Stanford Dan Jurafsky & Chris Manning: Natural Language Processing 课程笔记。文档/会议/邮件摘要,QA 系统回答 what/how 等复杂问题,都需要自动摘要技术。本篇主要讲基于查询的摘要。
Types of Summarization Task
单文档 vs 多文档
- Single-‐document summarization
给定一个文档,产生 abstract/outline/headline - Multiple-‐document summarization
给定主题相关的一组文档,通过摘要来概况同一事件/主题的信息
与单文档相比,多文档任务面临的减小句子冗余度/确定句子顺序/确定压缩比率(从每个文档中抽取句子的比例)/指代消解问题都更加的突出
查询无关 vs 查询相关
- Generic summarization
对一个文档的内容做整体性的摘要 - Query-‐focused summarization
根据用户查询语句表达的信息需求(information need)来对一篇文档做出摘要总结,如 Google snippets
用于 QA 系统,根据提问产生文档摘要来回答一个复杂的问题
查询相关的文本摘要对句子重要性的衡量需要同时考虑主题性以及查询相关性
抽取式 vs 合成式
- Extractive summarization
摘要句子完全从源文档中抽取形成 - Abstractive summarization: our own words
从源文档中抽取句子并进行改写形成摘要
目前来看,大多数的系统是抽取式,合成式的技术还不够成熟。
本章主要讨论 Extractive summarization
Baseline Model
好的作者常常会在标题和第一句话就表达主题,因此最简单的 baseline 就是抽取文档中的首句作为摘要。
Generating snippets: query-focused summaries
看一下 Google snippets
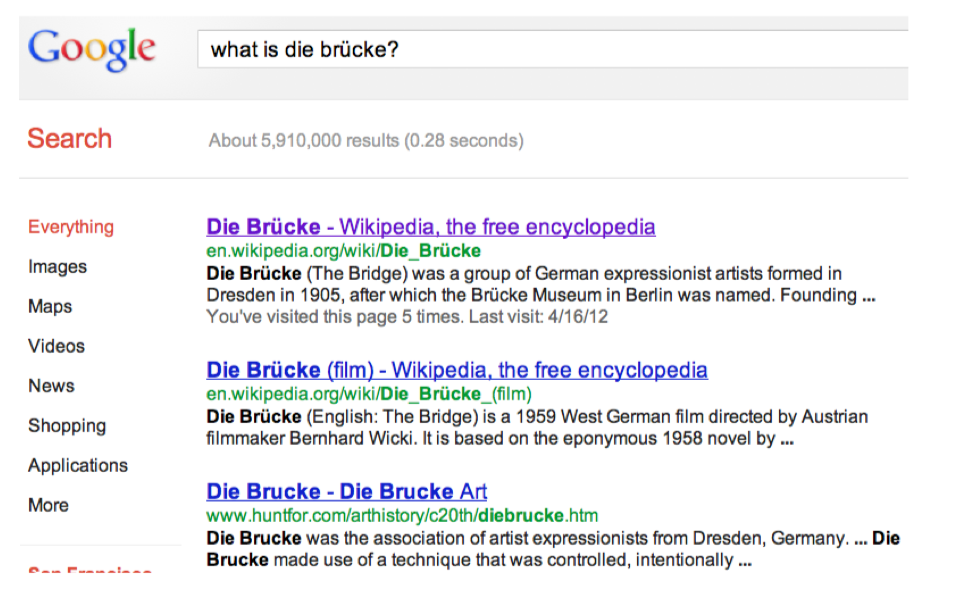
- Single-‐document summarization
- Query-‐focused summarization
- Extractive summarization
Main Stages
产生 snippets 的主要步骤(Stages):
- content selection
选择需要抽取的句子(segment/moving window) - information ordering
对抽取的句子进行排序 - sentence realization
形成摘要

Base Summarization Algorithm
对一个 base summarization algorithm 而言,其实只需要做第一步 conent selection,之后的 information ordering 即保留句子在源文档的位置,sentence realization 即保留原句。
Unsupervised content selection
我们需要选择的是salient or informative的句子,一般来说,salient words 有两种选择方法
- tf-idf
也就是找在该文档中经常出现,并且在其他文章中很少出现的单词 - topic signature
通过计算 log-likelihood ratio(LLR) 并设置 threhold 来过滤并选择重要的单词
$weight(w_i)=1 \ if -2log \lambda(w_i)>10 \ else \ 0$
这里主要介绍下Topic signature-based content selection with queries
Step1: choose words
salient words 有下面两个来源:
- 计算每个单词的 log-likelihood ratio(LLR) ,根据 threshold 进行选择
- 选择所有出现在 query 里的单词
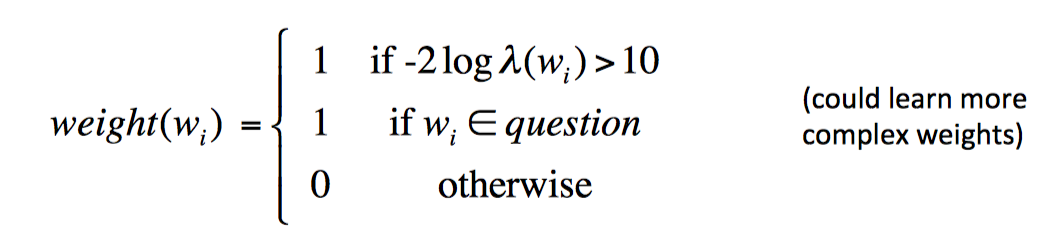
Step2: weigh a sentence(or window)
在上一步计算的单词分数基础上,计算每个句子/短语窗口的分数
$$weight(s)={1 \over |S|} \sum_{w \in S} weight(w)$$
选择 top k 个句子。
Supervised content selection
其实是一个二分类问题,对文档中的每一个句子,用分类器进行二值分类,1 代表这个句子可以作为摘要输出句子,0 代表不能。
监督学习方法难点是获得训练集,很有可能摘要句子并不是文档中的完整句子,所以需要事先把文档句子和摘要句子对齐,才能得到分类标签。然后对文档句子抽取特征将句子映射为特征向量,再训练分类器,可以用的算法如 Naive Bayes/Decision Tree/HMM/CRF/LR/SVM/SVM-HMM等

Summary
上面提到的只是最基础的方法,对非监督方法而言,还有下面的方法
- 线性组合方法:利用手工构建的评分函数,采取若干重要特征并手工设定特征权重,以此来对句子重要性进行得分计算。
- 词汇链方法:通过文章中相邻句子的语义相似性来判断文章主题,引入Wordnet等语言资源中的同义词和近义词信息,分析文章中相邻句子的语义相似性。寻找若干最长的词汇链来确定文章包含主题,并依此来构建文摘句子集合;[6,7]
- 图模型方法:将文章中每个句子作为图中的节点,利用句子之间内容相似性构建图中节点之间的边。构建好文章图后,利用PageRank或者HITS算法来迭代计算图中节点的权值,按照权值大小作为句子重要性的评分依据来对文摘句子进行抽取。[3,4]
- 子主题分析方法:通过聚类或者语义块分析等手段,发现文章包含的子主题,并从不同的子主题中抽取句子来构造摘要句子集合。LSA,PLSA等方法属于这一类[8,10,12]。
一些研究工作 Document Summarization using Conditional Random Fields 和 Enhancing Diversity, Coverage and Balance for Summarization through Structure Learning对主流的一些自动文摘方法做了对比,对于非监督方法来说,基于 HITS 的图模型方法明显优于其他方法,对于监督方法来说,SVM-HMM 和 CRF 方法效果最好,其中 SVM-HMM 方法在一般测试集合上稍微优于CRF,在难度高的测试集合上效果明显好于CRF方法。这两个方法优于HITS图模型方法,不过优势并非特别明显;从测试结果来看,方法效果排序如下 SVM-HMM>CRF>HITS>HMM>SVM>LR>NB>LSA
|
|
这部分的总结来自文本摘要技术调研
[1] .Jie Tang, Limin Yao, and Dewei Chen . Multi-topic based Query-oriented Summarization.
W.-T.Yih, J. Goodman, L. Vanderwende, and H. Suzuki. Multi-document summarization by maximizing informative content-words.In Proceedingsof IJCAI’07, 2007.
[2] Dou Shen1,Jian-Tao Sun.etc DocumentSummarization using Conditional Random Fields. InProceedingsof IJCAI’07, 2007.
[3] GunesErkan. Dragomir R. Radev. LexRank: Graph-based LexicalCentrality as Salience in Text Summarization. Journal of ArtificialIntelligence Research 22 (2004) 457-479
[4] Rada Mihalcea. Language Independent Extractive Summarization.
[5] Liangda Li, Ke Zhou†,Gui-Rong Xue etc Enhancing Diversity, Coverage and Balance for Summarization through Structure Learning. WWW 2009.
[6] Gregory Silber and Kathleen F. McCoy Efficient Text Summarization Using Lexical Chains.
[7] Barzilay,Regina and Michael Elhadad. Using Lexical Chainsfor Text Summarization. in Proceedings of the IntelligentScalable Text Summarization Workshop(ISTS’97), 1997.
[8] Shanmugasundaram Hariharan Extraction Based Multi Document Summarization using Single Document Summary Cluster Int. J.Advance. Soft Comput. Appl., Vol. 2, No. 1, March 2010
[9] ShanmugasundaramHariharan, “Merging Multi-Document Text Summaries-A Case Study”, Journal of Scienceand Technology, Vol.5, No.4,pp.63-74, December 2009.
[10] JinZhang etc AdaSum: An Adaptive Model for Summarization. CIKM 2008.
[11] Varadarajan and Hristidis. A System forQuery-Specific Document Summarization CIKM2006.
[12] LeonhardHennig Topic-based Multi-Document Summarization with Probabilistic Latent Semantic Analysis
Complex Questions: Summarizing Multiple Documents
自动摘要还可以用于回答复杂的问句(如 how/what),有两大类方法,自底向上的 snippet 方法,以及自上而下的信息抽取方法。
Bottom-up snippet method:
- 找到相关文档集合
- 从文档集合中抽取 informative sentences
- 对句子进行排序并形成回答
Top-down information extraction method:
- 根据不同的问题类型建立特定的信息抽取框架
- 抽取信息
- 形成回答
属于研究热点,有很大提升空间。
Bottom-up snippet method
处理框架:
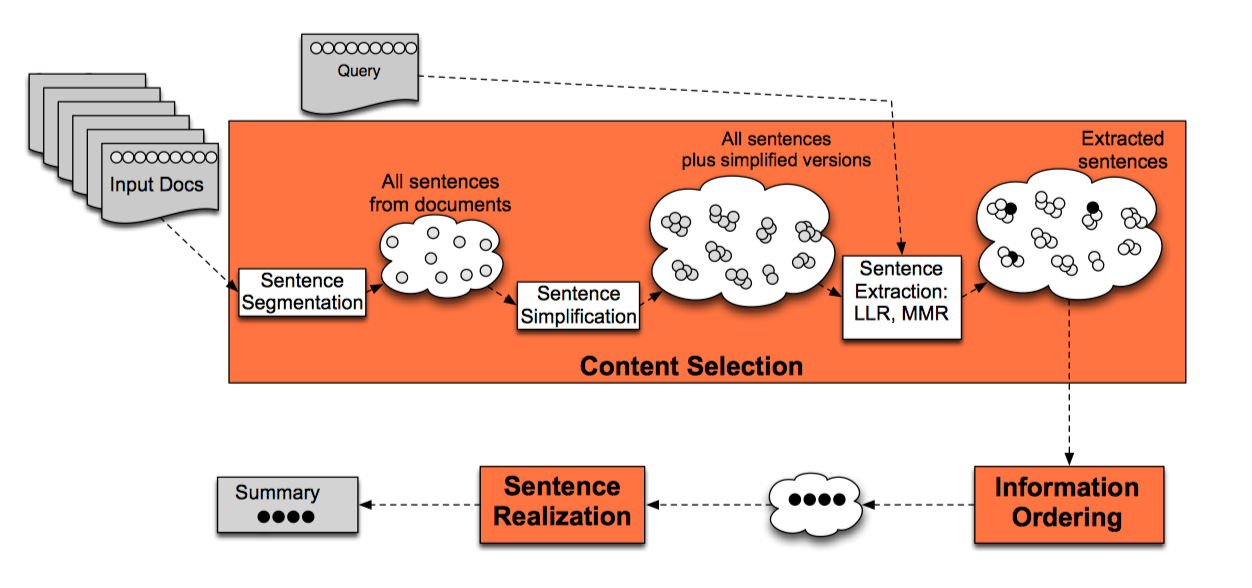
Sentence Simplification
首先简化句子,可以删除 同位语/定语从句/没有命名实体的介词短语/句子开头的状语 等

Sentence Extraction
Maximal Marginal Relevance(MMR)
MMR 是一种从多个文档中进行选择的递归(iterative)方法,递归的从文档中选取最合适的句子插入到 summary/answer 中,两个指标是相关性(relevant),以及 新颖度(novel)。这在Search Engines笔记 - Diversity也提到过。
- Relevant
与 query 最相关的句子,high cosine similarity to the query - Novel
减少 summary/answer 的冗余程度,low cosine similariy to the summary
$\hat S_{MMR}=max s \in D \lambda sim(s,Q) - (1-\lambda)max s \in S sim(s,S)$ - 不断添加句子到 summary 中,直到 summary length 到达预期要求
LLR + MMR: choosing informative yet non-redundant sentences
1. 根据 LLR 对每个句子进行打分
2. 选择 top k 个句子作为候选的摘要句
3. 迭代的从候选集里选取高分并且还不在当前摘要里的句子,添加进摘要
Information Ordering
- 时间顺序(Chronological ordering)
根据时间对句子进行排序,主要用于新闻类的摘要(Barzilay, Elhadad, and McKeown 2002) - 一致性(Coherence)
根据 cosine similarity 对句子排序,使得摘要中相邻的句子更相似,或者相邻句子讨论同一个实体(Barzilay and Lapata 2007) - 专题排序(Topical ordering)
从源文档中学习主题排序
Information Extraction Method
用信息抽取(IE)的方法来回答,比如说一个人物传记类的问题答案通常包含人物的 生卒年月,国籍,教育程度,名望/荣誉等,一个定义类问题(definition)通常包括 属(genus)或者上位词(hypernym),如 The Hajj is a type of ritual,一个关于用药的医学类问题通常包括 问题(medical condition)、治疗(intervention, the drug or procedure)和结果(outcome)

上图是课程提到的 IE 方法框架,暂时不是很理解 predicate identification 这一步,感觉 Multidocument Summarization via Information Extraction这篇文档的框架更加 straight-forward 一些。

Evaluating summaries: ROUGE
ROUGE 是内部评价指标,以 BLEU 为基础,虽然比不上人工评价,但是用起来很方便
给定一个文档 D,以及一个自动生成的文本摘要 X:
- 由 N 个人产生 D 的 reference summaries
- 运行系统,产生自动文本摘要 X
- 计算 reference summaries 中的 bigram 在 X 里出现的比例
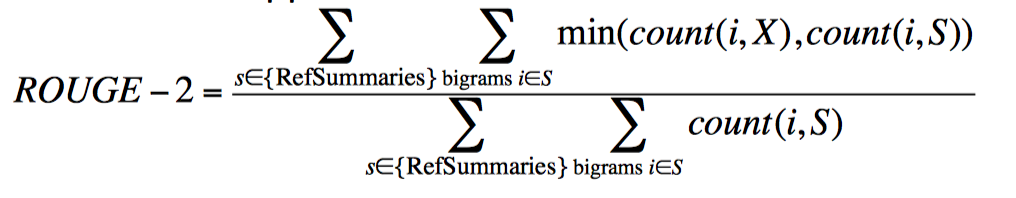
举个例子,问句是 “What is water spinach?”,Human 1, Human 2, Human 3 是人工产生的 reference summaries,System answer 是自动摘要,计算如下


