CMU 11611 的 guest lecture 笔记。重点讲机器翻译传统 Noise Channel 模型以及目前流行的几个神经网络模型。
一张图看机器翻译历史。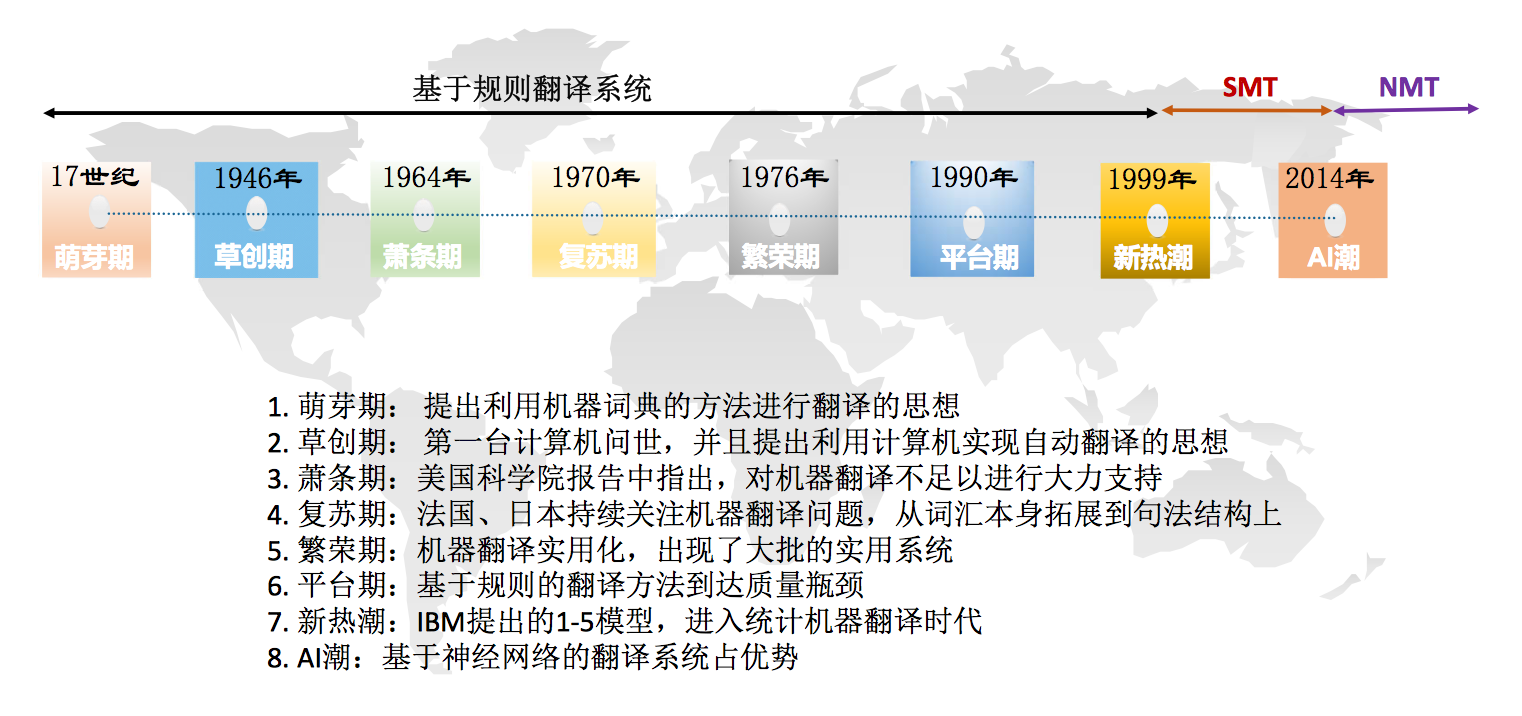
Noise Channel
我们想要一个 p(e|f) 的模型,f 代表源语言(confusing foreign sentence),e 代表目标语言(possible English translation),noise channel 前面讲过了,如下图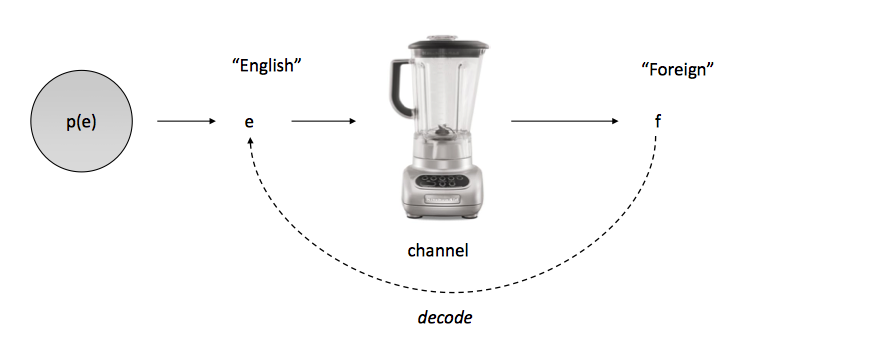
$$
\begin{aligned}
\hat e & = argmax_e p(e|f) \\
& = argmax_e {p(e) p(f|e) \over p(f)} \\
& = argmax_e p(e) p(f|e) \\
\end{aligned}
$$
其中
- p(e): language model
判断产生的句子是否通顺,是否符合语法,是否地道(fluent, grammatical, idiomatic)
一般会用 ngram 模型 - p(f|e): translation model/channel model
其实是一个翻转的翻译概率(reverse translation probability),看把目标语言(English sentence)翻译成源语言(foreign sentence)的概率,通常用 MLE 估计,需要注意泛化问题
保证足够多的翻译可能
p(e) language model 的问题很好解决,见NLP 笔记 - Language models and smoothing,难点是怎样确定 p(f|e),第一个想法自然是直接用 MLE,然而问题是句子实在太多,这种方法很难泛化。
$$P(f|e)={count(f,e) \over count(e)}$$
所以想到的是能不能从 lexical 层面着手,先进行词对词的翻译,然后再进行词的排序,也就是下面要讲的 Lexical Translation Model。
Lexical Translation
我们怎样翻译一个单词?最简单粗暴的方法当然是从字典(dictionary)里找它!然而一个单词可能有不同的 sense/registers/inflections,也就会有不同的翻译,怎么办?用单词频率来计算 MLE p(e|f,m)
其中,
- e: 完整的目标句(English sentence)
e = {$e_1, e_2, … ,e_m$} - f: 完整的源句(Foreign sentence)
f = {$f_1, f_2, …, f_n$}
我们作出以下假设
- e 的每个单词 $e_i$ 从 f 的某个单词(exactly one word)产生
- 我们需要找词与词之间的对应关系,才能进行词的翻译,把对应关系看做语料里的隐变量(latent alignment),用 $a_i$ 表示 $e_i$ 来自于 $f_{e_i}$ 这个对应关系
- 给定对齐 a,翻译决策是条件独立(conditionally independent)的,仅依赖于 aligned source word $f_{e_i}$
于是就有下面这个公式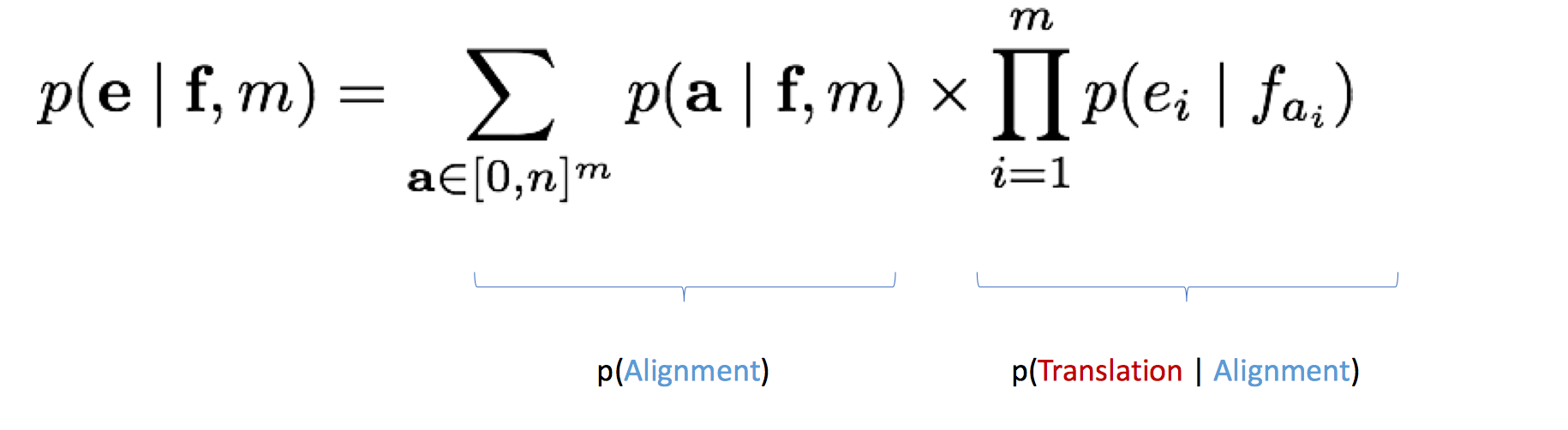
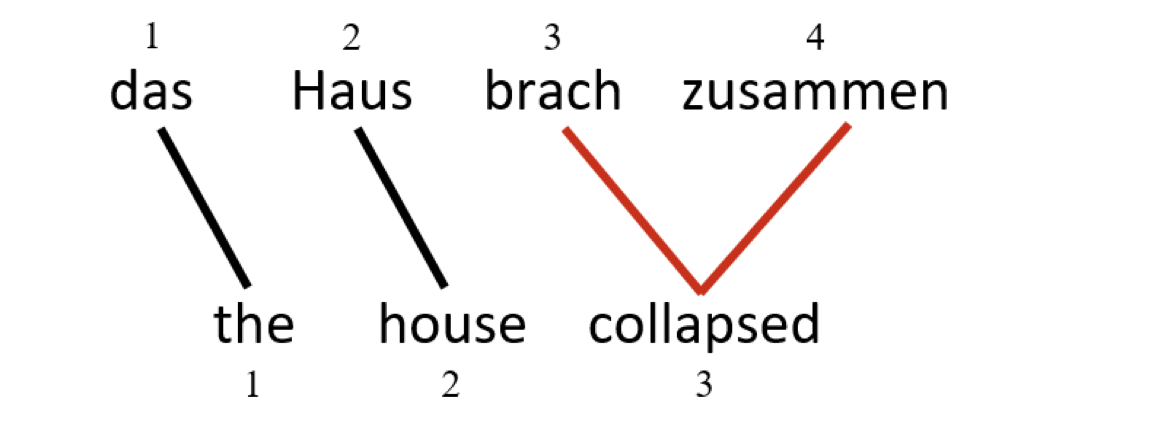
Representing Word Alignment
如何表示单词的对齐?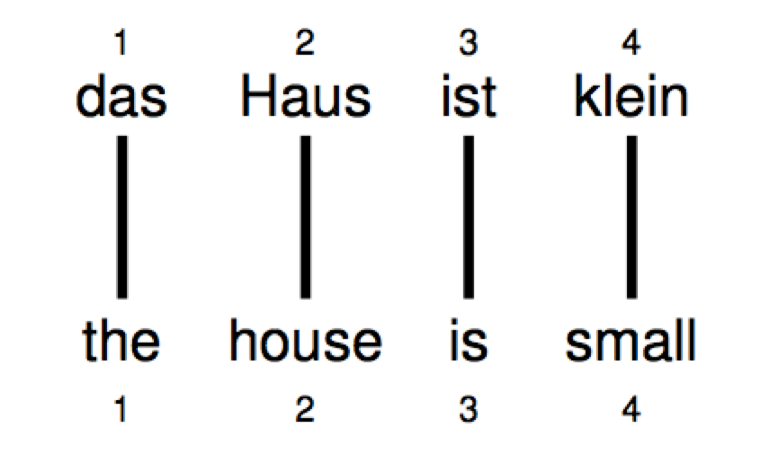
上图的表示就是 $a = (1,2,3,4)^T$
Reorder
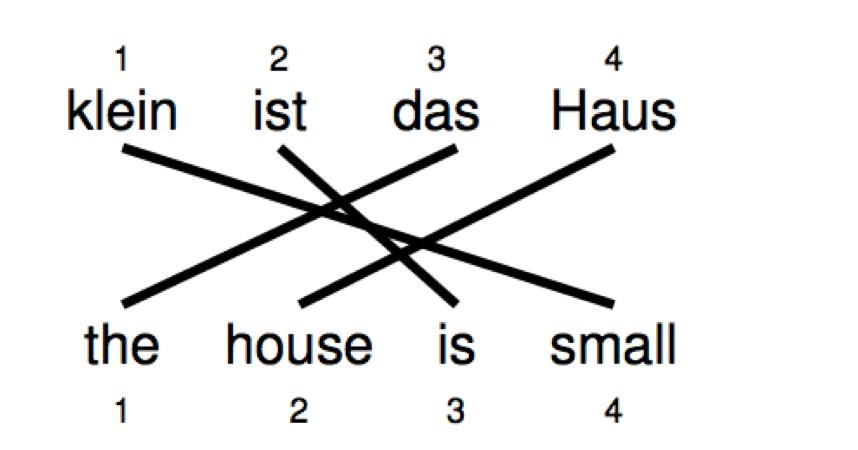
当然在翻译过程中单词的顺序可能会被打乱,上图的表示就是 $a = (3,4,2,1)^T$
Word Dropping
有些源语言的单词可能根本不会被翻译
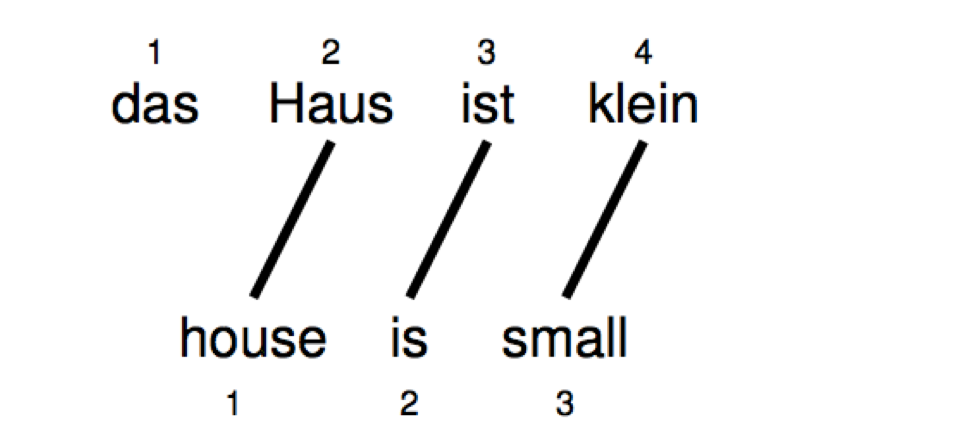
=> $a = (2,3,4)^T$
Word Insertion
有些时候,翻译过程中我们需要添加单词,然而这些单词必须是可以被解释的,所以通常我们会再源语句上加一个 NULL token
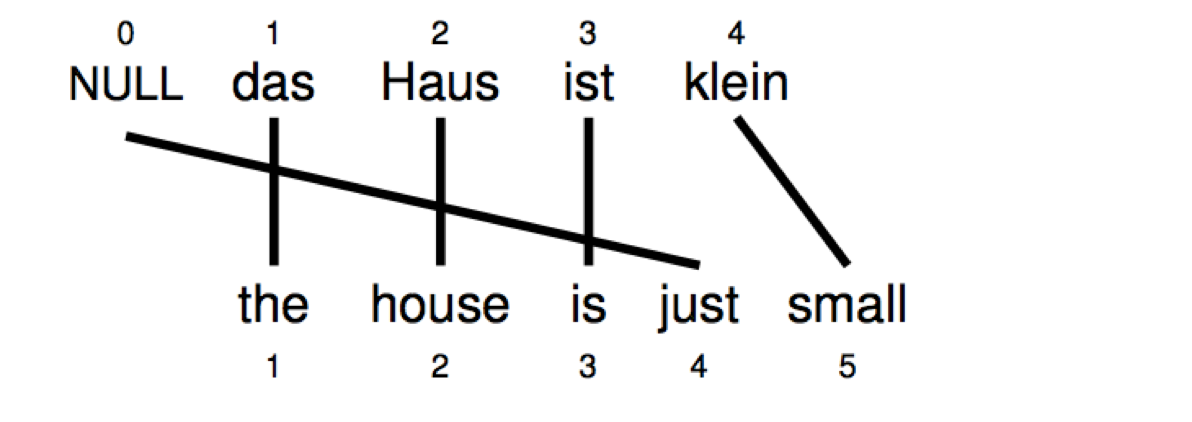
=> $a = (1,2,3,0,4)^T$
One-to-many Translation
一个源单词可能被翻译成多个目标单词的组合
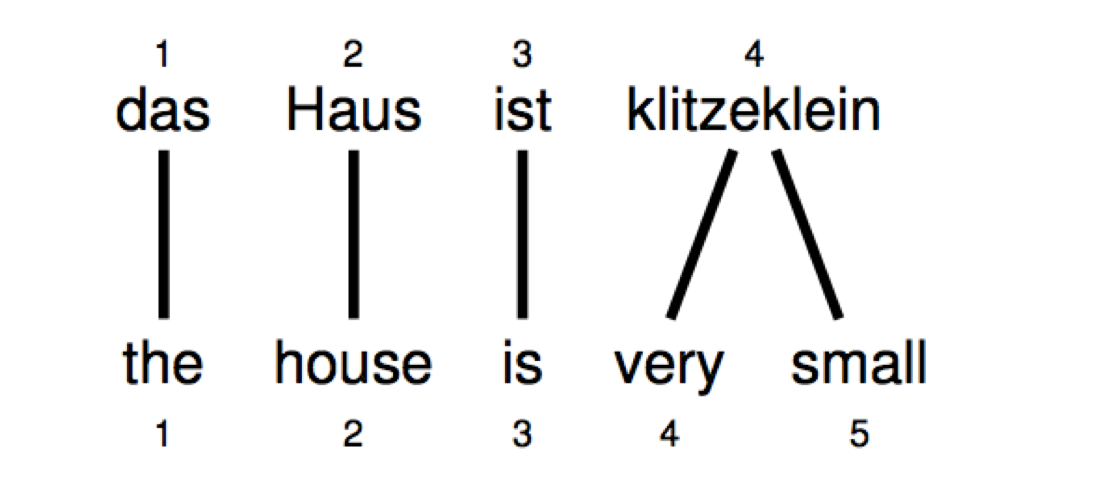
=> $a = (1,2,3,4,4)^T$
Many-to-one Translation
多个源单词的组合也可以被翻译成一个目标单词,然而! 在 lexical translation 中,并不支持这种翻译
=> $a = ??? a = (1,2,(3,4)^T)^T ?$
Learning - EM algorithm
怎样来训练得到词对齐呢 P(e|f)?可以用 EM 算法
- 选择 random(or uniform) 的初始参数对模型进行初始化
- 用现有参数,计算训练数据中每个 target word 的 alignments $p(a_i|e,f)$ 的期望值
- 计算 MLE,得到更好的参数,对模型进行更新
- 反复迭代直至收敛
1. 假设对齐概率分布是均匀的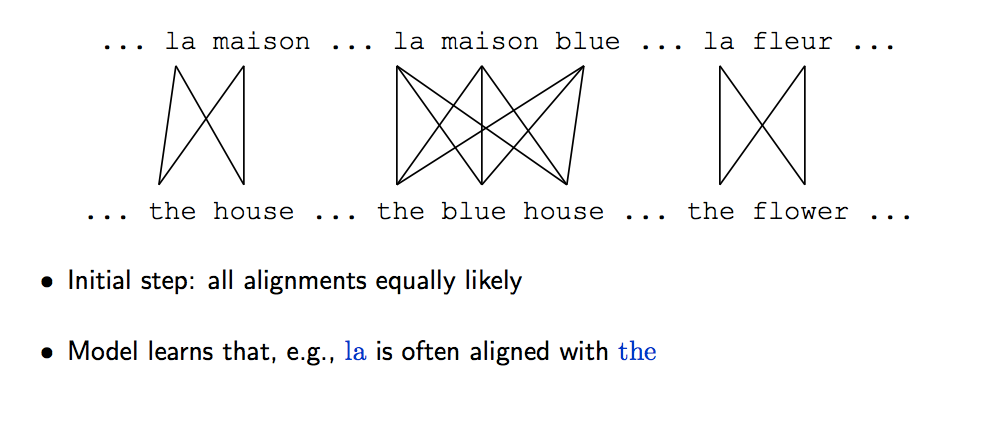
2.发现 la 和 the 的对应关系更明显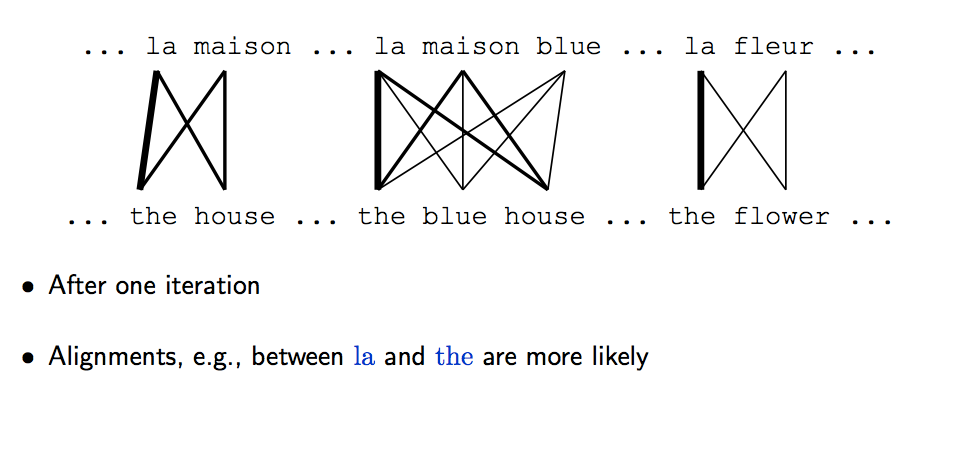
3.更新参数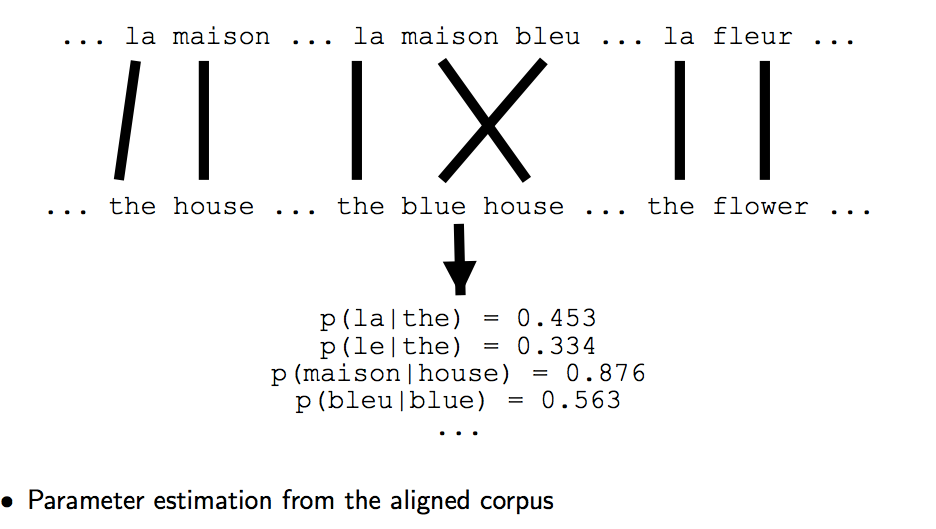
4.反复迭代直至收敛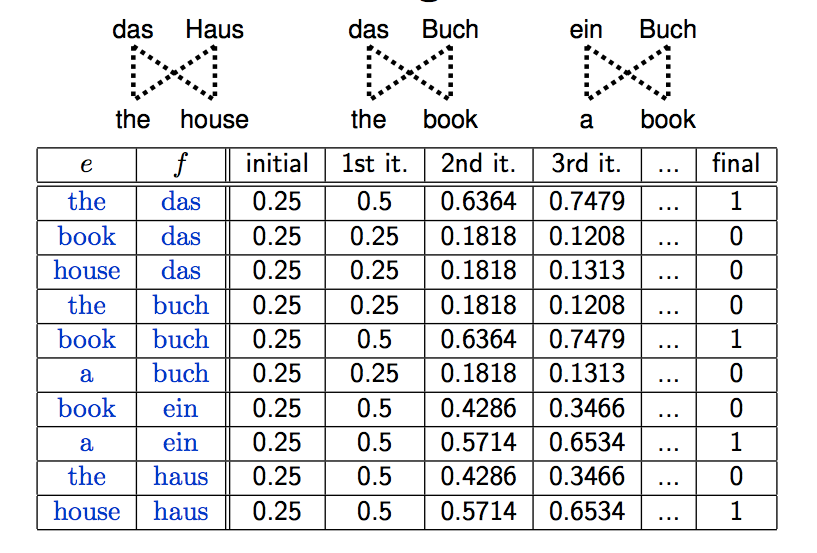
举一个简单的中译英的例子(pls forgive my poor handwriting : ( )

IBM Model1
IBM Model 1 是最为基本的翻译模型,也是一个最简单的基于词汇的翻译模型,除了上面提到的假设外,该模型还做出了其他假设
- m 个词的对齐决策是相互独立的
- 每个 $a_i$ 在所有源单词和 NULL 上的对齐分布是 uniform 的

得到翻译概率后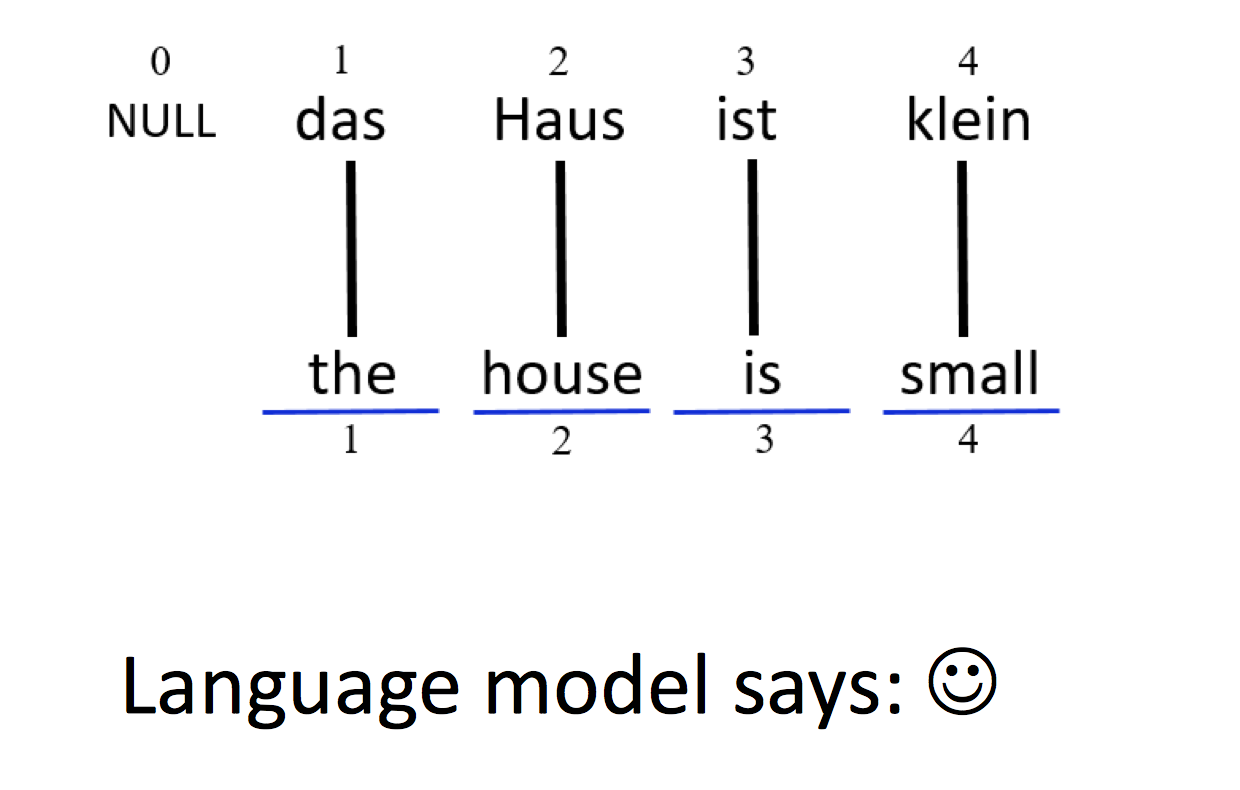
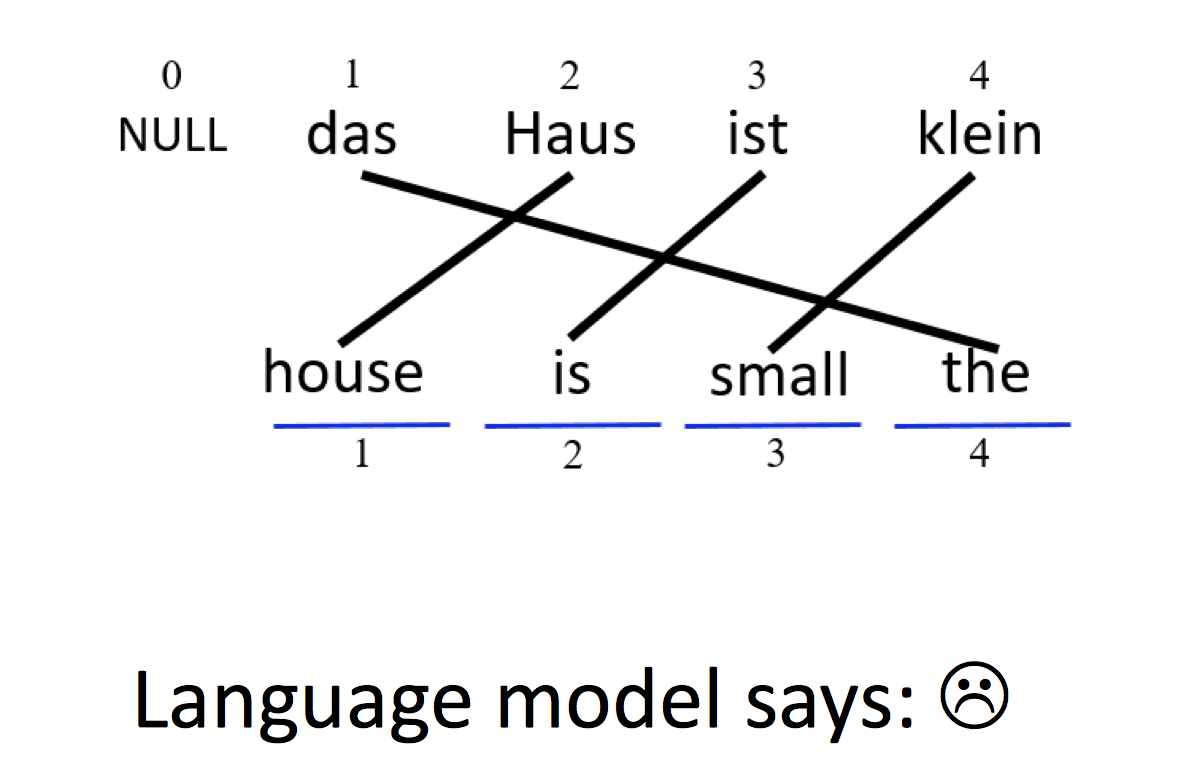
Log-linear model
还有一种模型是把上面提到的各种概率/模型作为特征,用对数线性模型(如逻辑回归,最大熵模型等)将各种特征结合起来,利用最小错误率调参等方法照到合适的特征权重。其实就是基于各种特征,看哪种翻译组合更好的问题。这是后来整理阿里巴巴骆卫华讲座内容时看到的方法。除了 noisy model 提到的对齐模型和语言模型,讲座还讲到了调序模型,调序模型也就是把两个词/短语之间是否要换序的问题看做二分类问题,如下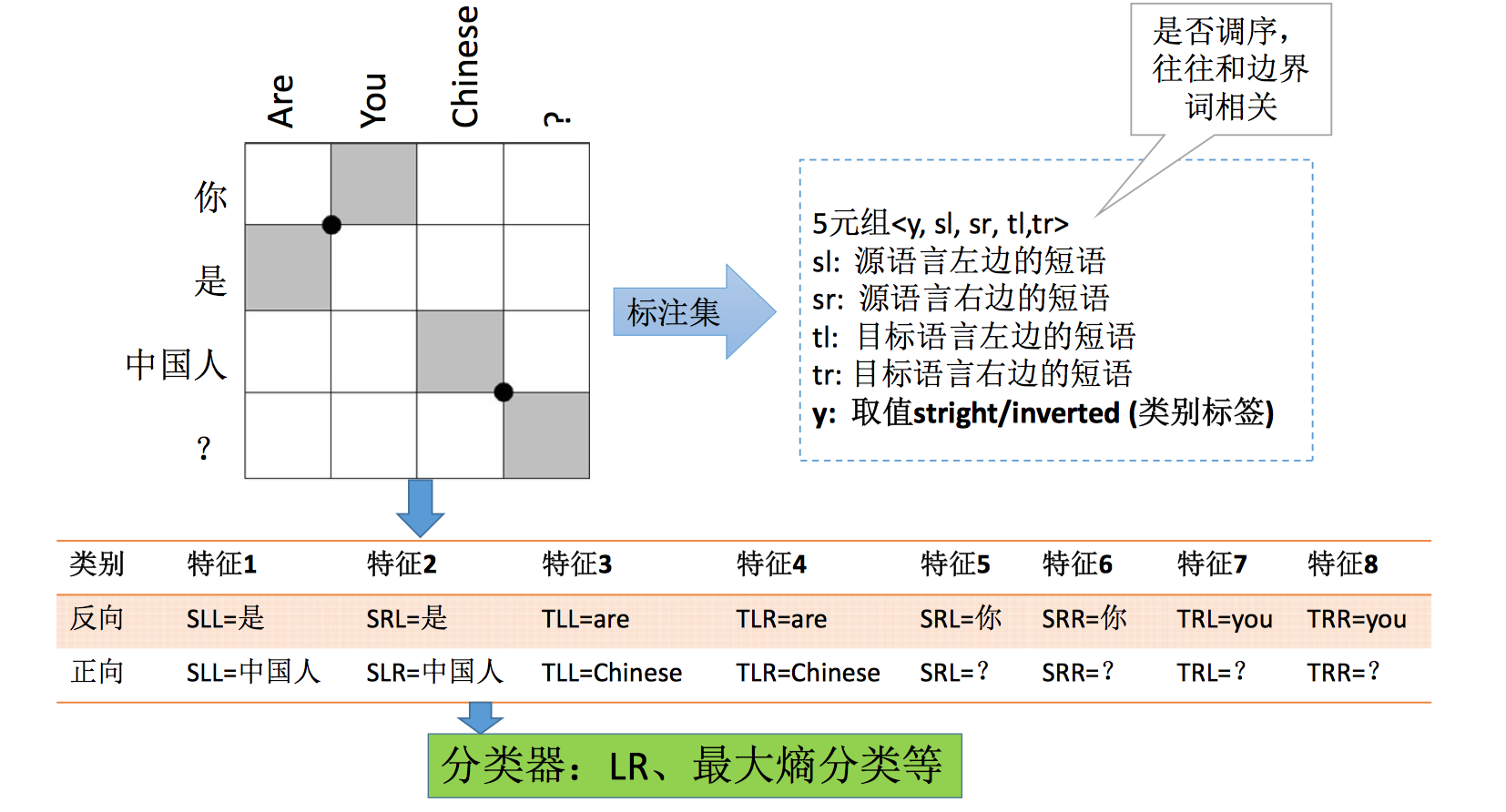
Extensions
Phrase-based MT
基于词的翻译模型没有考虑上下文,也不支持 many-to-one 的对齐,基于短语的翻译模型可以解决这个问题。短语模型需要引入多一层的隐含变量,叫做 source segmentation。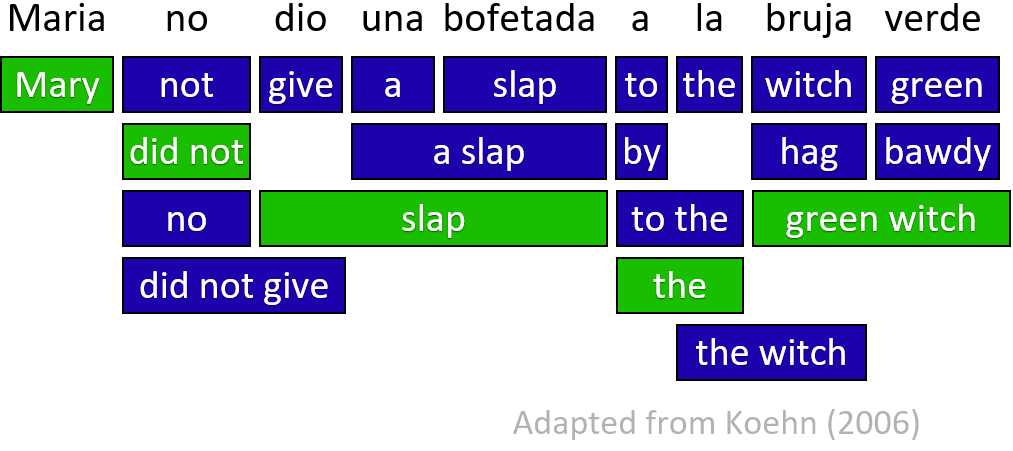
短语模型首先需要确定短语,注意短语既不能超过源语言的范围也不能超过目标语言的范围,可以用 MLE 计算源短语与目标短语的共现关系,同时要考虑的是源端到目标端之间是多对多的关系,源语言 -> 目标语言可能有多种翻译,目标语言 -> 源语言也可能有多种翻译,所以需要计算一个双向的概率。由于有些短语出现的概率非常低,所以可以把短语概率退化成词的概率来进行计算,如下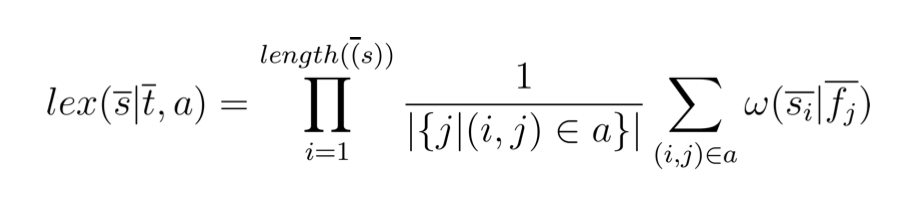
也就是 big house 大房子 的概率可以用 lex=p(大|big)p(房子|house) 来进行计算。
之后将正向概率和反向概率合并,就可以得到短语表。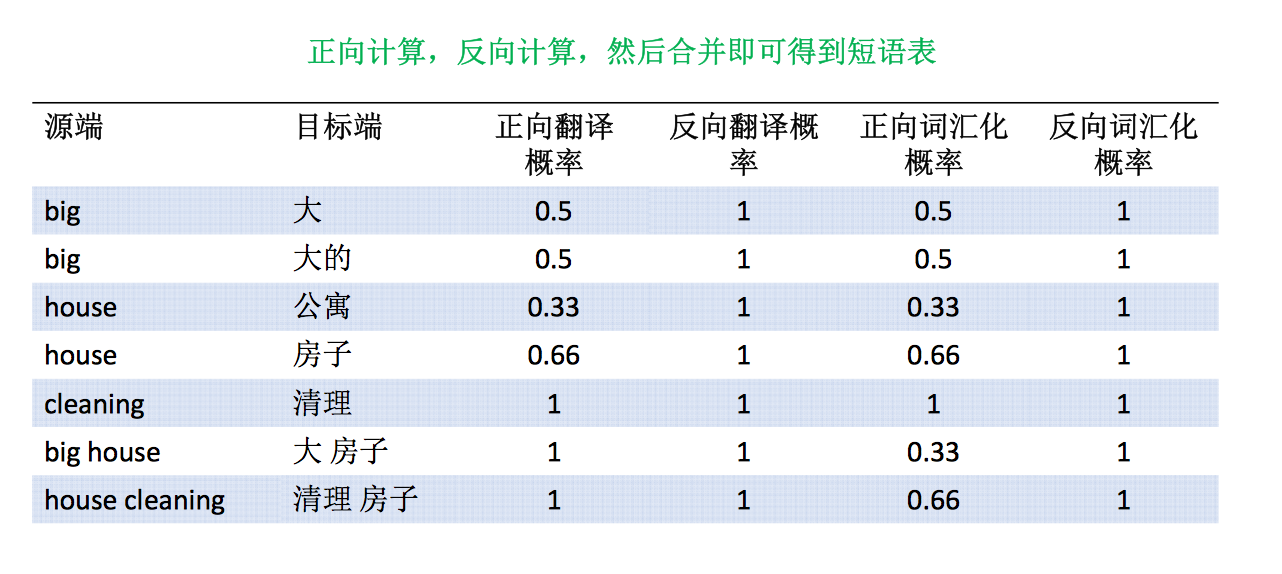
Alignment Priors
初始化参数时我们假定对齐概率的分布是 uniform 的,然而事实上我们可以加个先验概率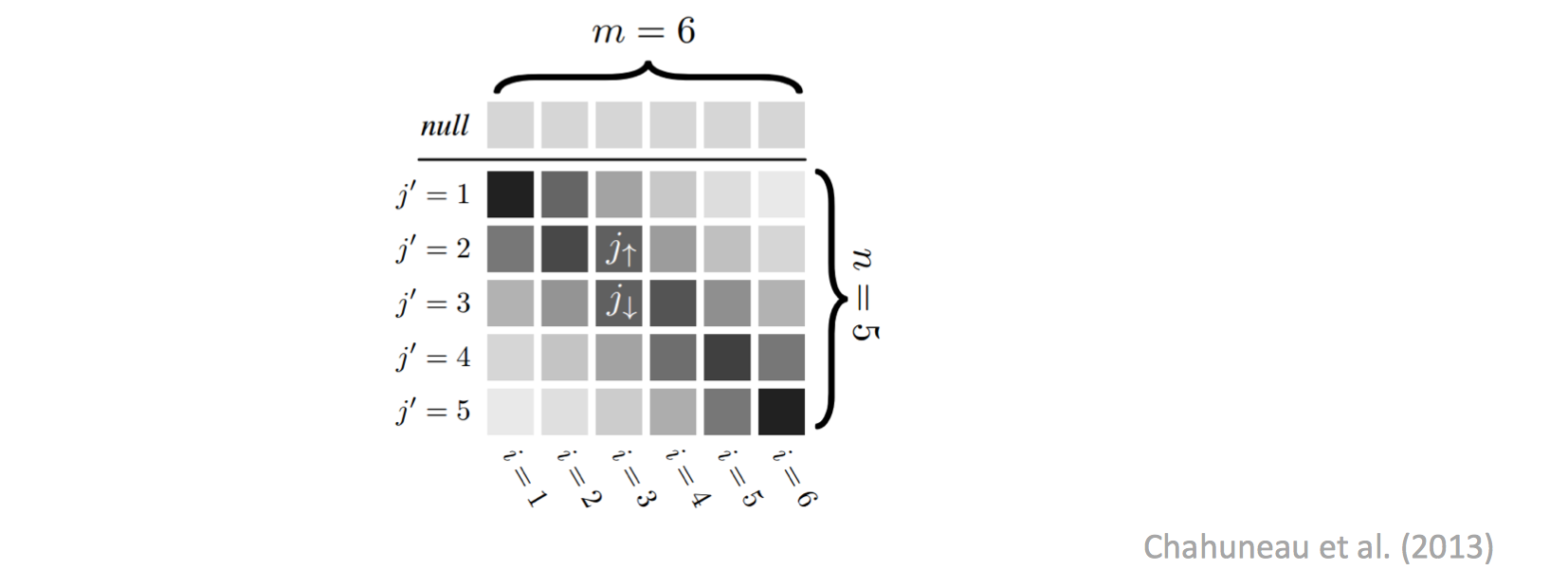
Syntactic structure
加入句法结构,也可以改善结果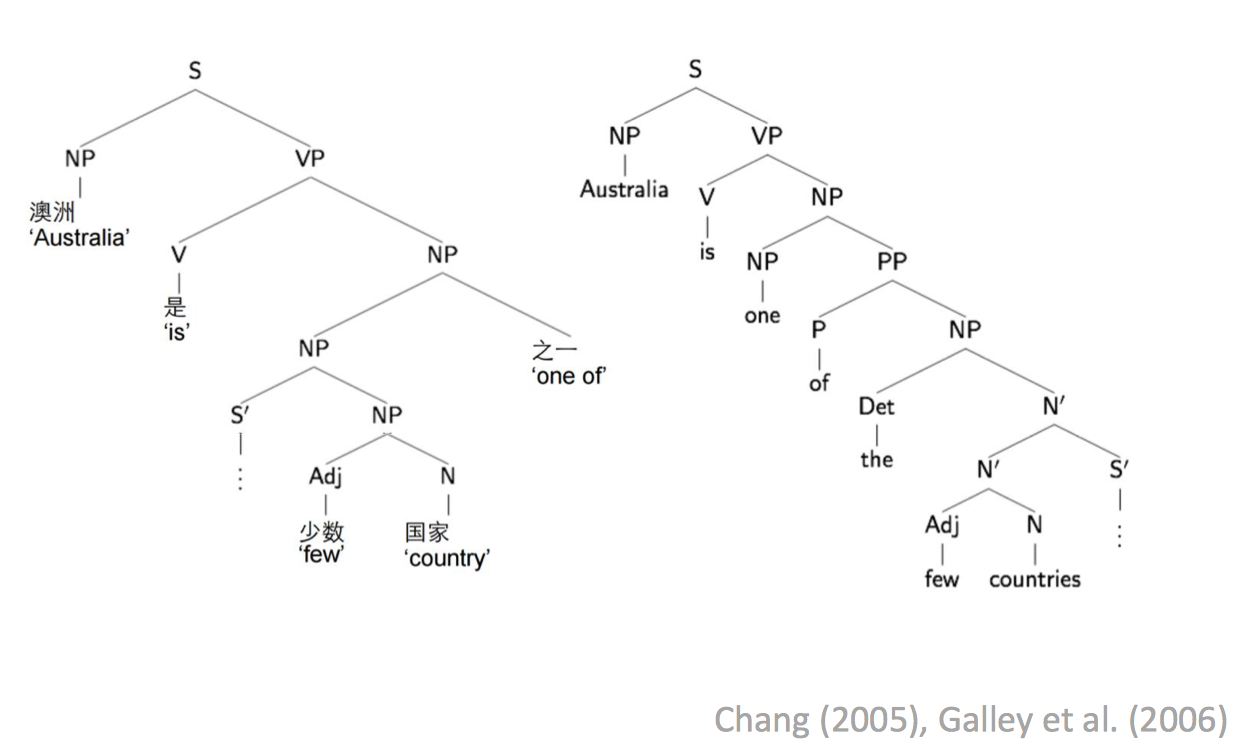
Neuron models
用神经网络来做翻译模型需要考虑的问题
- How to represent inputs and outputs?
input 的表示可以用 one-hot vector 或者 distributed representations(通常 word vector) - Neural architecture?
How many layers? (Requires non-linearities to improve capacity!)
How many neurons?
Recurrent or not?
What kind of non-linearities?

