持续填坑中– NLP 笔记 - Machine Translation主要讲了机器翻译的传统方法,这一篇介绍基于深度学习的机器翻译方法。
本文涉及的论文原文:
- Bengio et al. (2003), A Neural Probabilistic Language Model
- Devlin et al. (2014), Fast and Robust Neural Network Joint Models for Statistical Machine Translation
- Sutskever et al. (2014), Sequence to Sequence Learning with Neural Networks
- Bahdanau et al. (2014), Neural Machine Translation by Jointly Learning to Align and Translate
- Xu et al. (2015) Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. ICML’15
- Luong et al. (2015)Effective approaches to attention based neural machine translation
Neural MT
Neural MT(NMT)的定义:
Neural Machine Translation is the approach of modeling the entire MT process via one big artificial neural netowrk.
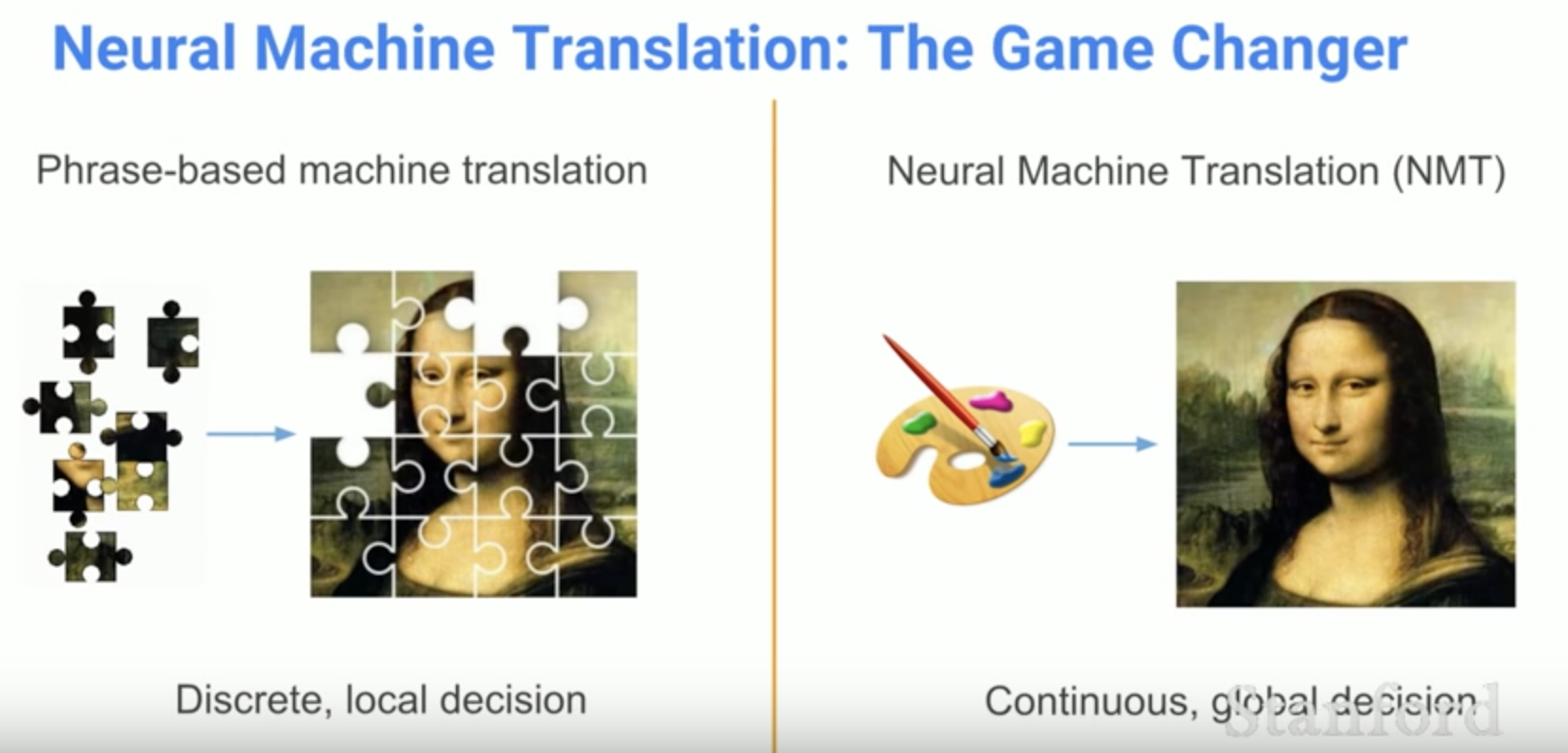
用一个大的神经网络来给整个机器翻译的过程建模,目前主流的结构是 Neural encoder-decoder architectures,最基本的思想是 encoder 将输入文本转化为一个向量, decoder 根据这个向量生成目标译文,编码解码开始均用 RNN 实现,由于普通 RNN 存在梯度消失/爆炸的问题,通常会引入 LSTM。本篇会介绍 NMT 发展的一些重要节点。
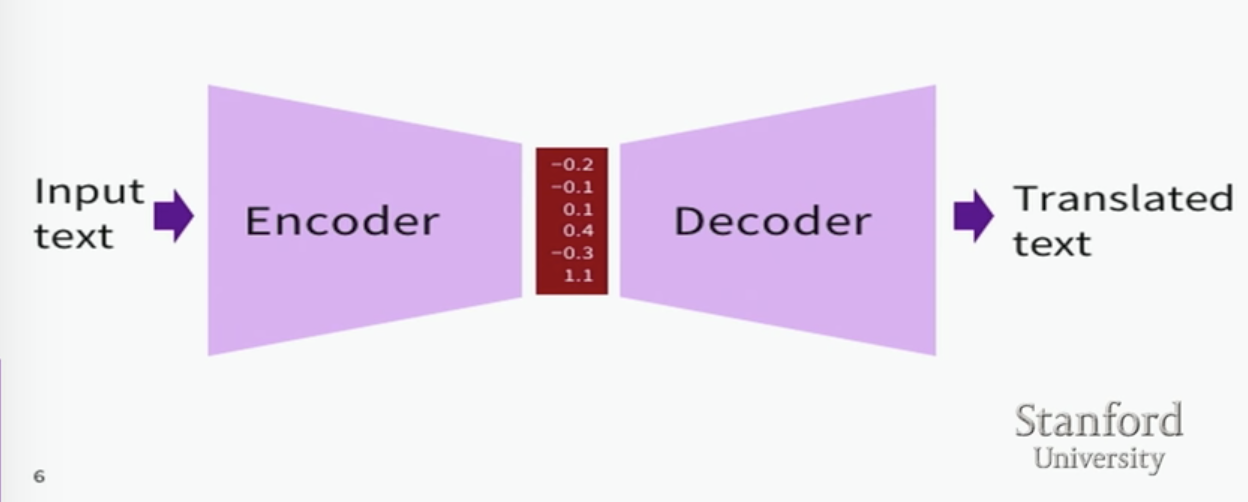
一句话解释 encoder-decoder architectures: Encoder compresses input series into one vector Decoder uses this vector to generate output
Big wins of Neural MT
- End-to-end training
所有参数同时被训练优化 - Distributed representations share strength
分布式表达更好的挖掘了单词/词组之间的相似性 - Better exploitation of context
可以使用更广泛的上下文,无论是 source 还是 target text - More fluent text generation
生成的文本质量更高
But…
Concerns
- Black box component models for reordering, transliteration, etc.
- Explicit use of syntactic or semantic structures
没有显性的用到句法/语义结构特征 - Explicit use of discourse structure, anaphora, etc.
没法显性利用指代消解之类的结果
NNLM: Bengio et al. (2003)
A Neural Probabilistic Language Model,这篇论文为之后的 NMT 打下了基础。
传统的 Language model 有一定缺陷:
- 不能把 ngram 中 n 以外的词考虑进去
n 越大句子连贯性越好,但同时数据也就越稀疏,参数也越多 - 不能考虑单词之间的相似度
不能从 the cat is walking in the bedroom 学习到 a dog was running in a room
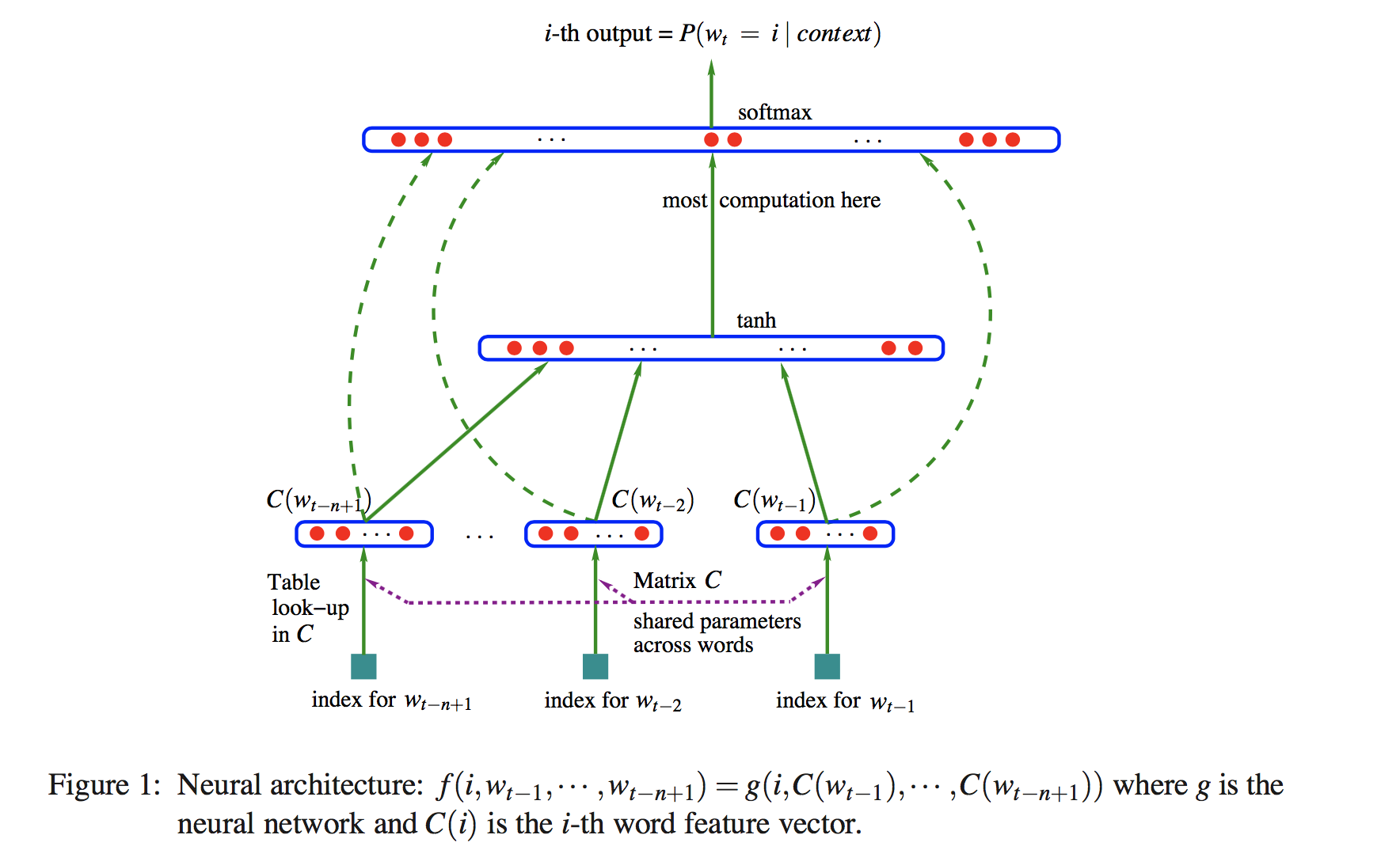
Neural network language model(NNLM) 可以解决上面的两个问题。主要理解上图,先来定义一些参数:
h: number of hidden units
m: number of features associated with each word
b: output biases, with |V| elements
d: hidden layer biases, with h elements
V: word dictionary $w_1, …w_T \in V$
U: hidden-to-output weights, |V|*h matrix
W: word features to output weights, |V|*(n-1)m matrix
H: hidden layer weights, h*(n-1)m matrix
C: word features C, |V|*m matrix
再来看一下目标函数:
$$f(w_t,…,w_{t-n+1})=\hat P(w_t|w_1^{t-1})$$
目标函数包含了两个部分
- Matrix C,用来 map word_id 和 word feature vector,维度是 |V|*m
- g,用来 map 这个上下文输入的 feature vector 和下一个单词 $w_t$ 在 V 上的条件概率的分布,g 用来估计 $\hat P(w_t=i|w_1^{t-1})$
$$f(i, w_{t-1},…,w_{t-n+1})=g(i,C(w_{t-1}),…,C(w_{t-n+1}))$$
也就是说 f 是两个 mapping C 和 g 的组合,词向量矩阵 C 所有单词共享。模型有两个 hidden layer,第一部分的输入是上下文单词 $w_{t-1},…w_{t-n+1}$ 的 word_id,每个 word_id 在 C 中寻找到对应的 word vector,vector 相加得到第二部分的输入, 与 H 相乘加一个 biases 用 tanh 激活,然后与 U 相乘产生一个得分向量,再进入 softmax 把得分向量转化成概率分布形式。
前向传播的式子就是:
$$y=b+Wx+Utanh(d+Hx)$$
其中 x 是 word features layer activation vector,由输入词向量拼接而成
$$x(C(w_{t-1}), C(w_{t-1}), …, C(w_{t-n+1}))$$
最后的 softmax 层,保证所有概率加和为 1
$$\bar P(w_t|w_{t-1},…,w_{t-n+1})={e^{y_{w_t}} \over \sum_ie^{y_i}}$$
通过在训练集上最大化 penalized log-likelihood 来进行训练,其中 $R(\theta)$ 是正则项,如下
$$L={1 \over T}\sum_tlogf(w_t,w_{t-1},…,w_{t-n+1;\theta})+R(\theta)$$
用 SGD 梯度下降来更新 U 和 W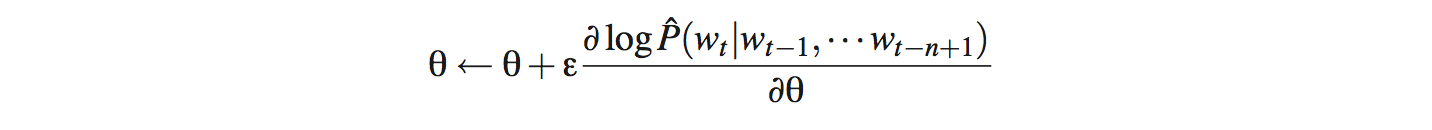
参数集合$\theta = (b,d,W,U,H,C)$,参数量: |V|(1+mn+h)+h(1+(n-1)m),dominating factor 是|V|(nm+h)
最后提一下两个改进,一个是加上图中的曲线部分,直接把词向量和输出连接起来(direct connections from the word features to the output),另一个是和 ngram 相结合的 mixture model。看一下在 Brown Corpus 上的评估结果:
- n-gram model(Kneser-Ney smoothing): 321
- neural network language model: 276
- neural network + ngram: 252
NNJM: Devlin et al. (2014)
Fast and Robust Neural Network Joint Models for Statistical Machine Translation,把 Bengio et al. (2003) 的 model 转化为一个 translation model,简单来说就是把 n-gram target language model 和 m-word source window 相结合,来创建一个 MT decoding feature,可以简单的融入任何的 SMT decoder。
Neural Network Joint Models(NNJM)
条件概率模型,generate the next English word conditioned on
- The previous n English words you generated $e_{i-1}, e_{i-2}…$
- The aligned source word and its m neighbors $…f_{a_i-1}, f_{a_i}, f_{a_i-2}…$
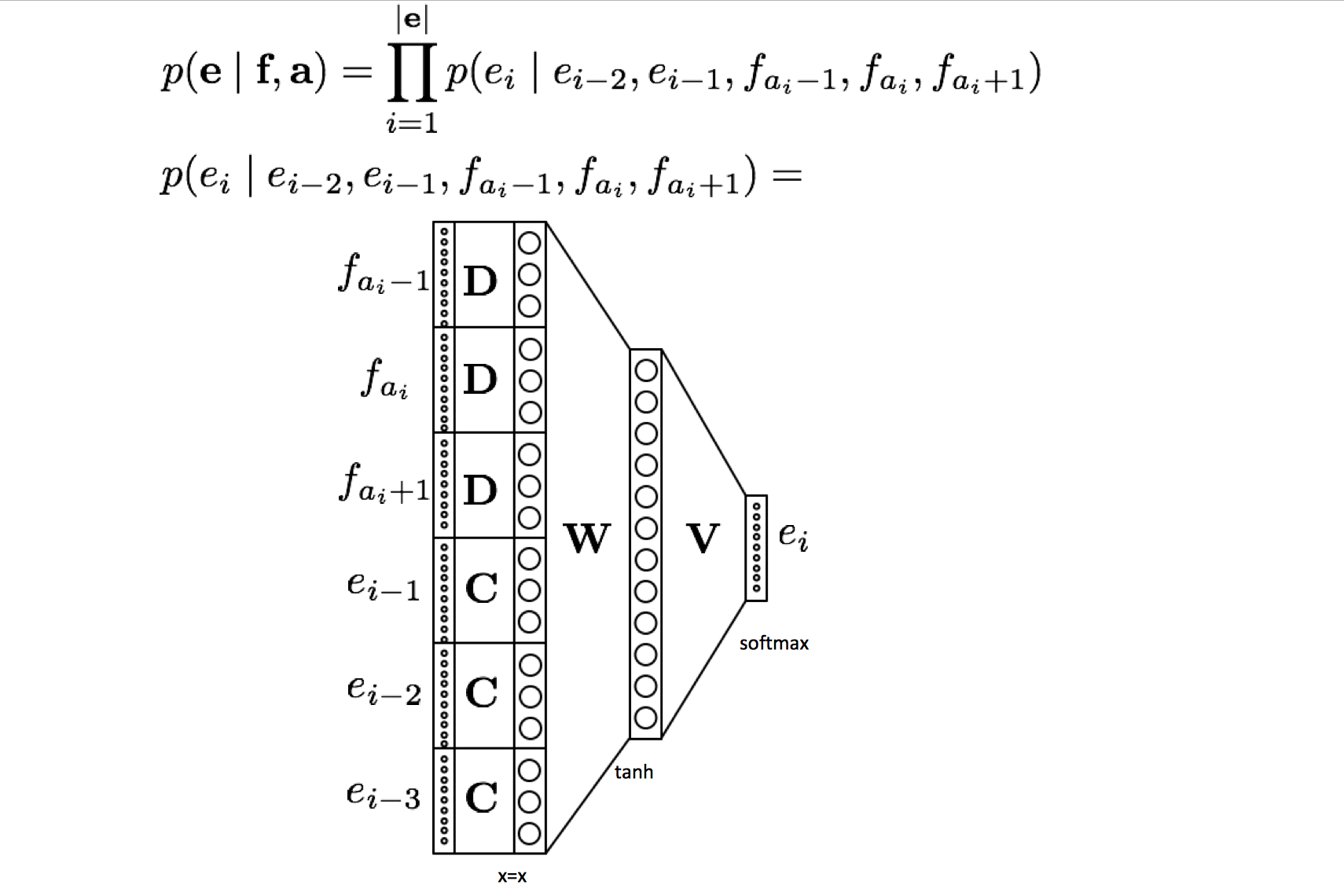
$$P(T|S) \approx \prod^{|T|}_{i=1}P(t_i|t_{i-1},…,t_{i-n+1}, S_i)$$
假设 target word $t_i$ 只和一个 source word $a_i$ 对齐,我们会关注 source 句子里以 $a_i$ 为中心的一个 window $S_i$,也就是和 target $t_i$ 最相关的 source part。
$$S_i = s_{a_i-{m-1 \over 2}},…,s_{a_i},…,s_{a_i+{m-1 \over 2}}$$
1) 如果 $e_i$ 只和一个 source word 对齐,那么 $a_i$ 就是对齐的那个单词的 index
2) 如果 $e_i$ 和多个 source word 对齐,那么 $a_i$ 就是在中间的那个单词的 index
3) 如果 $e_i$ 没有对齐的 source word,那么就继承最邻近(右边)的 aligned word 的 affiliation
affiliation 用先验的基于规则的 word alignment 来推。
模型的训练过程和 NNLM 相似,不过是多了个 corpus 而已。最大化训练数据的 log-likelihood
$$L=\sum_ilog(P(x_i))$$

Self-normalization
论文还提出了一种训练神经网络的新方法 – self-normalized 技术。由于训练的 cost 主要来自输出层在整个 target vocabulary 上的一个 softmax 计算,self-normalization 用近似的概率替代实际的 softmax 操作,思路很简单,主要改造一下目标函数。先来看一下 softmax log likelihood 的计算:
想象一下,如果 $log(Z(x))=0$,也就是 $Z(x)=1$,那么我们就只用计算输出层第 r 行的值而不用计算整个 matrix 了,所以改造下目标函数,变成
$$
\begin{aligned} \
L =\sum_i[log(P(x_i))-\alpha(log(Z(x_i))-0)^2] \\
& =\sum_i[log(P(x_i))-\alpha log^2(Z(x_i))] \\
\end{aligned}
$$
output layer bias weights 初始化为 log(1/|V|),这样初始网络就是 self-normalized 的了,decode 时,只用把 $U_r(x)$ 而不是 $log(P(x))$ 作为 feature score,这大大加快了 decoding 时的 lookup 速度(~15x)。其中 $\alpha$ 是一个 trade-off 参数,来平衡网络的 accuracy 以及 mean self-normalization error
其他优化如 pre-computing the (first) hidden layer 等。
Variations
MT decoder 有两类,一个是 decoder方法,用的是 string-to-dependency hierarchical decoder (Shen et al., 2010),一个是 1000-best rescoring 方法,用的 feature 是 5-gram Kneser-Ney LM,Recurrent neural network language model (RNNLM) (Mikolov et al., 2010)
不同模型的影响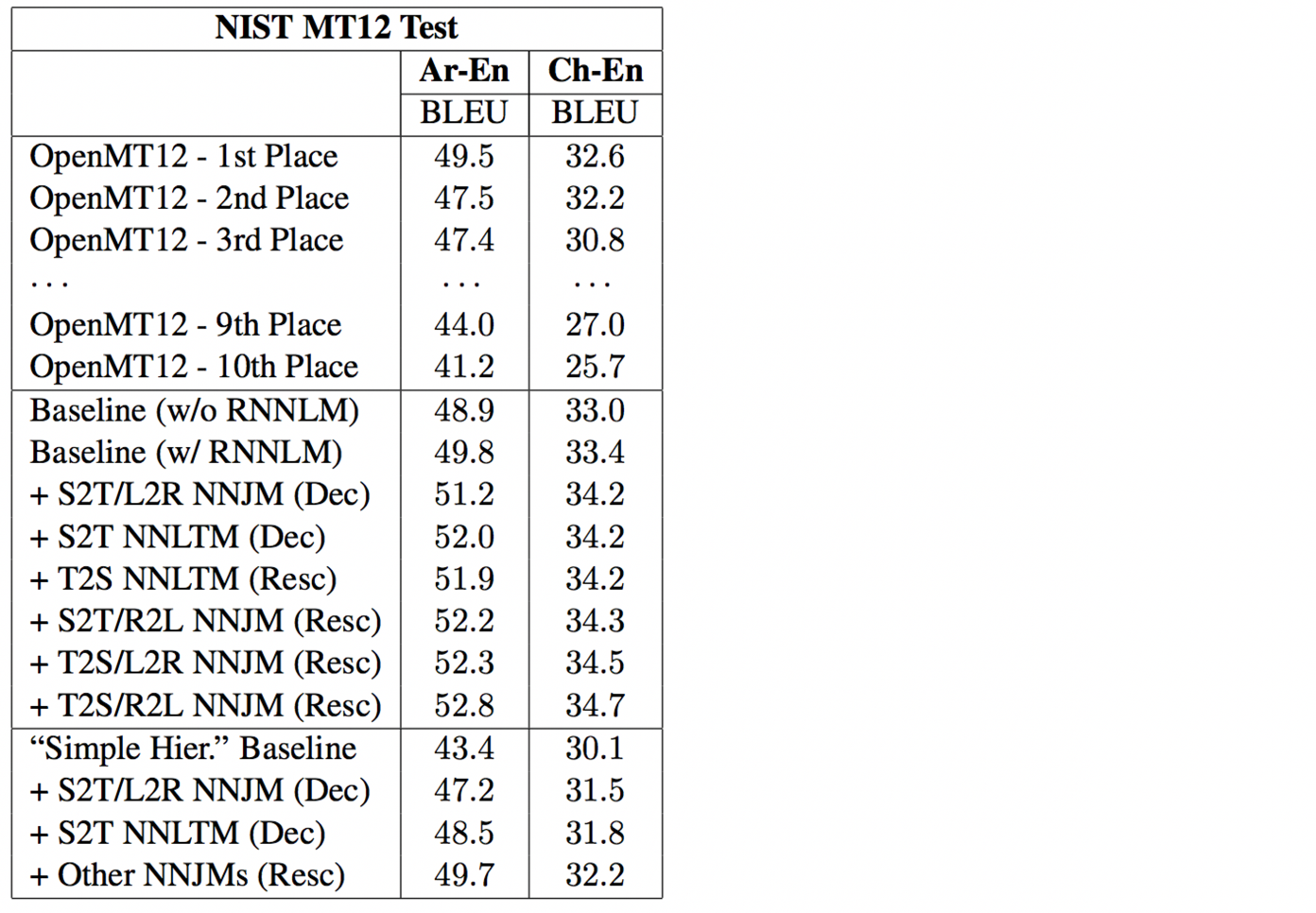
网络设置的影响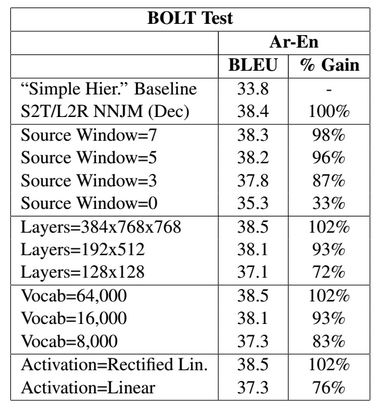
模型还有一些变种比如说翻译方向(source-to-target S2T, target-to-source T2S),language model 的方向(left-to-right L2R, right-to-left R2L),NNTM(Neural Network Lexical Translation Model),对 many-to-one 问题用 NULL 解决,对 one-to-many 问题用 token concatenated 解决,训练和评估与 NNJM 相似。
Sutskever et al. (2014)
Sequence to Sequence Learning with Neural Networks
使用了 encoder-decoder 框架,用多层的 LSTM 来把输入序列映射到一个固定维度的向量,然后用另一个深层的 LSTM 来 decode 这个向量,得到 target sequence,第二个 LSTM 实际上就是一个 NNLM 不过 conditioned on input sequences。主要的改变:
- fully end-to-end RNN-based translation model
- two different RNN
encode the source sentence using one LSTM
generate the target sentence one word at a time using another LSTM - reverse the order of the words in all source sentence(but not target sentences)
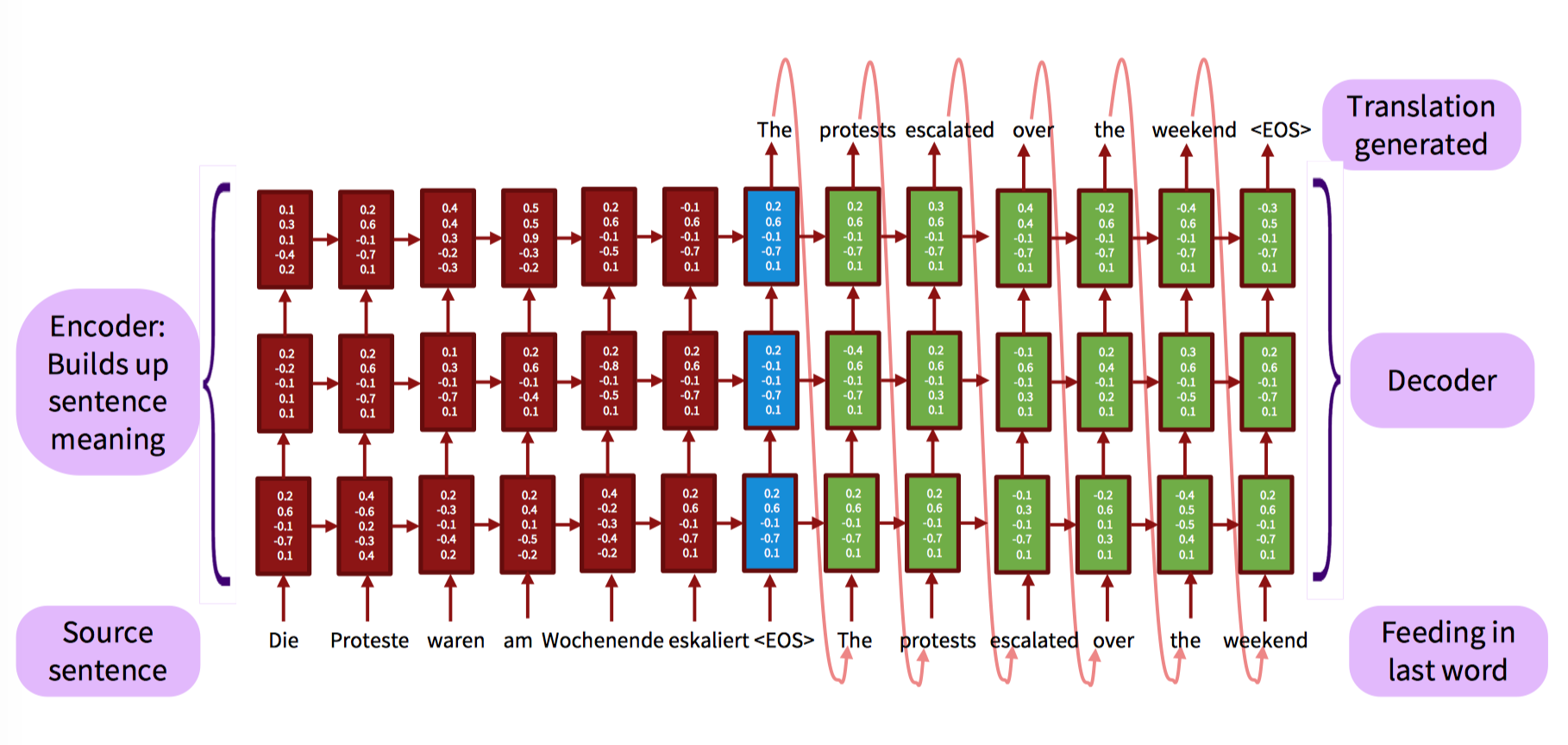
Encoder可以看作是一个 conditional language model (Bengio et al. ,2003) ,对原始句子,每个词用相应向量表示,每个词都有一个隐含状态 h1,代表这个词以及这个词之前的所有词包含的信息,当找到句尾标记的时候,对应的隐状态也就是 encoder 层的最后一个隐状态就就代表了整个句子的信息。
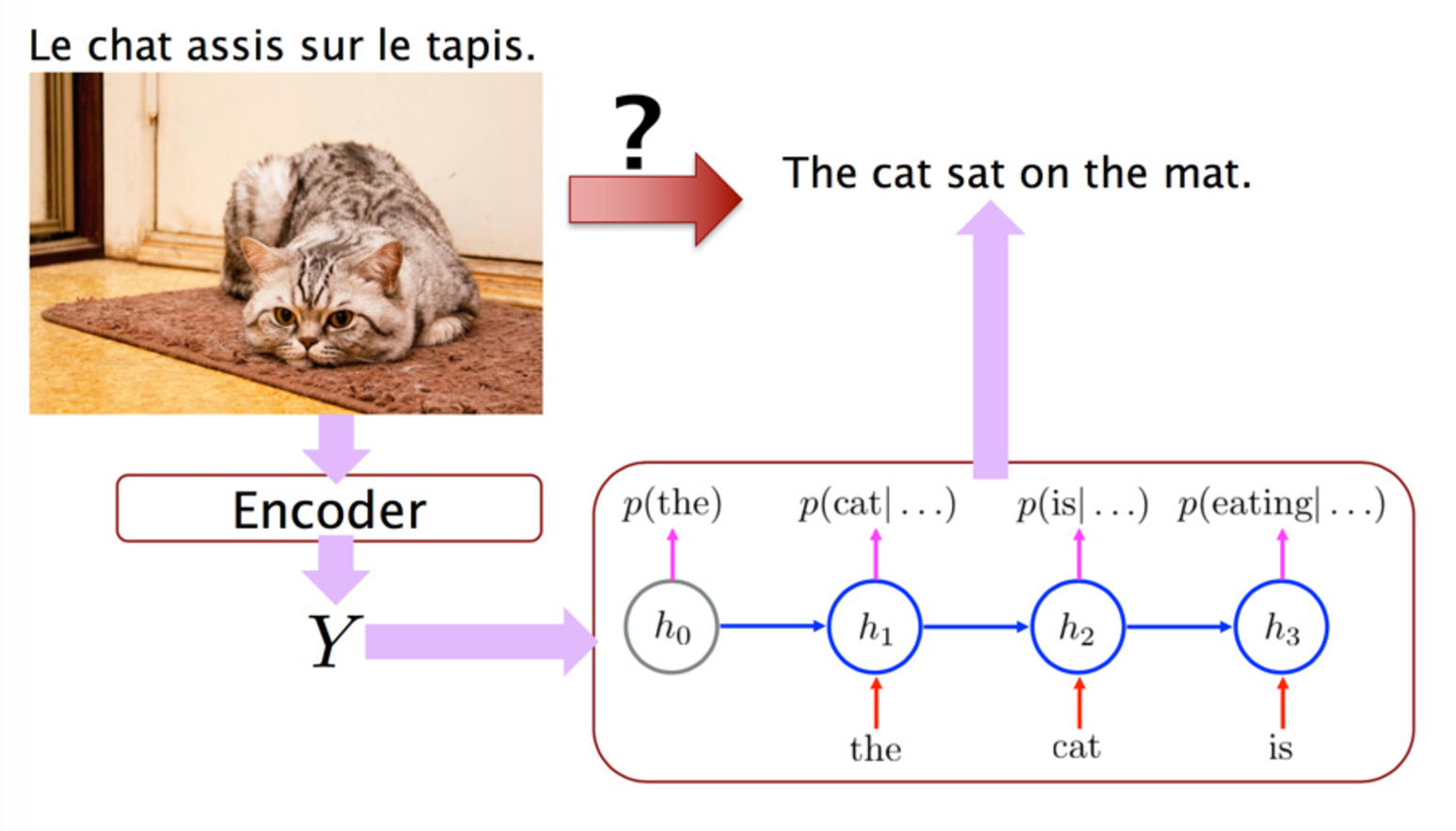
然后 decoder 对其进行解码,encoder 最后一层(最后一个时刻)作为 decoder 第一层,LSTM 能保持中期的记忆,那么解码层的每个隐状态,都包含了已经翻译好的状态以及隐状态,然后输出每个词。具体过程如下图: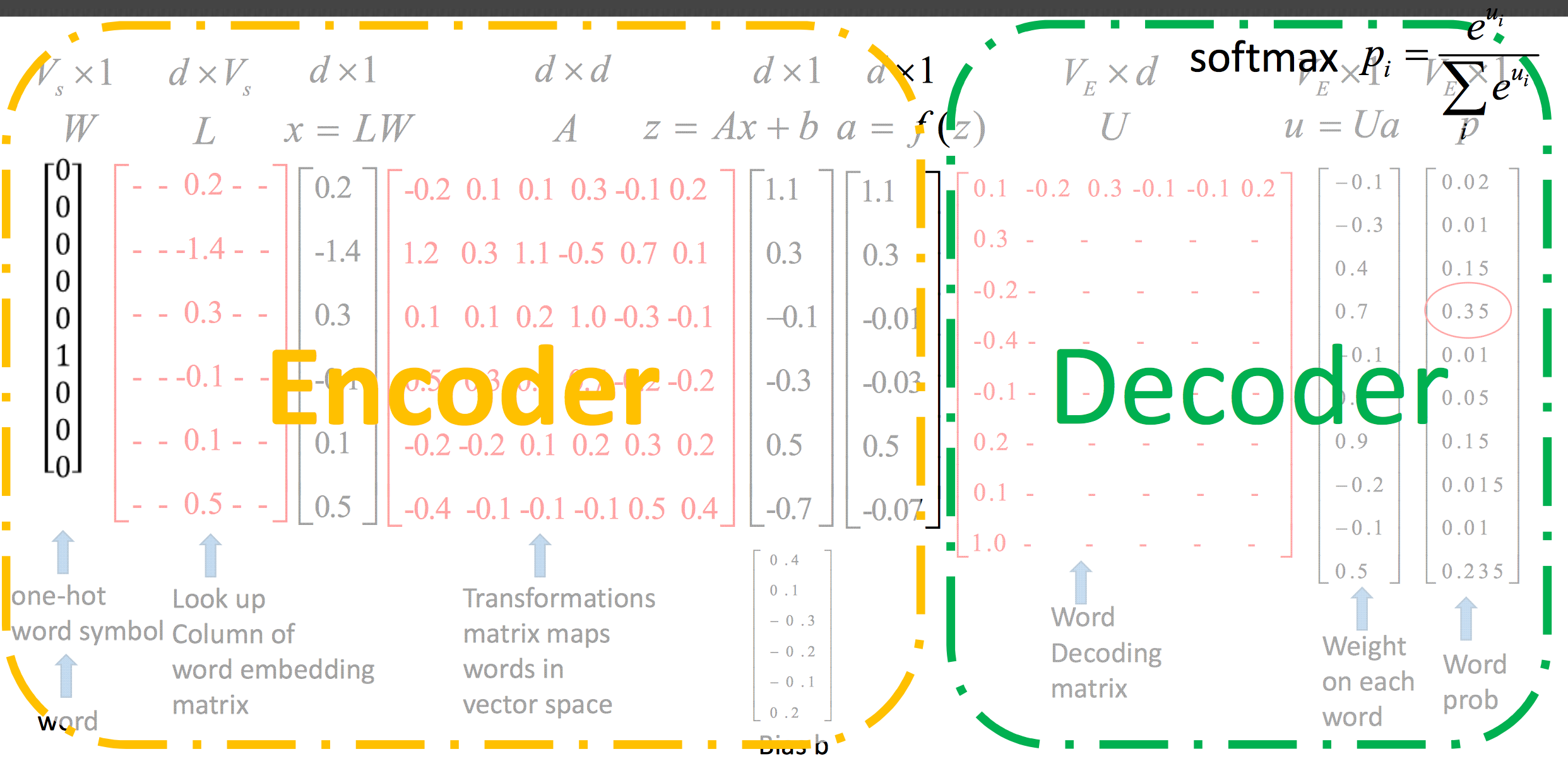
将输入序列倒转喂给 LSTM,能够在 source 和 target 句子间引入许多 short-term dependencies,使得优化问题更加容易。
recurrent activation function 可以使用:
- Hyperbolic tangent tanh
- Gated recurrent unit [Cho et al., 2014]
- Long short-term memory [Sutskever et al., 2014]
- Convolutional network [Kalchbrenner & Blunsom, 2013]
主要的贡献
- hard-alignment => soft-alignment
- 对长句的泛化能力很好
- 简单的 decoder
关于 Decoder,论文 baseline 用了 rescoring 1000-best 的策略,实验用了一个 left-to-right beam search decoder 结果有一定提升。
还可以提一句的是,另一种做法是把 encoder 的最后一层喂给 decoder 的每一层,这样就不会担心记忆丢失了。
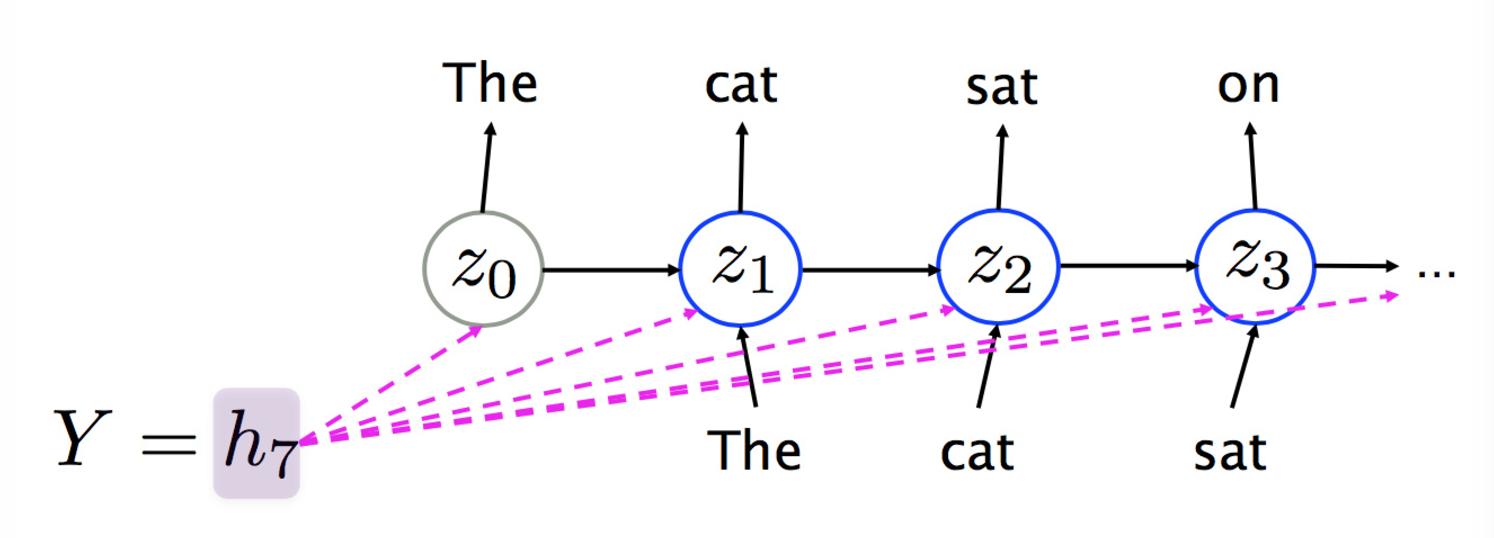
乱入:Decoders
在模型能计算 P(T|S) 后,问题来了,怎样才能找出最可能的译文 T 呢?
$$\bar T = argmax_T(P(T|S))$$
Exhaustive Search
最开始的想法当然是生成所有翻译,然后用 language model 打分,挑概率最大的了。BUT!! DO NOT EVEN THINK OF TRYING IT OUT!!!译文数量是词表的指数级函数,这还用想么?!
Ancestral Sampling
$$x ~ P(x_t|x_1,…,x_n)$$
多次取 sample。然而实践中会产生高方差的结果,同一个句子每次翻译结果都不一样,不大好吧?
Greedy Search
$$x_t=argmax\hat x_tP(\hat x_t|x_1,…,x_n)$$
每次选取当前最可能的那个单词,然而,这显然不能达到全局最优,每一步都会影响到后面的部分。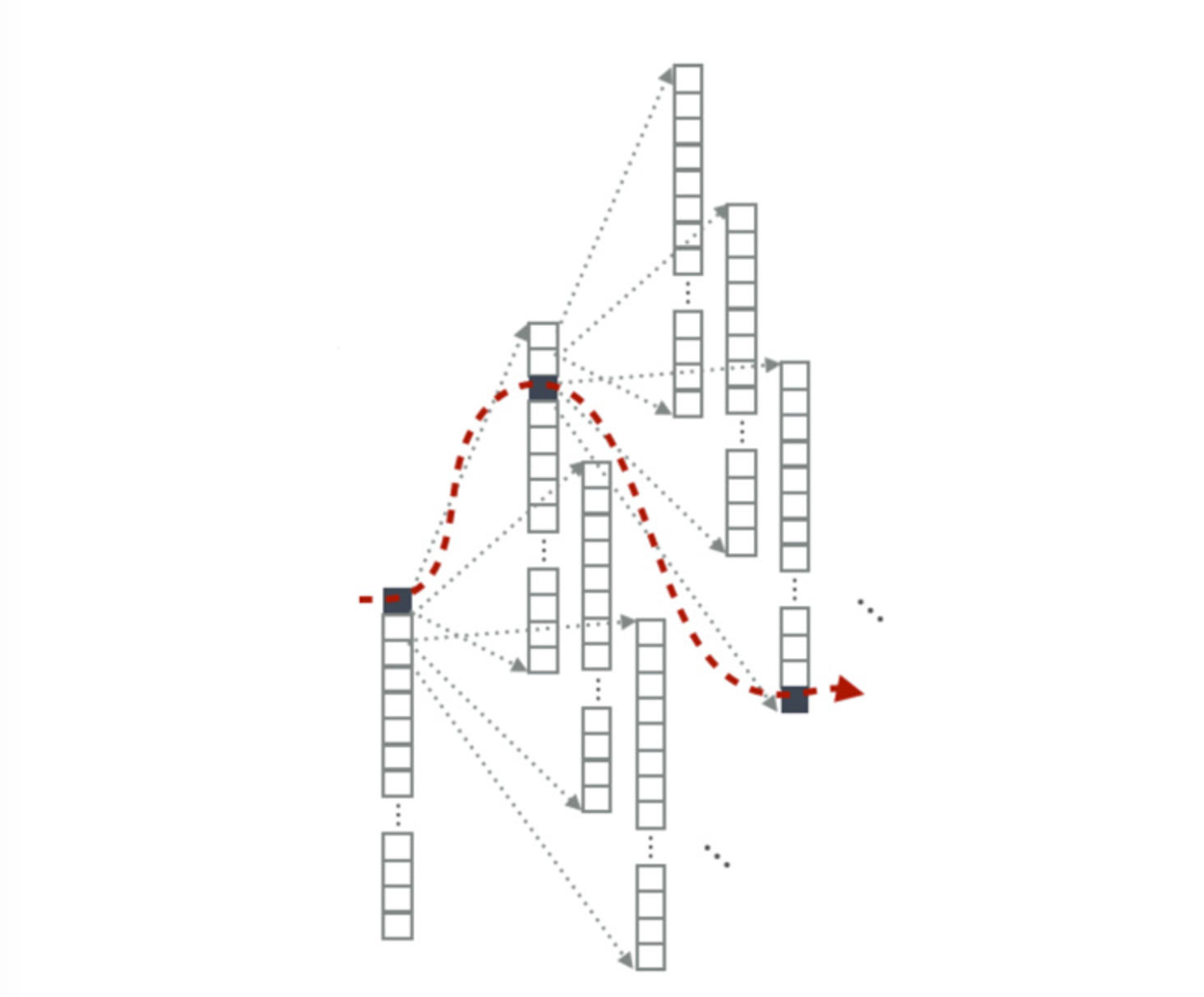
Beam Search
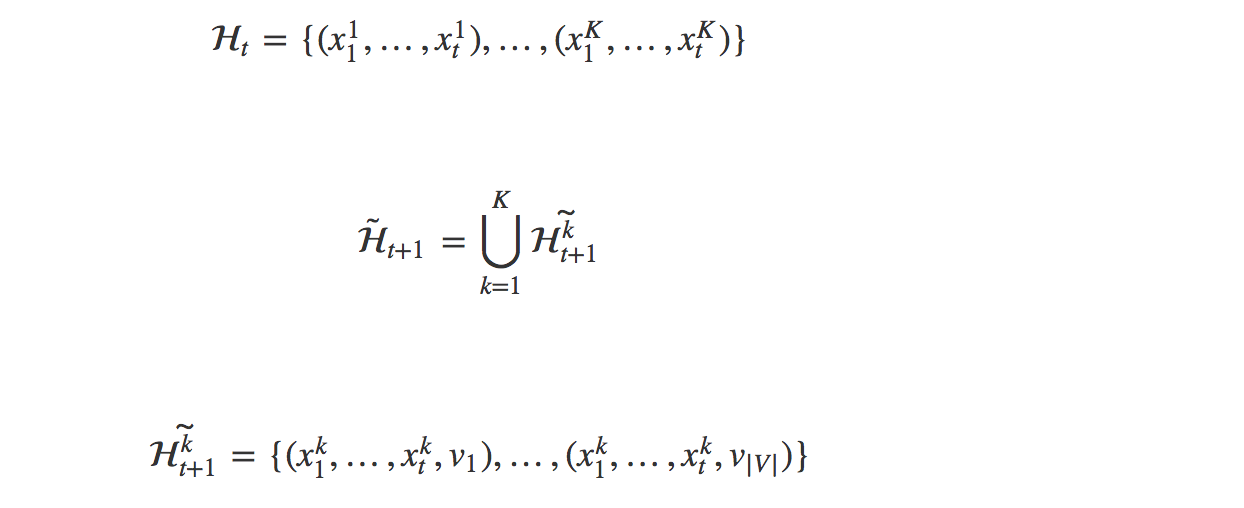
每个时刻记录 k 个最可能的选项,相当于剪枝,然后在这些选项中进行搜索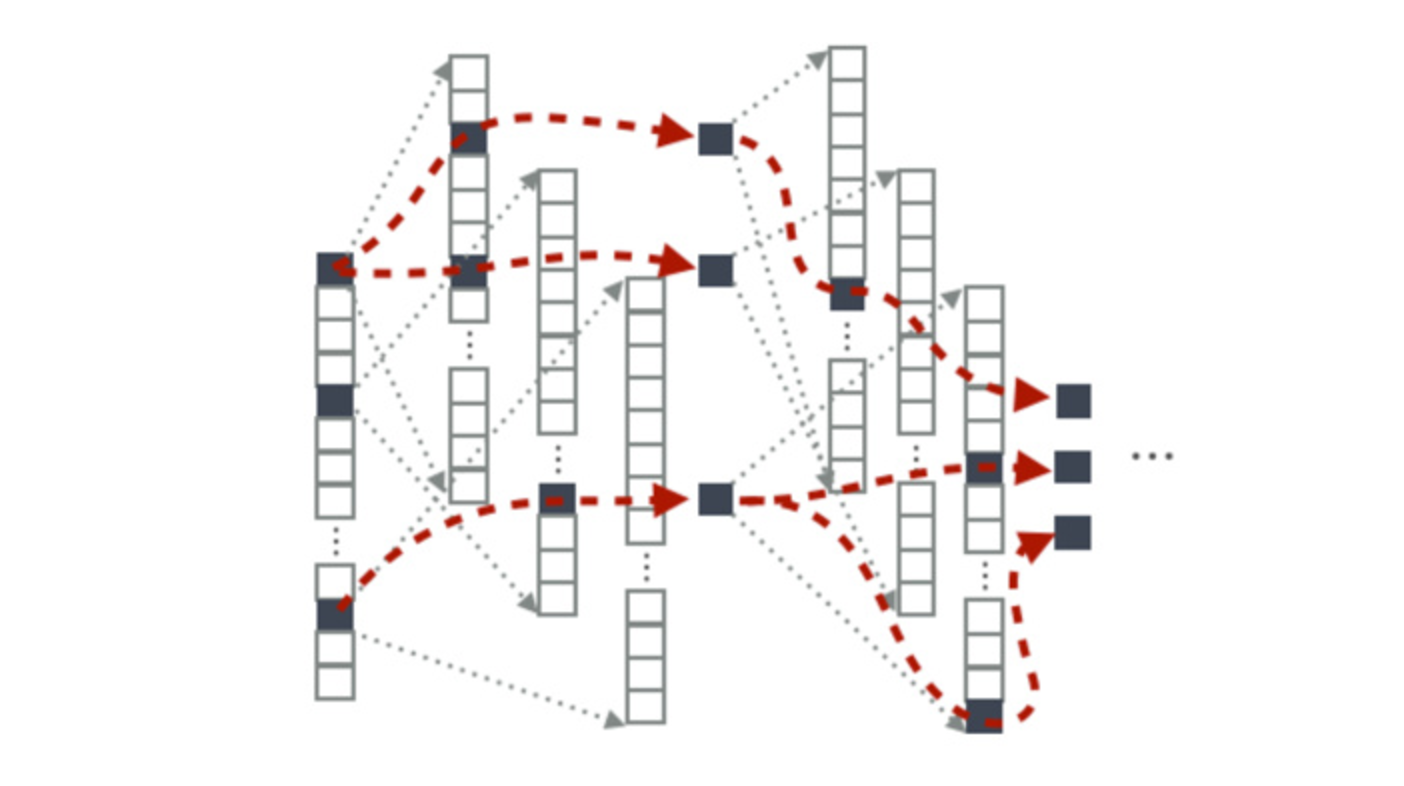
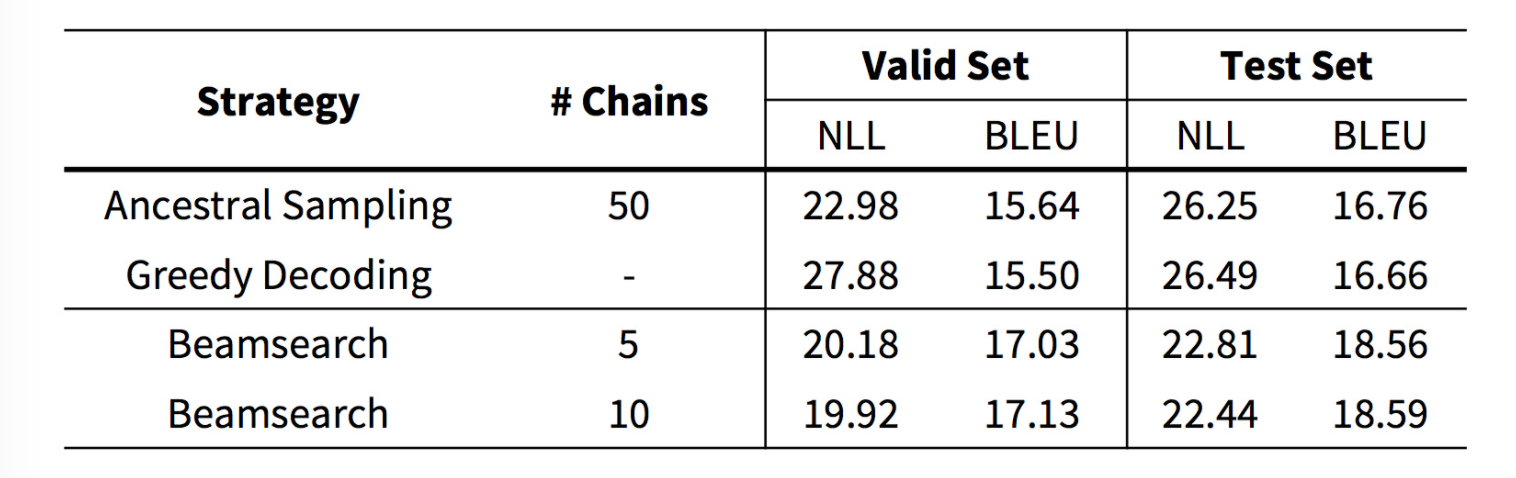
Results
Attention: Bahdanau et al. (2014)
Neural Machine Translation by Jointly Learning to Align and Translate,之前的 encoder-decoder 模型是将 source sentence 编码成一个固定长度的 vector,然后 decoder 产生 target sentence,这就要求 neural network 要能够把 source sentence 所有必要信息都压缩到一个 fixed-length vector 里,这对长句并不友好。我们希望在产生一个 target word 的时候只关注部分的 source word。这一篇提出了一个自动搜寻这样一个要关注的 source word window 的方法,换句话说,每次产生一个单词时,模型会从 source sentence 中搜索到相关信息所在的位置,基于包含了这些位置特征的 context vector 和 previous generated words,来生成下一个单词。这也就是注意力模型在机器翻译中的应用。
一句话解释: Attention Mechanism predicts the output $y_t$ with a weighted average context vector $c_t$, not just the last state
再通俗一点理解,attention 的作用可以看作是一个对齐模型,传统 SMT 我们用 EM 算法来求解对齐,这里做一个隐式的对齐,将 alignment model 用一个 feedforward neural network 参数化,和其他部分一起训练,神经网络会同时来学习 翻译模型(translation) 和 对齐模型(alignment)。
attention 效果: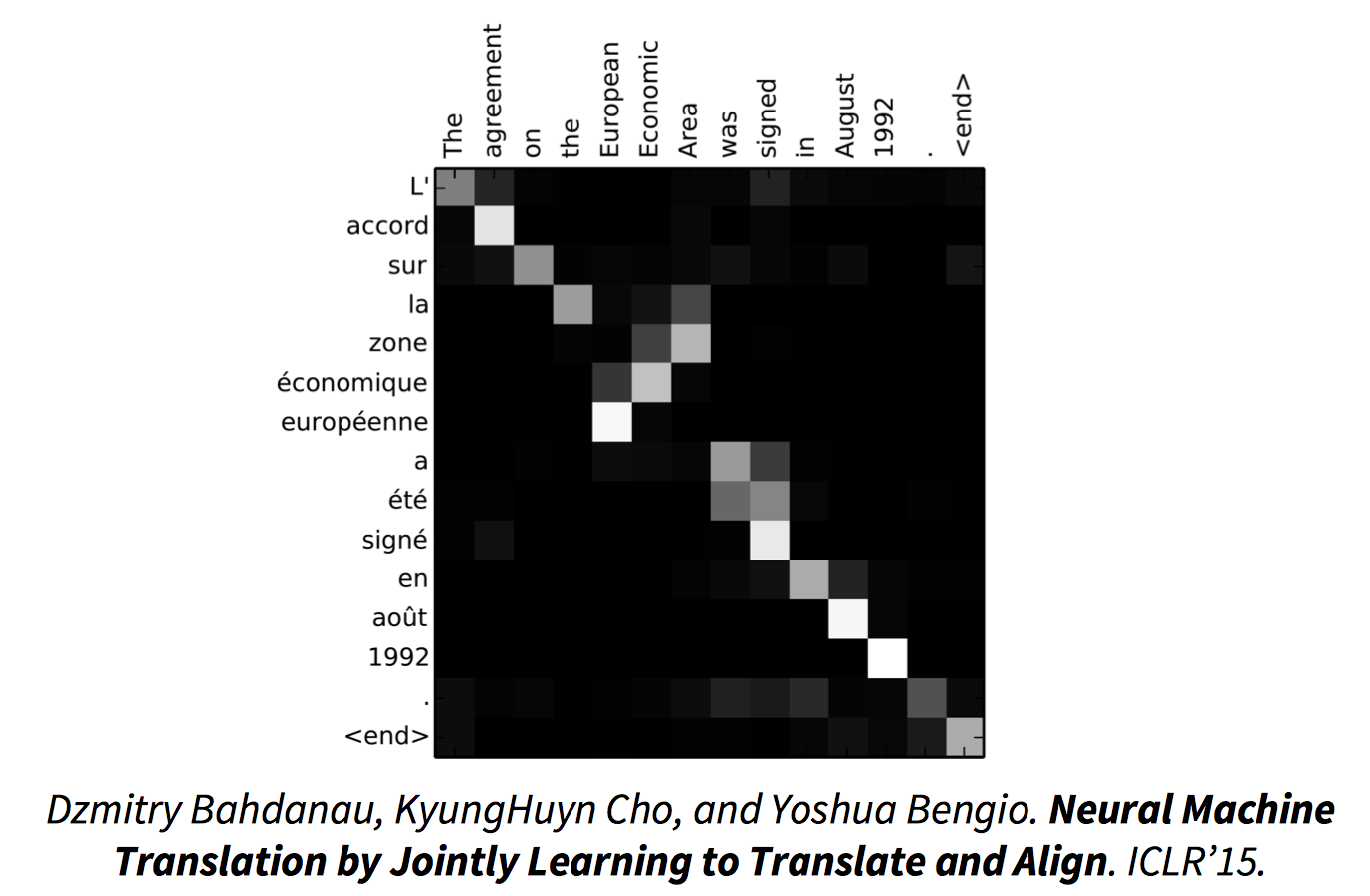
具体过程:
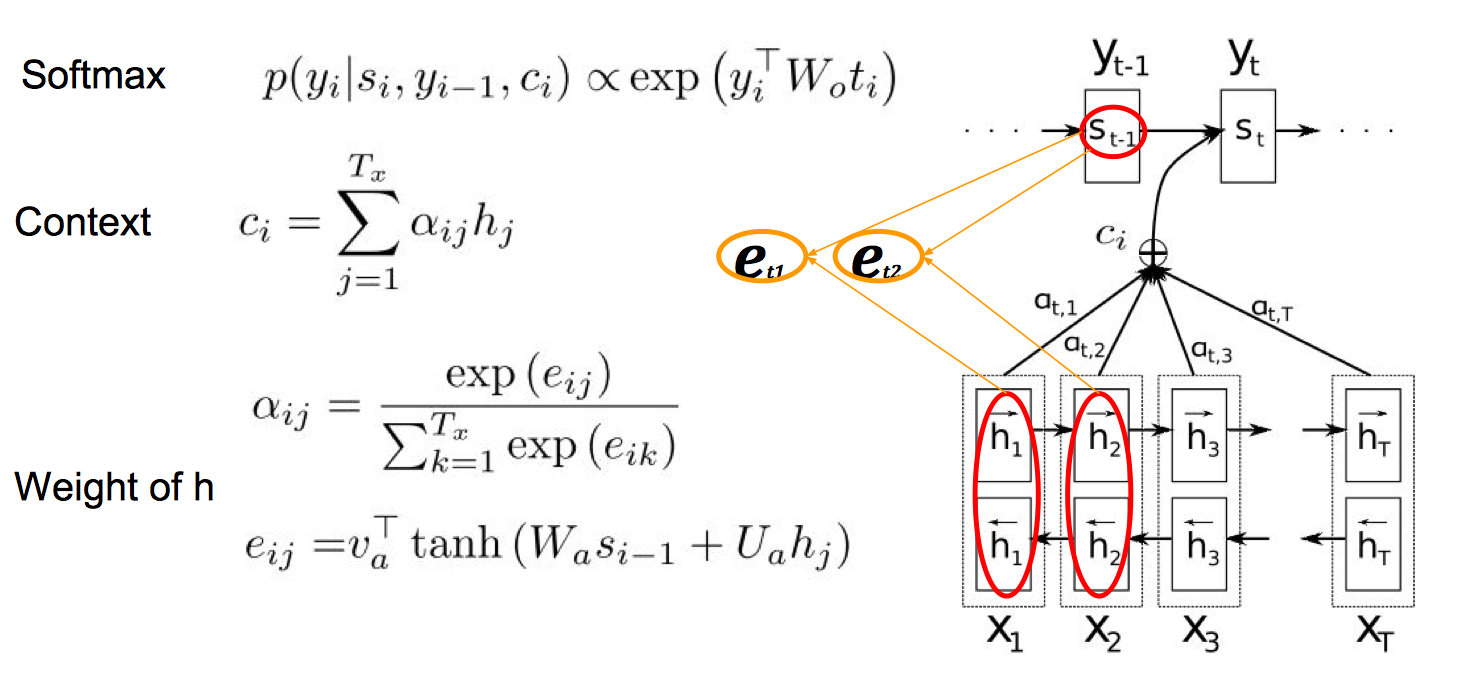
用一个感知机公式将 source 和 target 的每个词联系起来,$a(h_{i-1},\bar h_j)=v^T_atanh(W_ah_{i-1}+U_ah_j)$,然后通过 softmax 归一化得到一个概率分布,也就是 attention 矩阵,再进行加权平均得到 context vector(可以看作是 annotation 的期望值)。

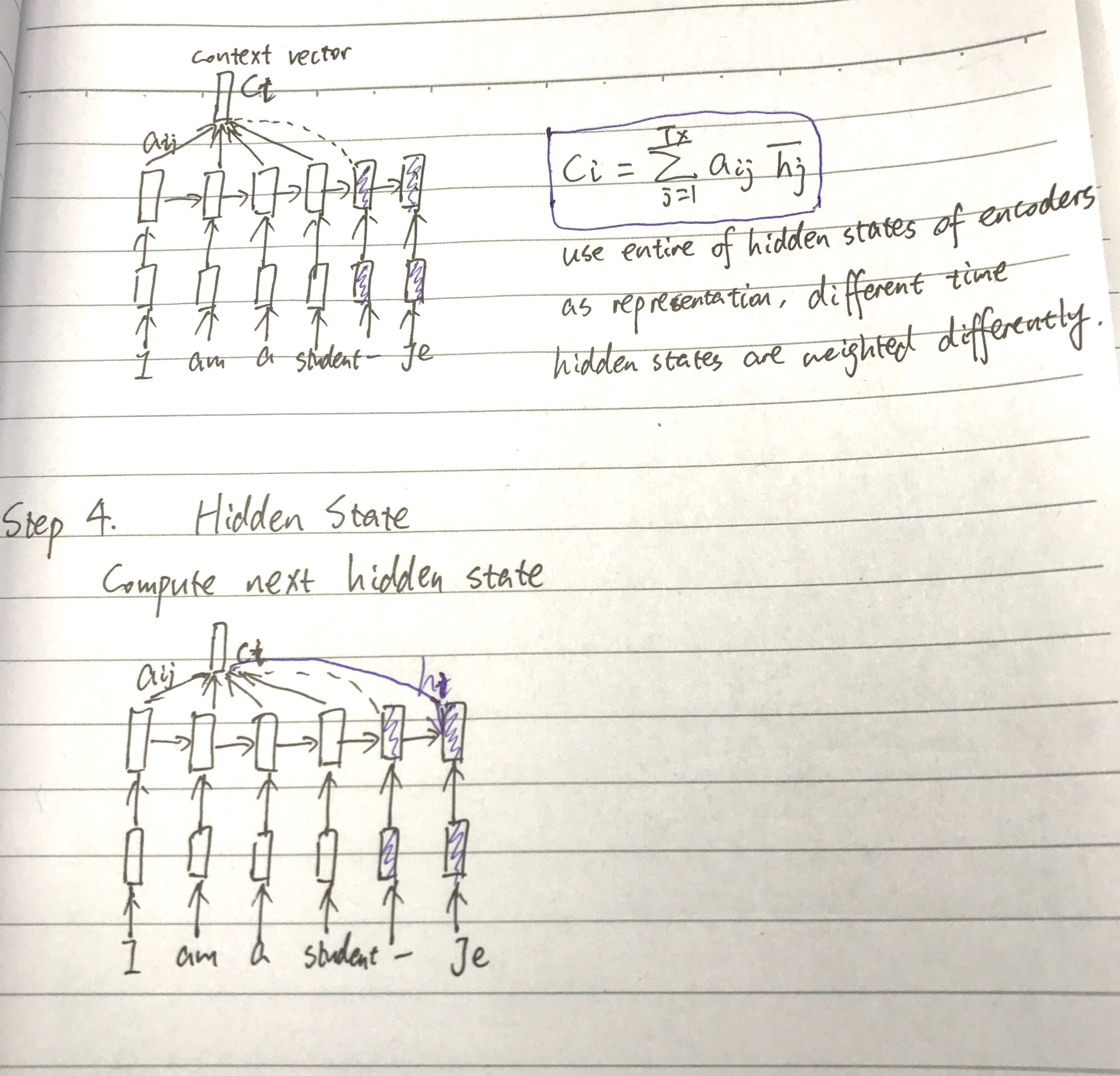
模型将 input sentence 编码成一系列 vector,然后在 decode 时自适应的选择这些 vector 的一个子集。$a_{ij}$,或者说对应的 $e_{ij}$,反映了 annotation $\bar h_j$ 关于前一个隐状态 $h_{i-1}$ 在决定下一个隐状态 $h_i$ 以及产生 $y_i$ 的重要性。直观的说,这在 decoder 里执行了 attention 机制。decoder 来决定应该对 source sentence 的哪一部分给予关注。通过这个 attention 机制,encoder 不用再将 source 的所有信息压缩到一个定长的 vector 里,信息可以在 annotation 序列中传播,然后由 decoder 来选择性的检索。
Encoder 还可以用双向 RNN 来做,这样每个单词的 annotation 不仅概括了前面单词的信息,还包括了后面单词的信息。
Attention 优化
More Score Functions
怎么算 alignment score 有下面集中不同的方式,实验表示第二种效果最好。
compute alignment weight vector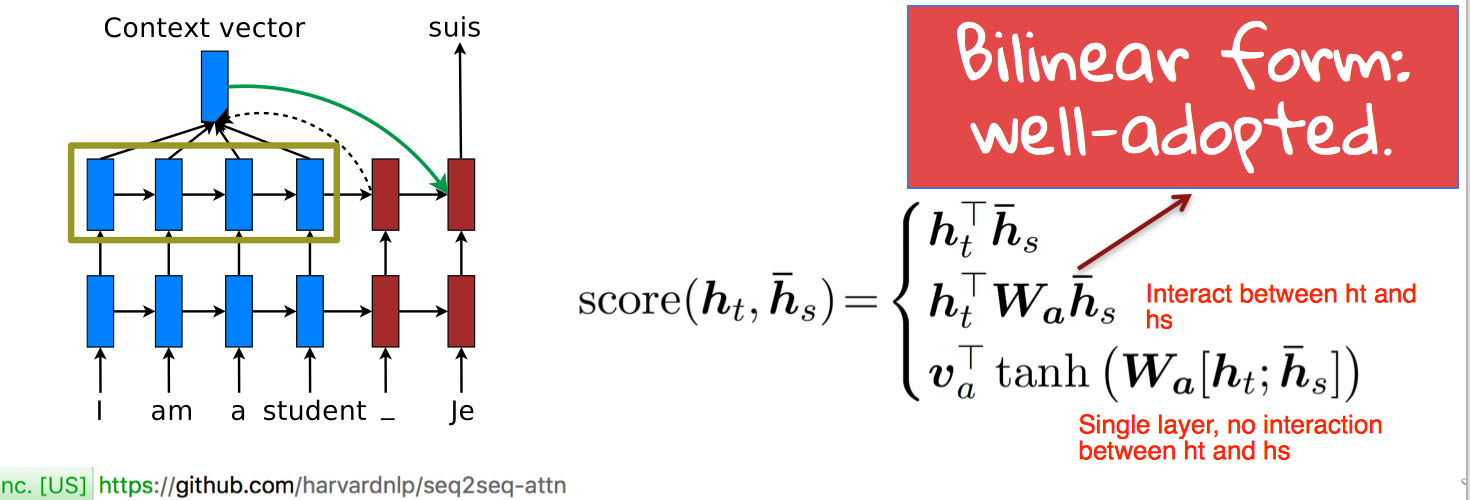
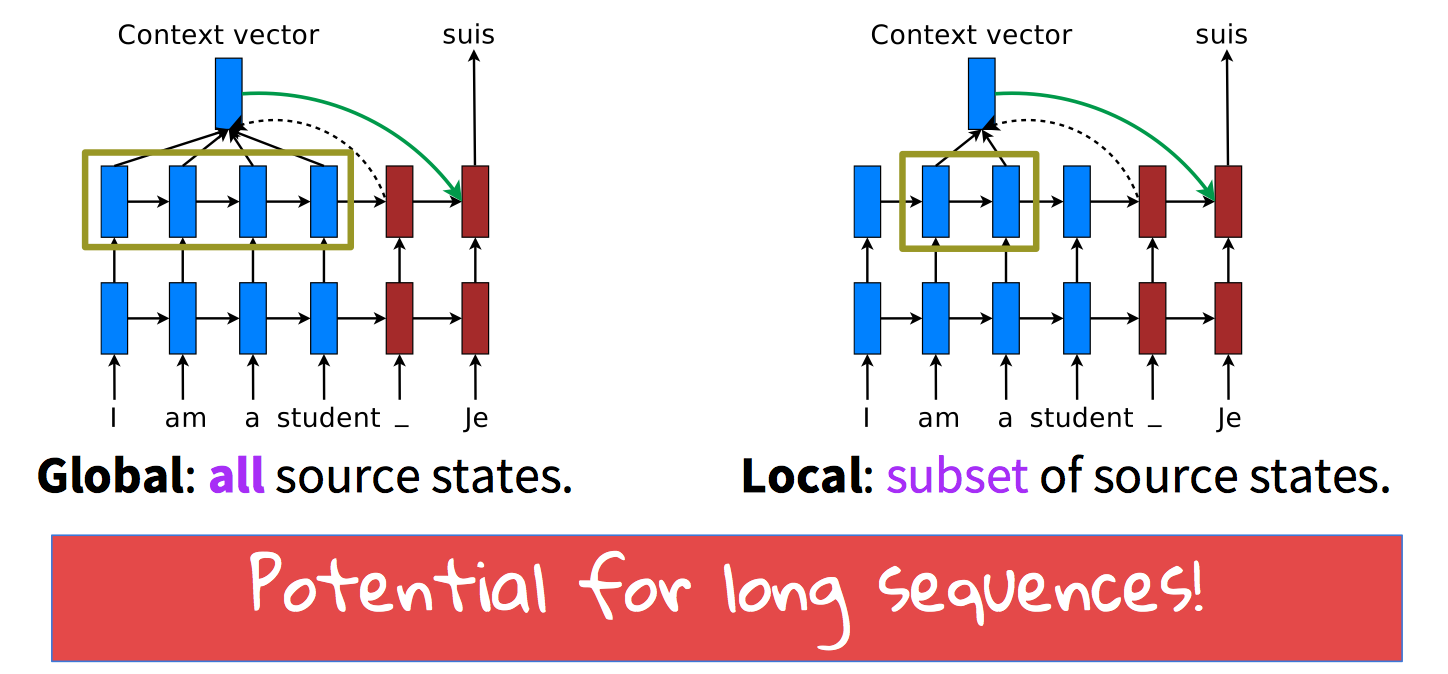
Global vs. Local
论文Xu et al.2015 Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. ICML’15 提到了 attention 可以分为 hard 和 soft 两种模型,简单理解,hard attention 就是从 source sentence 里找到一个能与产生单词 $t^{th}$ 对齐的特定单词,把 $s_{t,i}$ 设为 1,source 里的其他单词硬性认为对齐概率为 0;soft attention 就是之前 Bahdanau et al. (2014) 提到的,对 source sentence 每个单词都给出一个对齐概率,得到一个概率分布,context vector 每次是这些概率分布的一个加权和,整个模型其实是平滑的且处处可分的。
Effective approaches to attention based neural machine translation 提出了一个新的 attention 机制 local attention,在得到 context vector 时,我们不想看所有的 source hidden state,而是每次只看一个 hidden state 的子集(subset),这样的 attention 其实更集中,也会有更好的结果。
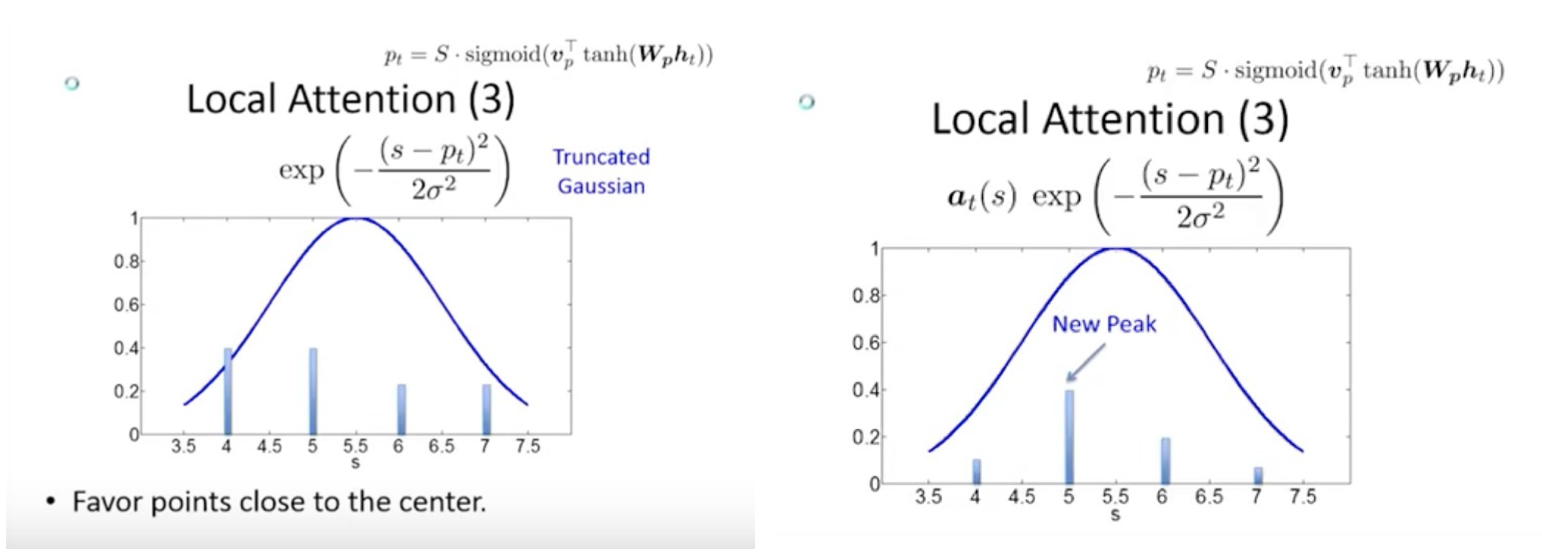
Global attention 其实就是 soft attention, local model 实际相当于 hard 和 soft attention 的一个混合或者说折中,主要是用来降低 attention 的花费,简单来说就是每次计算先用预测函数得到 source 相关信息的窗口,先预估得到一个 aligned position $p_t$,然后往左往右扩展得到一个 focused window [$p_t-D$,$p_t+D$] 取一个类似于 soft attention 的概率分布。和 global attention 不同,这里 $a_i$ 的维度是固定的。
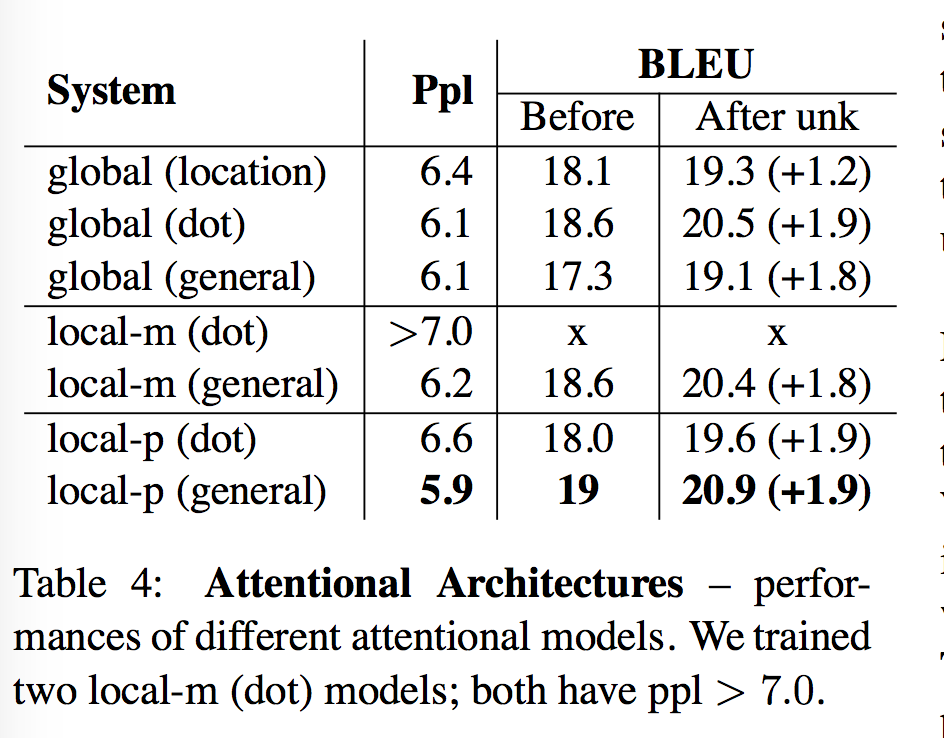
那么关于 local attention 有两个问题。第一个问题是怎么产生 aligned position,之前在 Devlin et al. (2014) 里是用规则,这里用 sigmoid function $p_t = S•sigmoid(v^T_p tanh(W_ph_t))$,其中 S 是 source sentence。第二个问题是怎么来学习这些 position parameters,像 $W_p$、$h_t$ 这些参数和网络结构中其他参数没有任何关联,怎么学习呢?方法是像 global attention 一样先计算对齐分数 $score(h_t, \bar h_s)$,然后 normalize,这里有一个 trick 是将得到的 $a_t$ 与一个 truncated Gaussian distribution 结合,也就是 $a_t(s)=align(h_t, \bar h_s)exp(-{(s-p_t)^2 \over 2 \sigma^2})$,$\sigma={D \over 2}$,这样我们会只有一个 peak,现在可以用 BP 来学习预测 position,这个模型这时候几乎是 处处可分的(differentiable almost everywhere),这种对齐称为 predictive alignment(local-p)
local attention 的训练花费更少,且几乎处处可分(differentiable)

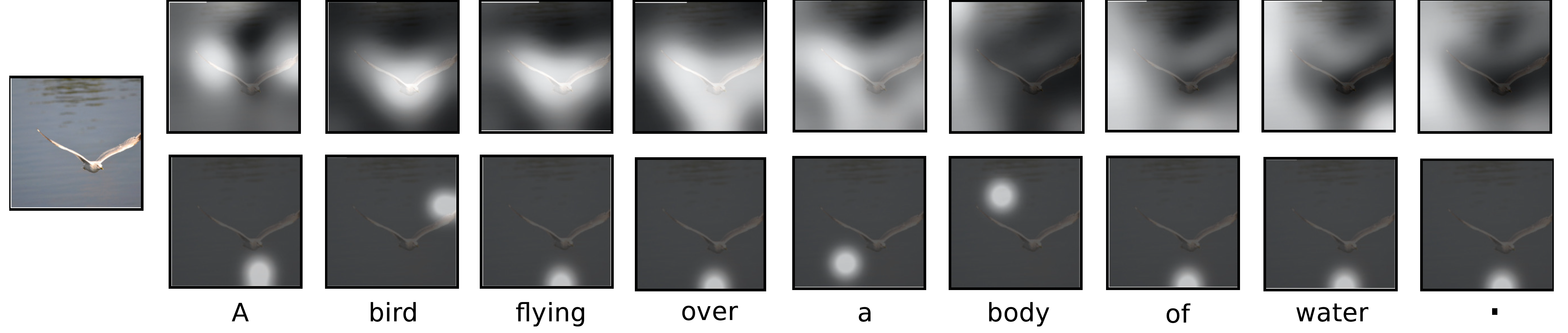
Coverage: Doubly attention
论文Xu et al.2015 Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. ICML’15提到的思路,用到机器翻译里就是同时注意原文和译文。
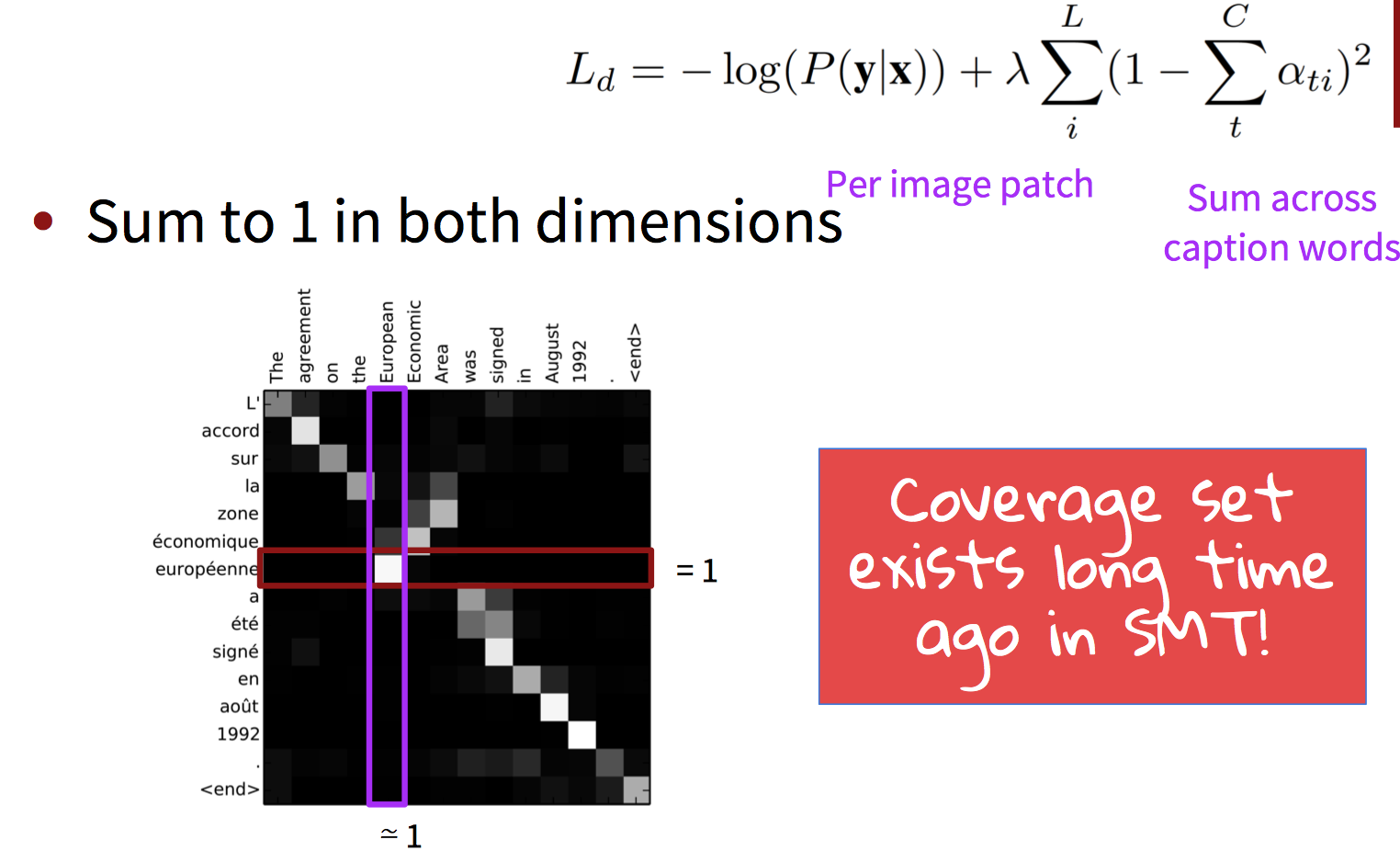
Linguistic ideas
- [Tu, Lu, Liu, Liu, Li, ACL’16]: NMT model with coverage-based attention
- [Cohn, Hoang, Vymolova, Yao, Dyer, Haffari, NAACL’16]: More substantive models of attention
using: position (IBM2) + Markov (HMM) + fertility
(IBM3-5) + alignment symmetry (BerkeleyAligner)
一般一个单词最多翻译为两三个单词,如果生成了五六个单词,那么模型可能在重复生成。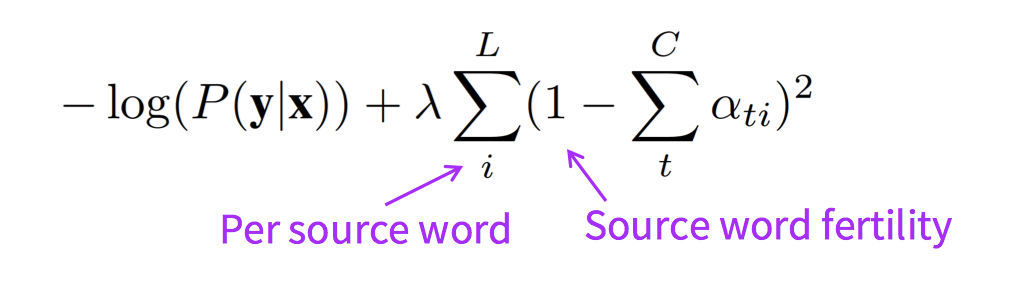
Current Research Direction on Neural MT
- Incorporation syntax into Neural MT
- Handling of morphologically rich languages
- Optimizing translation quality (instead of corpus probability)
- Multilingual models
- Document-level translation
到目前为止,我们都是假设在两种语言 F 和 E 之间训练一个模型。但是,世界上有许多种语言,一些研究已经证明能够利用所有语言的数据去训练一个模型。也可以跨语言执行迁移,先在一个语言对上训练模型,然后将其微调用于其他语言对。

