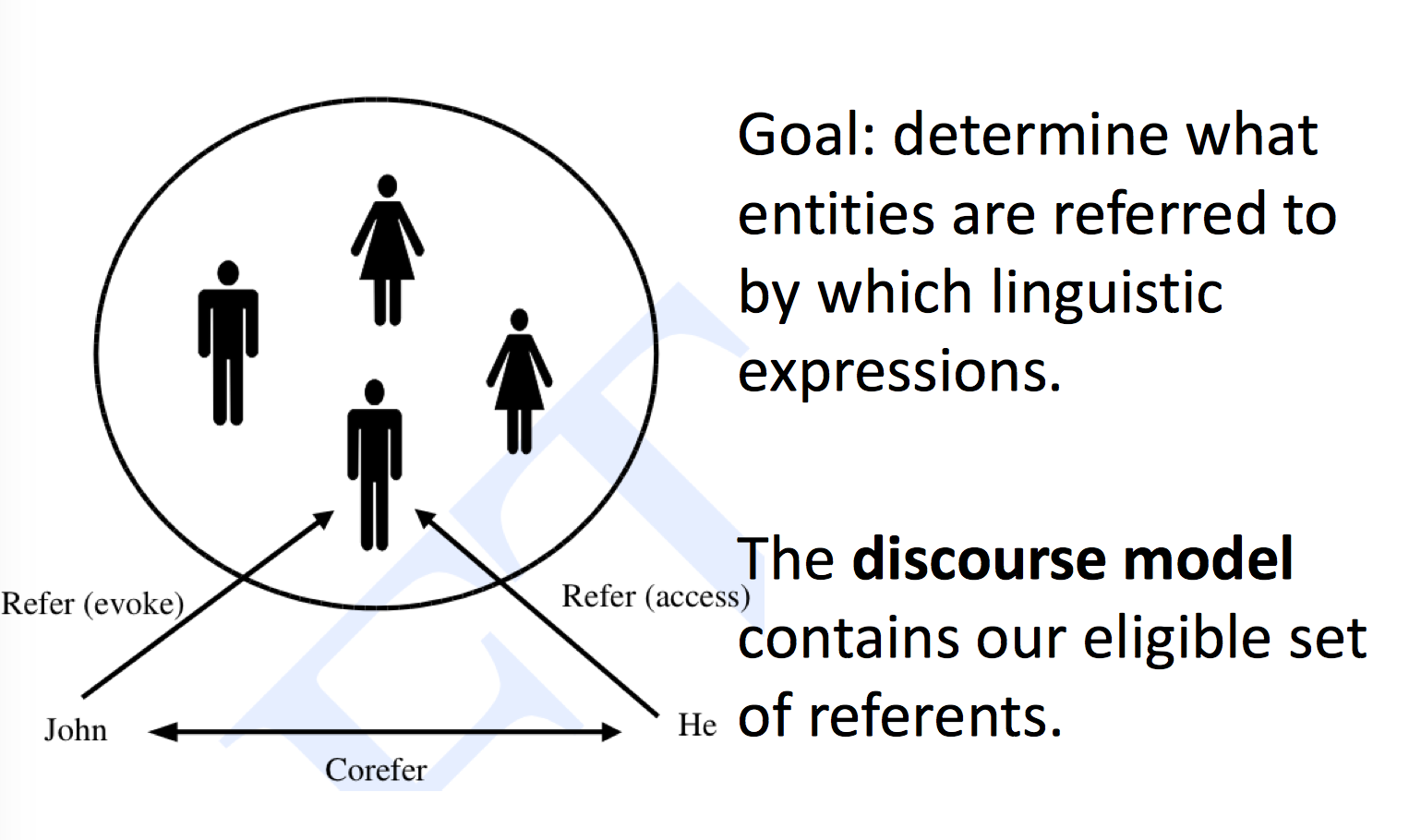
Computational approaches to pronouns reference resolution
有了前面的知识储备,现在可以来看一下代词指代消解的传统算法。
Hobbs Algorithm
非常早期的,1978 年 Hobbs 提出一种不依赖任何语义知识或语篇信息,只利用语法规则和完全解析树信息的指代消解算法,又叫树查询算法(Tree Search Algorithm)。算法会遍历当前句子和先行句(preceding sentences)的解析树,根据 binding theory, recency, 和 grammatical role preferences 选择合适的 NP 作为 referent,这种方法需要 parser,需要 gender 和 number 信息,也需要用于确定 NP gender 的 head rule 和 wordnet。现在实际系统中很少直接使用,一般只会拿来做 baseline。
算法过程:
Resolution of Anaphora Procedure(RAP)
1994 年 Lappin 和 Lease 提出的,综合考虑了 recency 和基于句法的优先关系的影响。使用 McCord 提出的 Slot Grammar 获得文档的句法结构,根据过滤规则过滤掉不合适的 referent,然后通过手工加权的各种语言特征计算剩下的 referent 重要性,确定 referent。1996 年 Kennedy 等人对 RAP 做了修改和扩展,避免了构建完整的解析树,只用 NLP 工具预处理得到词性标注和句法功能标注等浅层信息,2005 年 Luo 等人继续做了改进,尝试用最大熵模型来自动确定各种语言特征的权值。下面来看一下基础版本的 RAP 算法。
两个步骤,discourse model 的更新和代词的判定。遇到一个唤起的新的实体的名词短语时,必须为它添加一个表示以及用于计算的显著度(salience),显著度由一组显著因子(salience factor)所指派的权值综合来计算。每处理一个新句子,discourse model 中的每个因子为实体所指派的权重就减一半。
显著因子及其权重: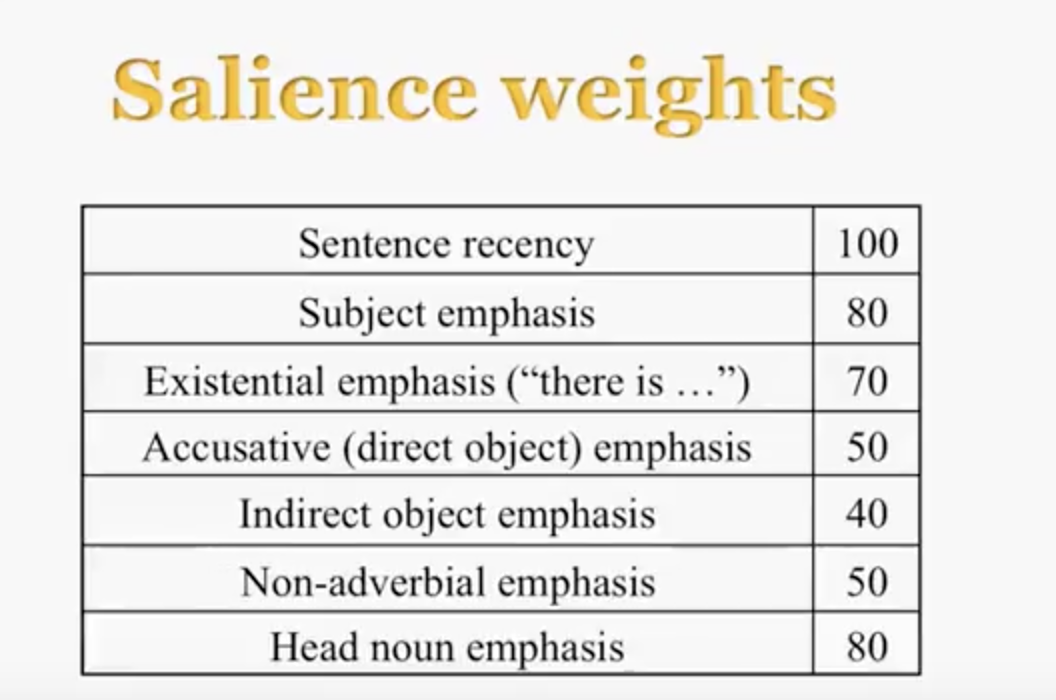
RAP 过程:
Example:
=> he 指代 John
Halve
加入 he 的分数
根据规则 => it 指代 Integra,加入 it 的分数

加入 Bill
Halve
……
Centering theory
Centering algorithm 和 Lappin & Leass 算法一样都采用了 discourse model 的表示,但同时引入了 center 的概念,center 表示语段中心成分,在语篇中联系不同语段的实体(entity),在话语中的任何定点都有一个单独的实体被作为 center。center 细分为语段潜在中心 (forward-looking center $C_f$) 和语段现实中心(backward-looking center $C_b$)。
对于由 $U_1, …, U_t$ 构成的语篇,语段 $U_n$ 的 $C_f$ 和 $C_b$ 由下面的制约条件:
- $C_f(U_n)$ 是当前语段中的所有实体组成的集合,在下一语段中至少会部分实现(realize)
- $C_b(U_n)$ 是 $C_f(U_{n-1})$ 中的一个,而且是 rank 最高的那个 $C_b = \ most \ highly \ ranked \ C_f \ used \ from \ prev. \ S$
Rank: Subj > ExistPredNom > Obj > IndObj-Obl > DemAdvPP
语法角色层级和 Lappin & Leass 算法相似,但并没有给实体附加权重值,只是简单的相互排序 - 每一个 $U_n$ 都可以有一组 $C_f$,但最多只能有一个 $C_b$,一般来说,篇章的第一个语段没有 $C_b$
- 在 $C_f$ 集合里,rank 最高的称为 Preferred Center $C_p$
转换规则:
有了上面的概念和规则,再来看一下基于 Center 的指代消解算法
Step1: 为每个语段中的实体生成可能的 Cb-Cf组;
Step2: 通过各种约束条件来过滤(比如:句法位置约束、语义选择限制,等等);
Step3: 通过转换顺序来给出排序:如果一个代词 R 的指代成分为 A 所得到的篇章连贯性高于指代成分为 B 时得到的篇章连贯性,则将 R 的指代成分确定为 A。
Centering 和 Hobbs 都假设输入时正确的句法结构。和 Lappin & Leass 算法相似,中心算法的主要显著因子包括 Grammatical Role, Recency, Repeated Mention,但不同的是语法层级对显著性影响的方式是间接的,如果低级语法角色的所指对象导致的转换时较高级别的,它会比高级角色的所指对象优先,所以 centering algorithm 可能会将其他算法认为是相对较低显著性的所指对象判定一个代词的所指对象。比如说
|
|
Log-linear model
监督学习,需要手工标注同指关系,基于规则过滤,还是以上面的语段为例,特征如下: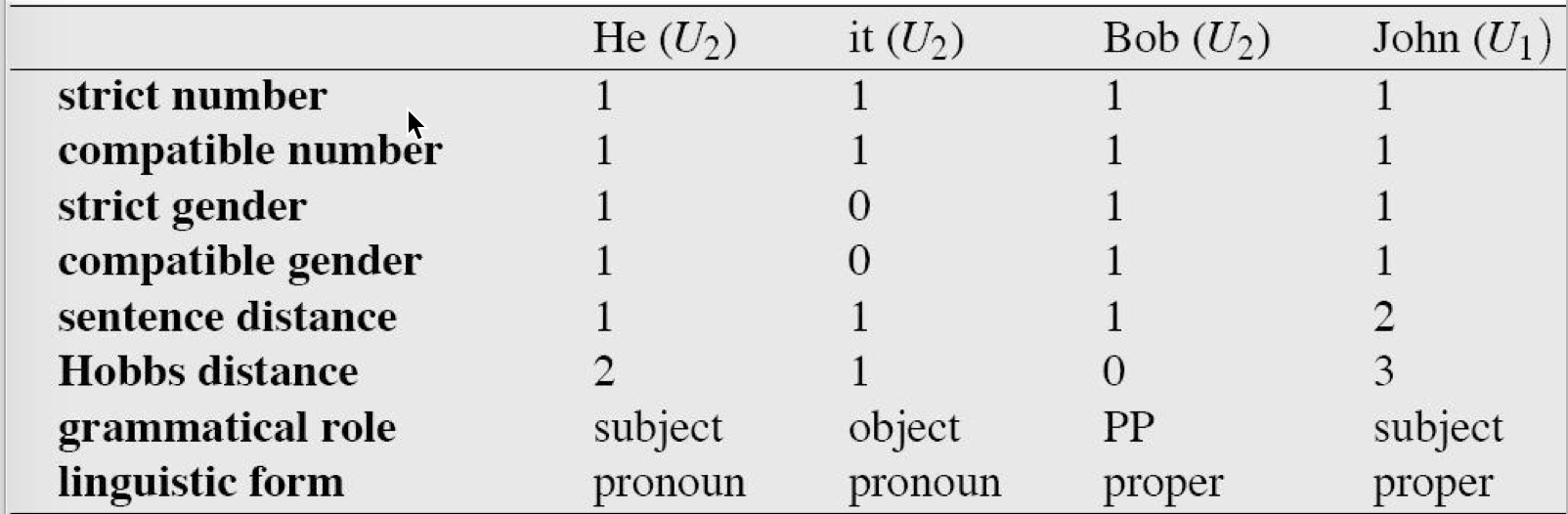
General Coreference Resolution
就是转化为一个分类问题,先识别文本中的 NP,然后对每一个 NP pair 进行一个二分类,看他们是否是共指关系,然后合并结果形成共指链(coreferential chain),Coreference chains 其实是 cohesion 的一个部分,下面会具体讲到 cohesion。所以我们需要的是
- a choice of classifier
- lots of labeled data
- features
可以选的特征有
更多见
• Combine best: ENCORE (Bo Lin et al 2010)
• ML for Cross-Doc Coref (Rushin Shah et al 2011)
Coherence, Cohesion
Coherence Relations
Cohesion 是衔接,强调句子构成成分之间的关联性,Coherence 是连贯,强调句子之间的语义连接关系。看下面三组句子,只有第一组是 make sense 的,而第二第三组的两个句子间没有任何关联。
句子之间的衔接关系有很多种,比如说结果(result)、解释(explanation)、平行(parallel)、详述(elaboration)等。 William Mann 和 Sandra Thompson) 提出了 RST (Rhetorical Structure Theory,修辞结构理论),可以用来解释这种关系。RST 是基于局部文本之间的关系的文本组织理论,它认为语篇(discourse)的构成具有层次关系,通过修饰结构可以表示语篇结构。RST 在文本生成(text generation)、文本摘要(text summarization) 等场景下都有应用。
两个概念是 核心(nucleus) 和 外围(satellite)。RST 一般将文本的中心片段称为 核心(nucleus),文本的周边片段称为 外围(satellite),比如说下面的段落
第二个句子详细描述了(elaborate)第一个句子,解释了 carpenter 为什么会 tired。更明显的是第二个句子以代词 He 开头,对第一个句子的依赖性很强,相对来说句子重要性更低,所以第一个句子是 Nucleus,第二个句子是 Satellite。
Nucleus 和 Satellite 的关系
- The satellite increases the belief in the relation described in the nucleus
- Some relations have only a nucleus, others have two nuclei, yet others have on nucleus and one satellite
再看一组 RST 关系的定义
RST 是通过层级进行组合的,也就是说,我们可以采用一对相关文本作为其他高层关系的外围或者核心。和句法结构类似,这可以形成 discourse 的结构,可以看下几个例子,在下面的树里,代表一组局部连贯话段的节点被称为 discourse segment,相当于句法中的 consitute。
|
|
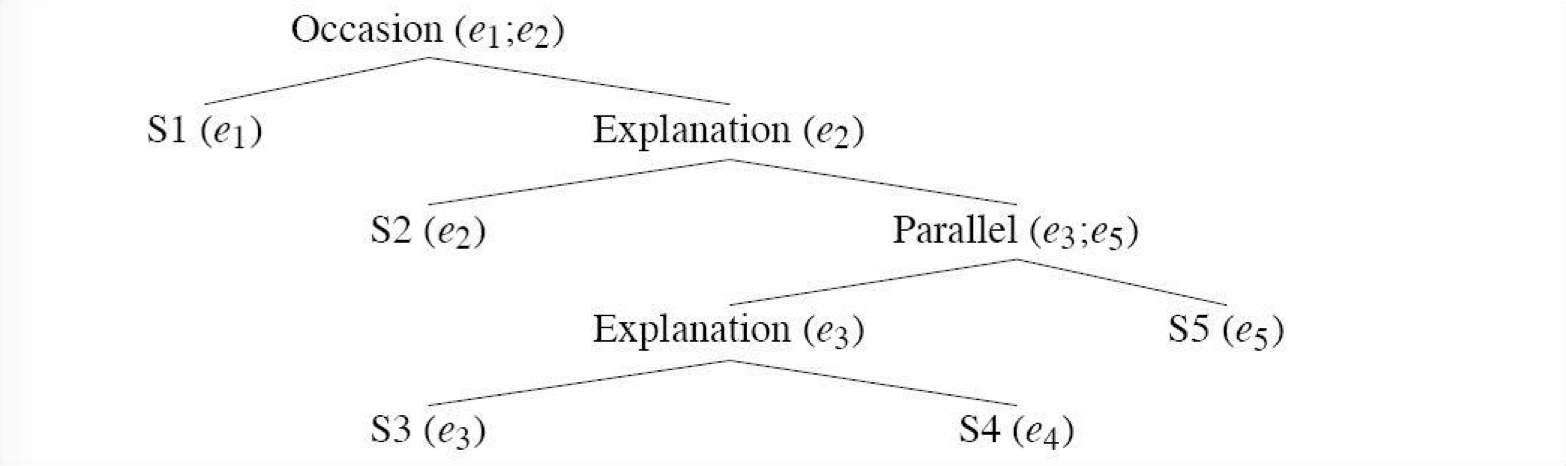
更多例子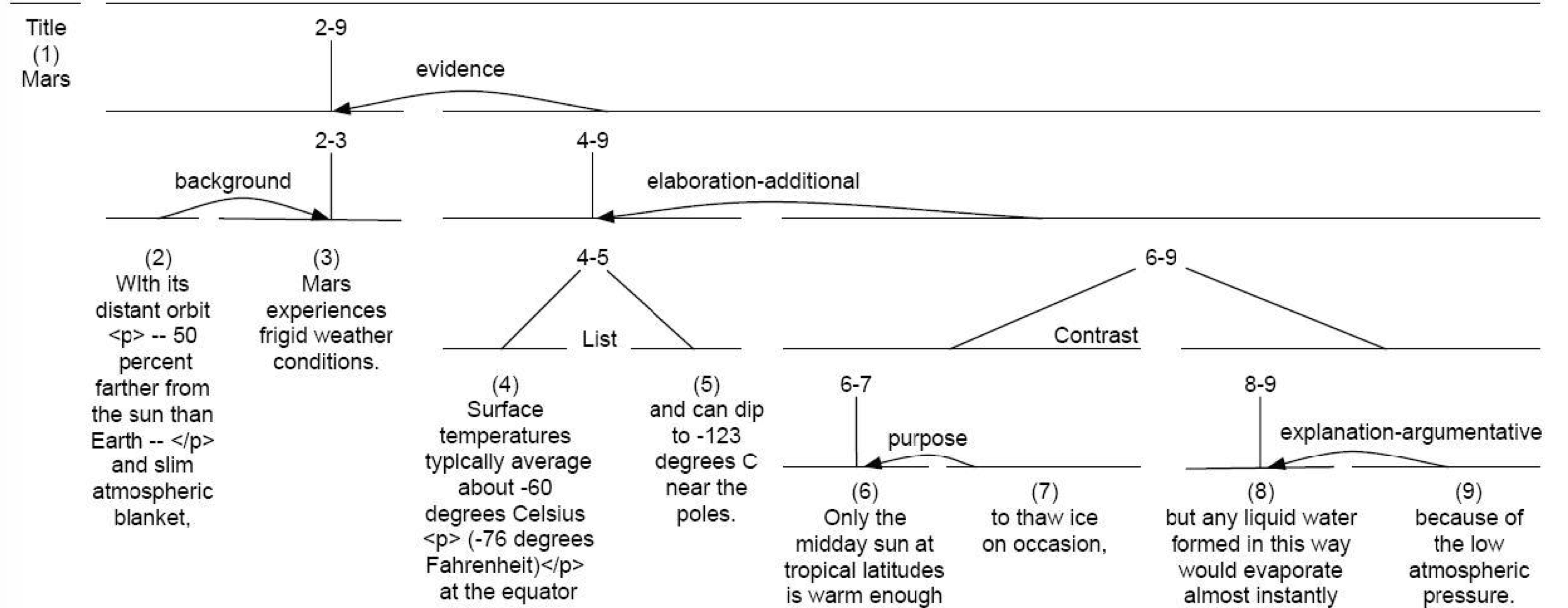
Automatic Coherence Assignment
给定句子/从句的序列,我们希望能自动的
- 决定句子之间的衔接关系(coherence relation assignment)
- 抽取能够表示整个 discourse 的树/图结构(discourse parsing)
Use cue phrases/discourse markers
Automatic Coherence Assignment 是一个很难的任务,现有的一种方法是利用线索型的短语(cue phrases),具体过程如下:
|
|
- Identify
识别文本中的 cue phrases,如第一句中的 because,第二句中的 similarly - Segment
将文本分成 discourse segments - Classify
对每组相邻的 discourse segment 进行关系分类
Marcu and Echihabi 2002 最早提出了关于文本结构的完全确定性的形式化模型,用无监督方法来自动识别 4 种 RST 关系(contrast, cause-explanation-evidence, condition, elaboration + non-relation),利用 Word co-occurrence,训练了 Naive Bayes 关系分类器,取得了不错的结果,论文值得一看,是当时 discourse analysis 的一个重大突破,不过这种模型过度依赖 cue phrases,匹配模式也很简单,只能对文本进行颗粒度较粗的分析。
除了 cue phrases/discourse markers,还可以利用的是推理关系。
Use abduction/defeasible inference
基于推理的判定算法主要是通过推理来约束连贯关系。之前在NLP 笔记 - Meaning Representation Languages中讲过取式推理(modus ponens),是演绎(deduction)的规则,也是 sound inference 的一种形式,如果前提为真,结论必为真。

然而很多 NLU 依赖的推理是不可靠的,比如说 abduction(溯因推理),中心规则如下:
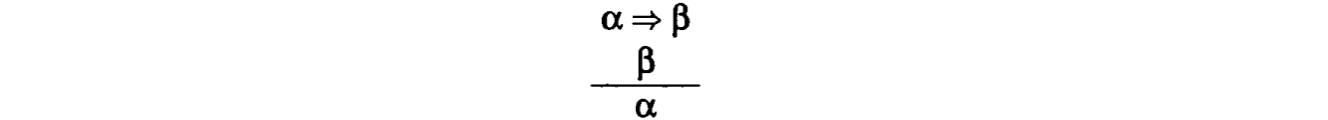
这其实相当于 Peter Lipton 说的 Inference to the Best Explanation(IBE),从结果中找最可能的原因。比如说我们知道 All Acuras are fast.,还知道 John’s car is fast,想来解释为什么 John’s car is fast,发现最合理的理由是 John’s car is an Acura。
|
|
然而这可能是一个不正确的推理,John 的汽车可能是由其他制造商生产同时速度很快。一个给定的结果 $\beta$ 可能会有很多潜在的原因 $\alpha$,要找到 BE,可以采用概率模型(Charniak and Goldman, 1988; Charniak and Shimony, 1990),或者启发式方法(Charniak and McDermott)。
下面看一个具体的例子,下面两个句子应该是 Explanation 的关系。
推理图: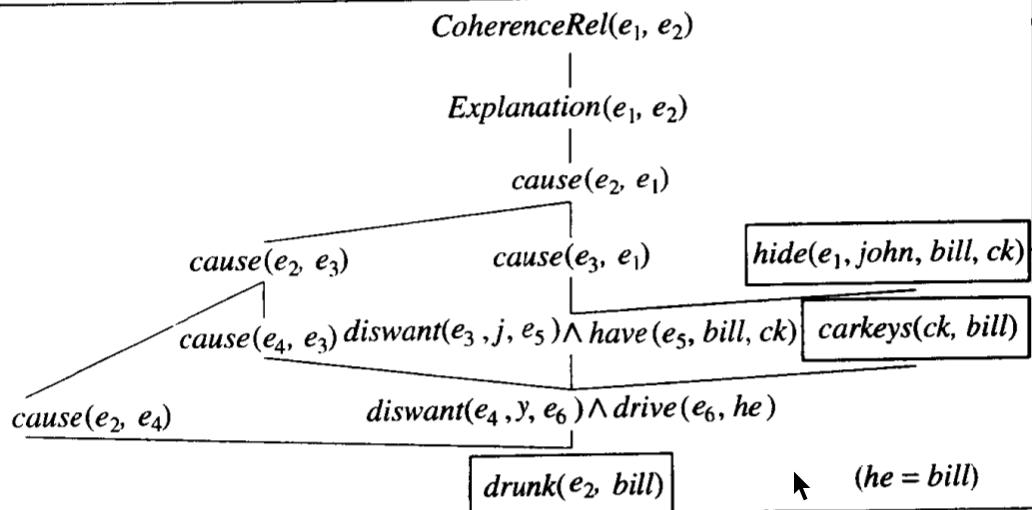
下面看一下具体的过程。首先需要关于 cohesion 本身的公理,表示要确定两个事件有连贯关系,一种可能性是假定两者是解释(explanation)关系
$∀ e_i, e_j \ Explanation(e_i, e_j) => CoherenceRel(e_i, e_j)$
然后是需要关于解释(explanation)的公理,要求第二个话段是第一个话段的原因
$∀ e_i, e_j \ cause(e_j, e_i) => Explanation(e_i, e_j)$
再然后是代表世界常识的公理,第一条,如果某人喝醉了,我们就不让他开车
$∀ x, y, e_i \ drunk(e_i, x) => ∃ e_j, e_k diswant(e_j, y, e_k) ∧ drive(e_k, x) ∧ cause(e_i, e_j)$
第二条,如果某人不想让其他人开车,那么他们就不愿意让这个人拿到他的车钥匙
$∀ x, y, e_j, e_k diswant(e_j, y, e_k) ∧ drive(e_k, x) => ∃ z, e_l, e_m diswant(e_l, y, e_m) ∧ have(e_m, x, z) ∧ carkeys(z, x) ∧ cause(e_j, e_l)$
第三条,如果某人不想让其他人拥有某件东西,那么他可以将东西藏起来
$∀ x, y, z, e_i, e_j diswant(e_l, y, e_m) ∧ have(e_m, x, z) => ∃e_n hide(e_n, y, x, z) ∧ cause(e_l, e_n) $
最后一个公理,原因是可传递的
$∀e_i, e_j e_k cause(e_i, e_j) ∧ cause(e_j, e_k) => cause(e_i, e_k)$
开始假设连贯关系是 explanation,根据公理最后能得到
$diswant(e_3, John, e_5) ∧ have(e_5, Bill, carkey)$
$diswant(e_4, John, e_6) ∧ drive(e_6, Bi)$
=> 推测出
$drunk(e_2, Bill)$
通过 coreference 可以把 he 和 Bill 绑定,这就确立了句子的连贯。然而要注意的是,Abduction 是非可靠的推理,是可废止的(defeasible)。比如说如果紧跟上面句子的下面的句子,那么我们不得不撤销连接之前两个句子的推理连,然后用事实(藏钥匙是恶作剧的一部分)来替代。
|
|
Discourse Segmentation
还有一个任务是 discourse segmentation,目标是将文本切分为一个子话题(subtopics)的线性序列,比如说

常用的方法是 TextTiling,通过词汇层面的共现和分布模式(lexical co-occurrence and distribution)来寻找 subtopic 的边界。它的假设是认为描述 subtopic 的词会局部共现,从一个 subtopic 到另一个 subtopic 的 switch 以一个共现词集合的结束和另一个共现词集合的开始为标志。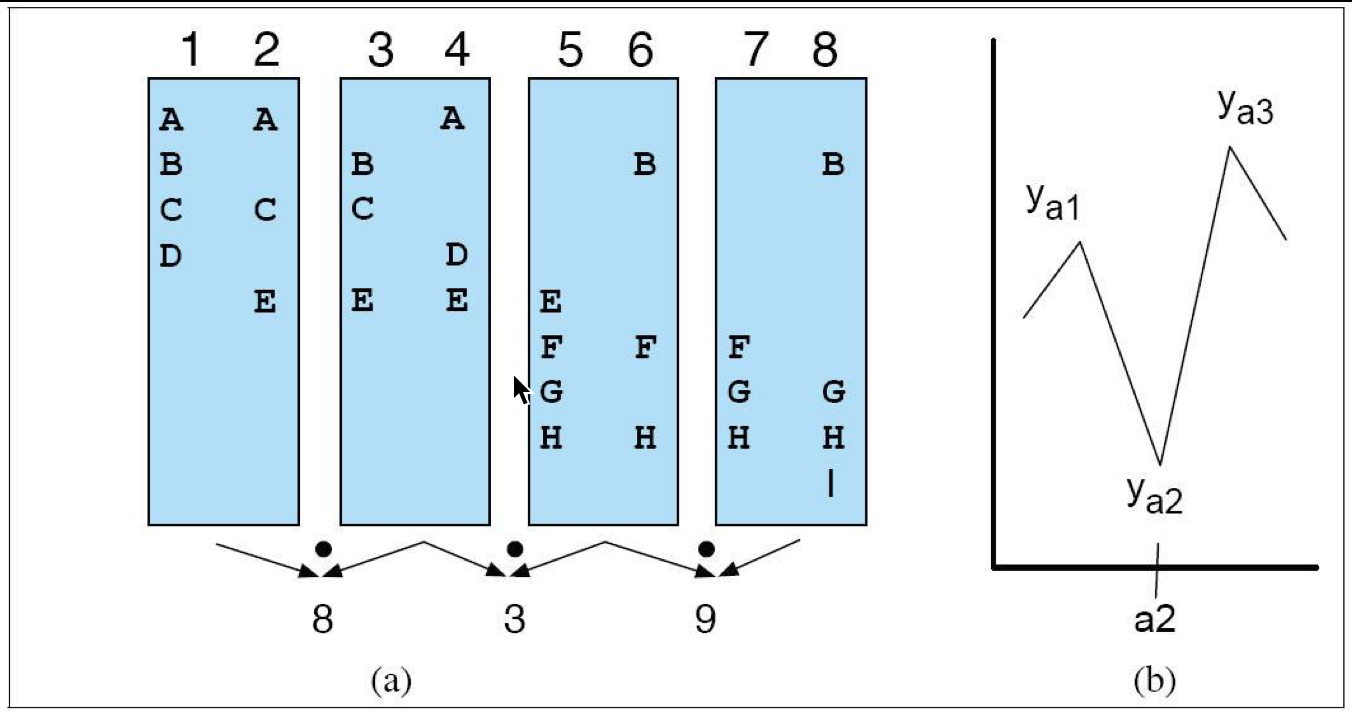
步骤:
- Tokenization
进行 tokenization 得到 ABCDE 等 term 以及以句子为单位的词汇单元(sentence-sized units),如上图 1-8,每一列都是一个 unit - Lexical score determination
方法有 blocks, vocabulary introductions 和 chains
上图表示 blocks 方法,把 k 个句子 group 成 block (一般 K=2),计算 block lexical score,一般就是向量內积,比如第一个 block 的 score 就是 8=2x1(for A)+1x1(for B)+2x1(for C)+1x1(for D)+1x2(for E)
Block 其实就相当于一个 moving window - Boundary identification
如果一个较低的 lexical score 前面和后面都跟着一个高的 lexical score,那么较低的 lexical score 所在的位置可能就代表了一个 shift,或者说 subtopic change
更多戳论文TextTiling: A Quantitative Approach to Discourse Segmentation
另外还有监督学习的方法,可以训练一个 binary classifier,在句子之间放个 marker,标注这是不是 discourse boundary,使用到的 feature 有
Context, Speech Acts
最后来看一下 context 和 speech acts。
Context
同一个句子在不同的情境(context)下的含义可能是不同的。需要考虑的情境:
- Social context
Social identities, relationships, and setting - Physical context
Where? What objects are present? What actions? - Linguistic context
Conversation history - Other forms of context
Shared knowledge, etc.
Speech Acts
A speech act in linguistics and the philosophy of language is an utterance that has performative function in language and communication.
语言行为理论(Speech Acts)最初由语言哲学家 Austin 提出,后来由其学生 Searle 进一步发展。核心理论是 Sentences perform actions,说话人只要说出了有意义的,可以被听众理解的话,就可以说他实施了某个行为,这个行为就是 Speech Act。
Austin
Austin 最初把言语分为两类,言有所述(constatives)和言有所为(performatives)。判断一个句子是不是 performative 的方法是加上 hereby 来验证,如果句子依然通顺,这个句子就含有 performative verb。
加上 hereby 之后,上面的句子依旧 make sense,然而下面这两个句子就不能
然而后来 Austin 发现用 hereby 来判读一个句子是不是有 performative 有点牵强,于是提出了一个新的模式,一个人说话的时候,同时实施了三种行为,言内行为(locutionary act), 言外行为(illocutionary act), 和言后行为( perlocutionary act)
- Locuion: say some words
通过说话表达字面意义,包括说话时所用的发出的语音、音节、单词、短语、句子 - Illocution: an action performed in saying words
通过字面意义表达说话人的意图,比如说发出命令
Ask, promise, command - Perlocution: an action performed by saying words, probably the effect that an illocution has on the listener.
说话人的话语作用在听众身上所带来的效果
Persuade, convince, scare, elicit an answer, etc.
Searle
Searle进一步说明了人类交际的基本单位不是句子或其他任何表达手段,而是完成一定的行为,并提出了言外行为的几个分类

同时提出了间接言语行为理论(indirect speech acts),通过某一个言语行为来做另一个言外行为,比如陈述句不是陈述,祈使句不是祈使,疑问句不是疑问的情况等。
Indirect speech acts:
应用
Speech acts 的主要应用应该是对话系统,如下面是任务导向型对话系统的 speech acts 示例

谈判的 speech acts

