目标分类的基本框架 + 迁移学习 + 如何设计神经网络 + 实例:基于 VGG 进行人脸表情识别。深度学习的学习笔记。
目标分类基本框架
目标分类的应用场景有人脸识别、物体识别、场景识别、文字识别等,先看一下目标分类的基本框架。
- 数据准备
数据足够?不够怎么增加数据量 - 模型设计
用现有模型?直接用复杂模型?
数据少的时候,设计简单网络进行简单学习,还是大网络进行特殊任务学习 - 训练细节
神经网络配件,参数等
数据准备
数据来源: 现有数据集的子集; 网络采集; 现有数据人工标注
现有数据: http://deeplearning.net/datasets/ ,包含各种数据集如自然图片/人工合成图片/人脸/文本/对话…
数据扩充: 原始数据切割; 噪声颜色等像素变化; 旋转平移等姿态变化
如下图,一张图片经过了 5x 的像素级变化,包括平均/锐化(unsharp)/动作模糊(motion)等,每种又经过了 6x 的旋转平移,也就是说,原始数据扩充了 30x
旋转平移 R, T 的矩阵变换
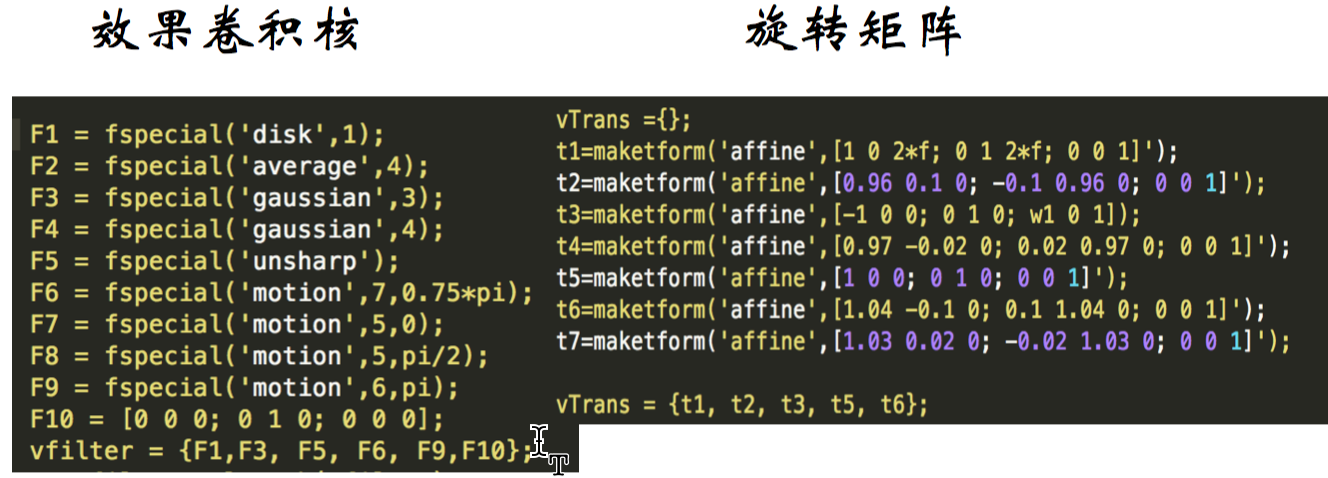
数据规范: 均值处理;归一化;大小调整
模型设计
任务类型
分类:表情分类,属于什么种类,人群分类
分类+回归:表情+程度,种类+信心,什么人+人数
多目标分类:面部行为,群体行为,车流预测
模型选取
看现有模型(the-state-of-the-art)能否借鉴
- 偏图像处理,CV:ICCV, ECCV, CVPR
- 偏理论,机器学习相关:ICML NIPS
- 偏语言处理,信息挖掘:ACL, KDD
如果能借鉴,是否要做局部更改,从哪里改变;
如果不能借鉴,就需要从头设计,那么新结构特点是什么,为什么可行
训练细节
要考虑的问题有
- GPU-Batch size,是否并行
注意 GPU内存-Batch Size 的关系,batch size 设置太小,速度慢,batch 更新效果没那么好,如果设置过大,程序会崩掉 - 数据循环方式/平衡性考虑
- 数量较少的类别,数据是否需要补偿
- 从头到尾多次循环(不利于类别不平衡的情况)
- 每次随机选取部分数据(更容易处理平衡性)
- 网络深度宽度确定
直接答案当然是深度优先,主要原因是层数变多,能用更少的参数更有效的学习特征
如 5x5 一层卷积核相当于两层 3x3 卷积核,然而两层 3x3 只要 18 个参数,而一层 5x5 要 25 个参数 - 损失函数设计
比如分类用 SOFTMAX,还是直接拟合 - 学习率变化方式
模型各层学习率是否一致 - 评价方式
准确率,F1 score
比如在 0/1 分类中,评价方式的设计可能会偏向正例,因为很多情况下 0 会 overweight 1,假设分类结果全是 0,precision=90%,看起来很高,然而什么都没学到,所以要用 F1 score。123F1 score: 2*(Recall*Precision)/(Recall+Precison)Recall: 正确的1识别/真值所有1个数Precision:正确的1的识别/所有认为是1的个数
更多见 卷积神经网络 CNN 笔记 功能层部分。
迁移学习
问题:ImageNet 上亿参数,数据量百万,是不是参数多的模型都需要大量数据?
当然不是啦,我们可以用别人训练好的模型(基础模型),在训练好的部分参数基础上进行训练。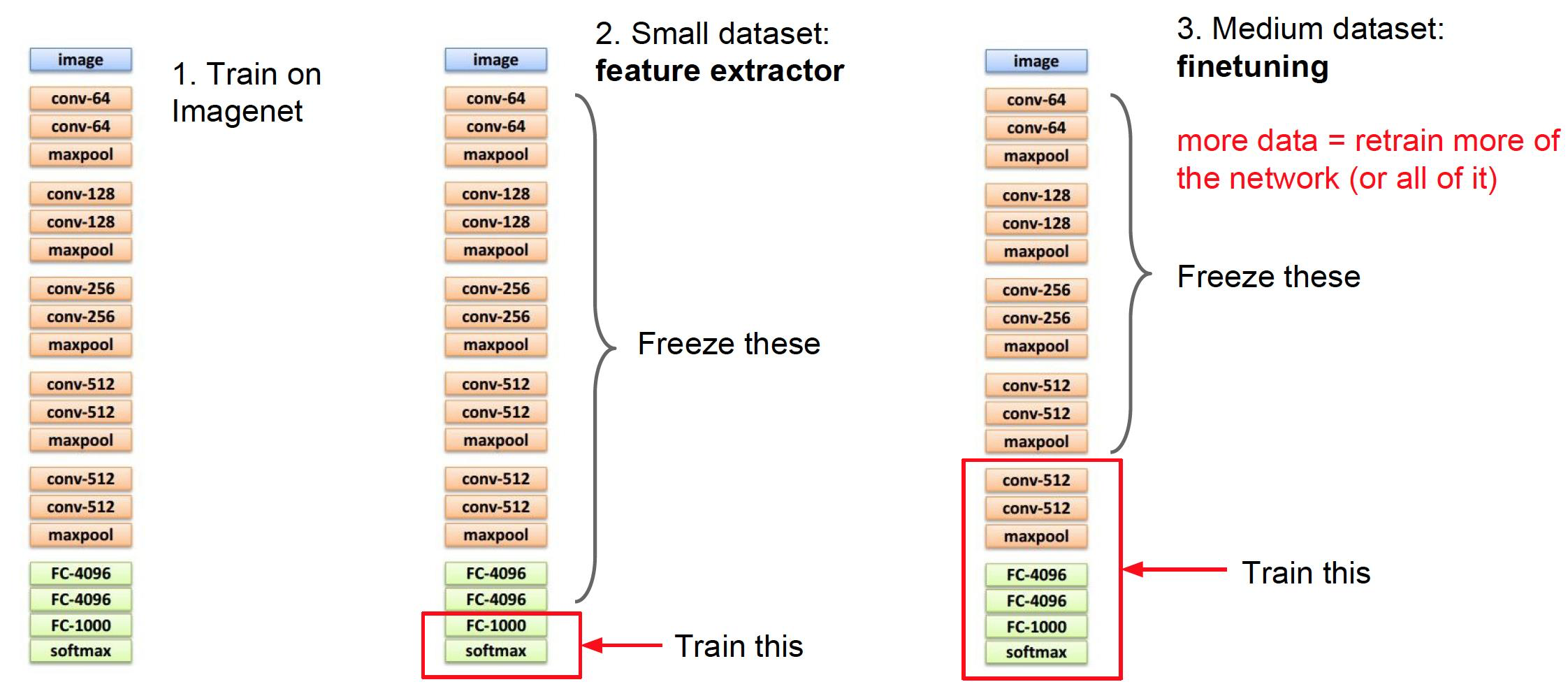

基础模型的选择往往看是否已有特定任务的模型,另外关于 学习率(learning rate) 的处理,最低卷积层的学习率基本不变,中间卷积层看情况(数据是否类似等),最后全连接,结构和参数都需要变化。
如何设计神经网络
研究问题:如何进行面部行为识别(AU detection)
面部行为识别有很多的应用,比如测试疲劳驾驶等,一个很有意思的应用场景是推荐系统,想象看电视的时候有一个前置摄像头观察观众的反应,通过表情识别可以知道观众喜欢哪个节目,然后可以针对性的给更多高质量的推送,再比如应用到教育上面,如果能自动通过疑惑的表情判别出哪一部分学生不理解,可以针对性的给学生多解释几遍做巩固加强,当然这些都涉及到隐私问题,在这里不讨论。
现有模型
看一下已有方法/模型。
Deepface,卷积神经网络 CNN 笔记(高级篇)
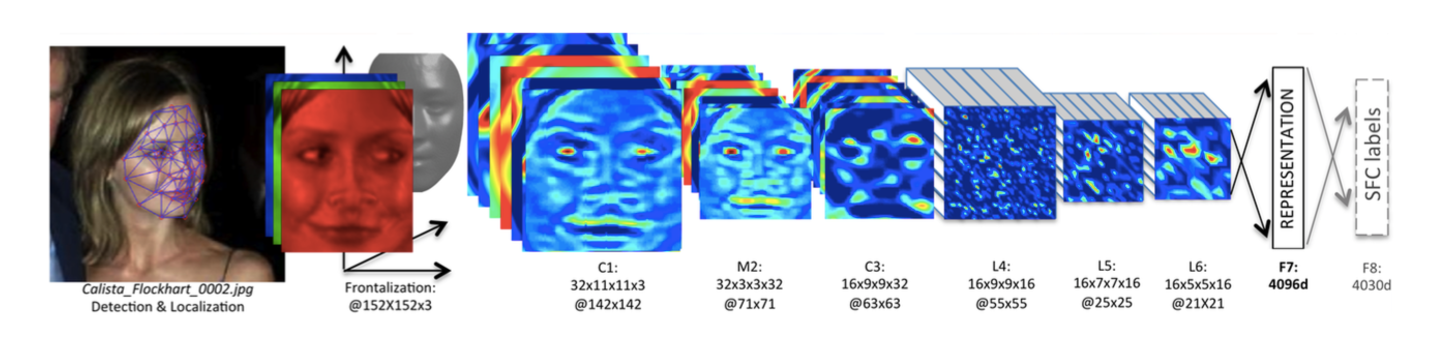
传统 CNN 用同一个卷积核对整张图片进行卷积运算,卷积核参数共享,不同局部特性对参数影响相互削弱,达不到最优的效果,对应的解决方法是局部卷积,不同的区域用不同参数。Deepface 对每个 pixel 都用单独一个卷积核来学习,这种全局部卷积连接有主要有下面几个缺陷
- 预处理:大量对准,对对准要求高,原始信息可能丢失
- 卷积参数数量很大,模型收敛难度大,需要大量数据
- 模型可扩展性差,基本限于人脸计算
也有人把特征图分成 8x8=64 小份,一小份一个卷积核,但是这并不能彻底解决上面的问题,我们的改进目标是:
- 不需要预处理,自动进行局部探测
- 不要所有区域都处理,更多关注在有意义的区域
比如额头的信息就比较少,眼睛眉毛嘴巴的信息相对重要的多 - 重要区域之间不会影响削弱学习效果
注意力网络-attention layer
一个想法是注意力网络-attention layer,通过权重来聚焦,如下图,我们的目标是看篮子里有什么,所以篮子给大的权重,其他地方不重要,就给小的权重,极端情况就是篮子给 1,其他部分给 0。
再来看一下注意力网络在面部行为识别上的应用
左图是人脸的肌肉分布,中间的图绿色的点是特征点分布,蓝点是行为单元中心(action unit),蓝点通过平移变换找到绿点,生成右图的 attention layer。步骤如下:
- Dlib(或原始数据集)找到人脸关键点
- 人脸关键点 -> 行为单元中心
- 由中心生成注意力图
中心为 1,往外扩散
这样在 CNN 结构下的注意力网络对误差的容忍度其实是很高的,原来 10 个 pixel 的误差经过几层 pooling 可能就到了 1 个甚至零点几个 pixel。
得到注意力网络后,我们需要对原始模型进行修改,一个问题是添加在哪里?什么方式添加?一个初始想法自然是放到中间做一个大的滤波,但是这样会完全丢掉不重要的区域,而我们希望保留原始结果,只是多加强下注意力,一个想法是采用 Residual net 的思想,将注意力层和之前的特征图层进行融合。
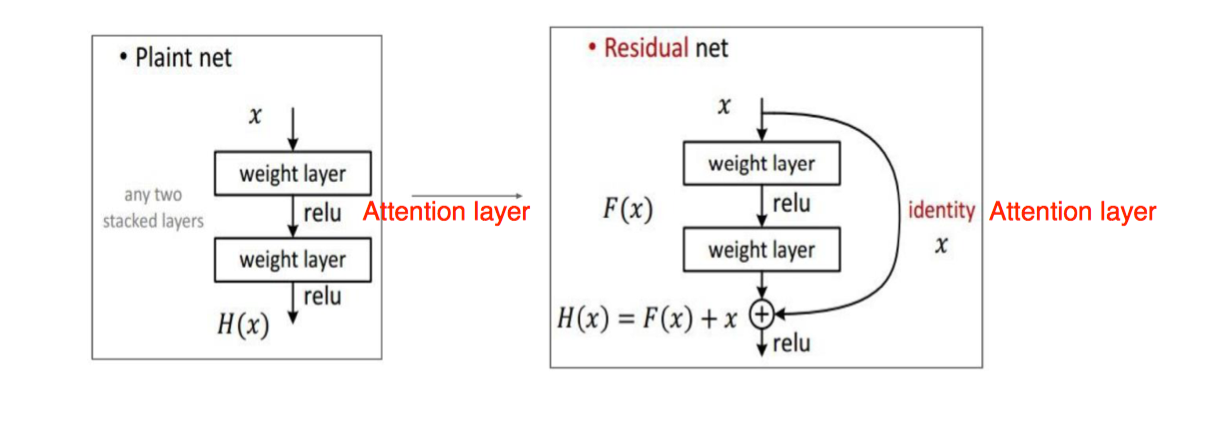
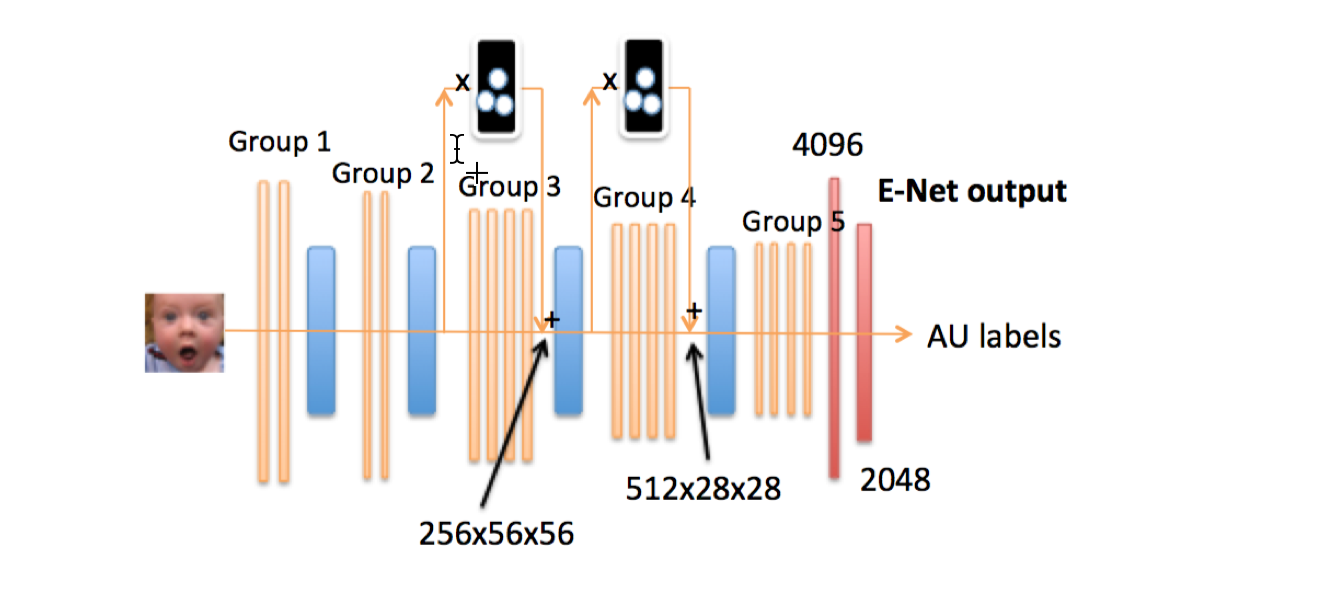
为什么添加在 3,4 层而不是 1,2 层呢?因为在 3,4 层表达会更强一些,1,2 层相对太底层。
注意力网络的效果图: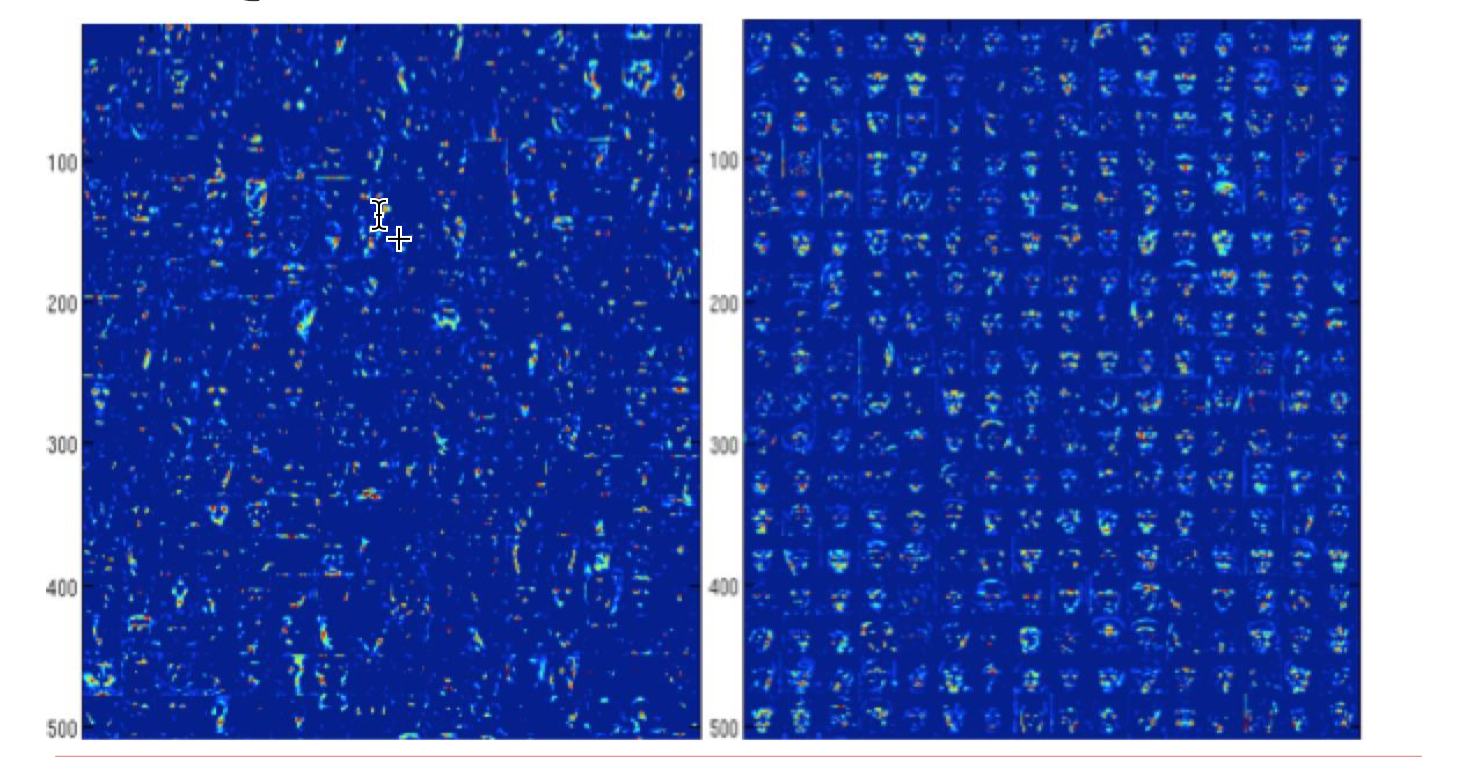
局部学习网络
另一个想法是局部学习网络:针对不同的区域进行针对性学习,不同的区域的学习不会相互干扰,对区域的分布能够自动适应。方法也就是切割局部,形成局部神经网络,中间层可以做 upscaling,也就是反向 pooling,之后也可以做下 deconvolution,如下图:
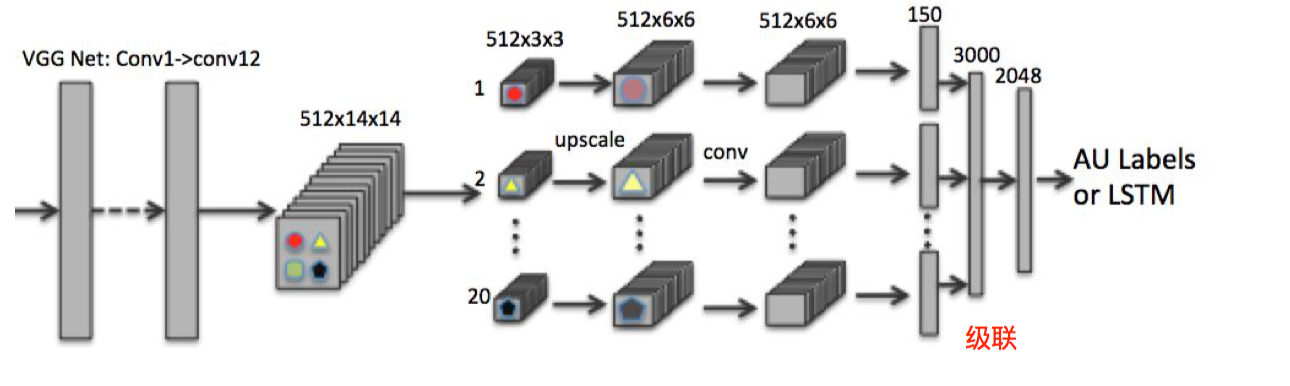
网络合并
网络合并: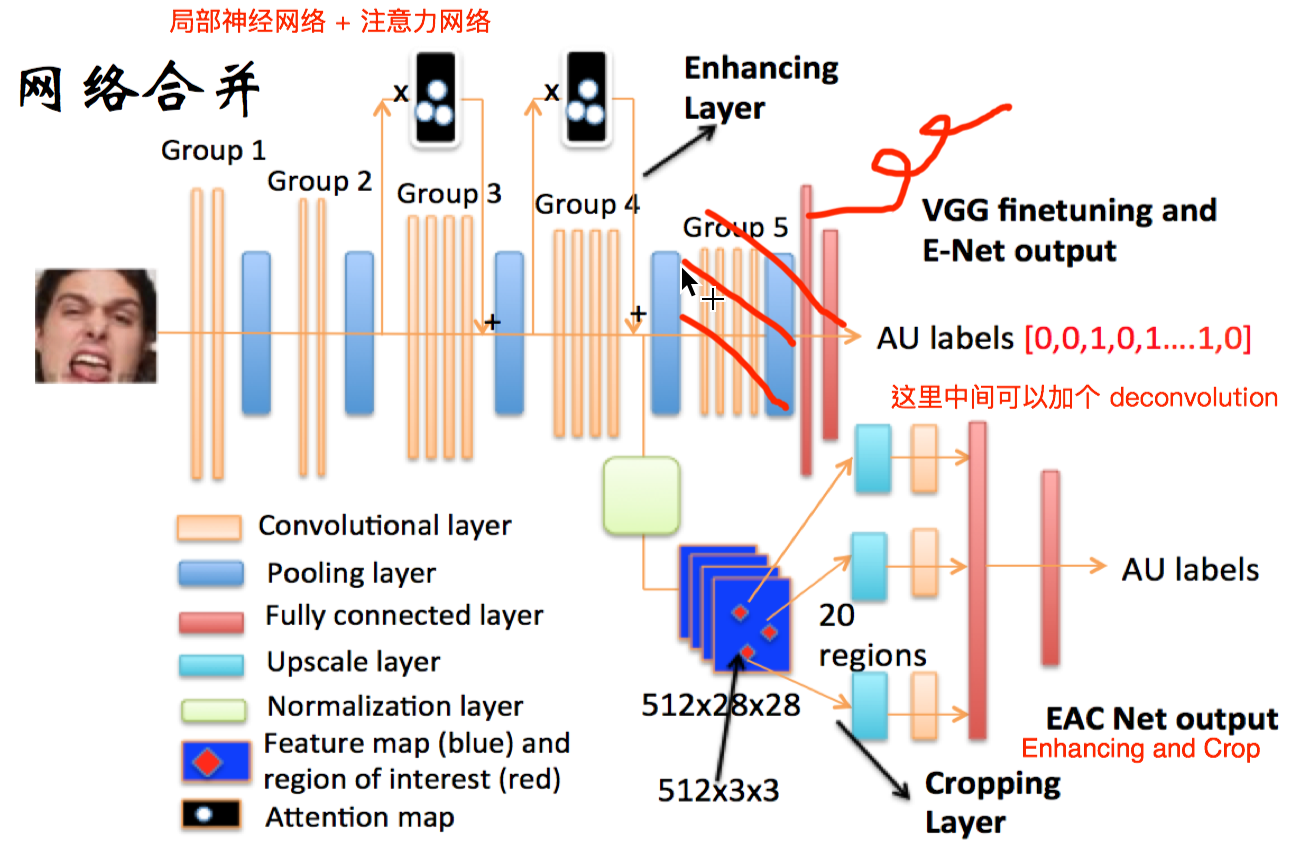
这种结构的效果还是非常不错的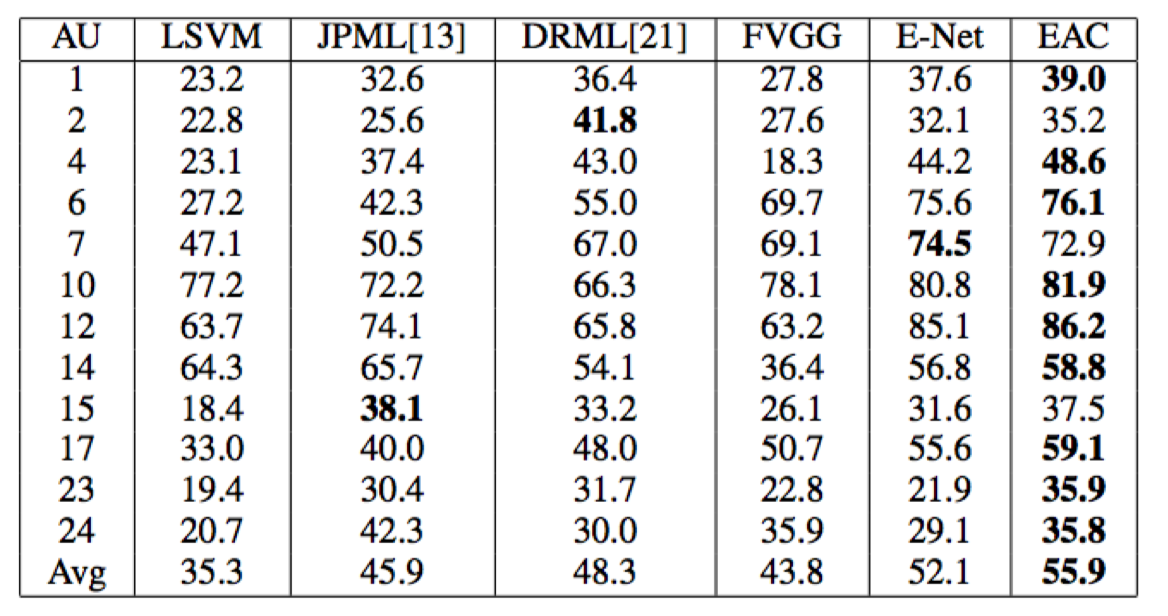
再总结下上面这种网络结构的作用:
- 无需提前进行面部对准就可以对面部行为识别
- 脸部各个行为单元局部针对学习,局部信息 可以单独用于某个行为单元识别
- 根据控制肌肉的分布以及人脸特征点检测结 果确定区域,更具有合理性以及可操作性
具体可以看论文EAC-Net: A Region-based Deep Enhancing and Cropping Approach for Facial Action Unit Detection
实例:基于 VGG 进行人脸表情识别
数据集:CIFE:Candid image for facial expression
在 vgg16 基础上调整模型。
vgg16: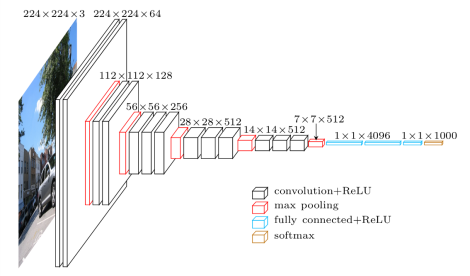

这里选择在中高层更新参数(最后一个卷积群+全连接层),模型代码如下
环境配置,docker 获取镜像 shuang0420/tensorflow-tflearn-python3-jupyter
运行
/$(pwd): 和 /$(pwd)/tensorflow/logs 是本机目录,它把 container 中的 Jupyter notebooks 以及 logs 匹配到了本机目录,使得 container 和本机可以共享资源。当然首先要保证你的 docker 和 local host 有共享这些目录的权限,在 Docker Preferences 里可以设置。

