CMU 11611 的课程笔记。主要讲了两种语义分析的方法: Lexicalized CFG 及 CCG,补充介绍了词汇语义学的一些概念。比较基础,网上参考资料较少,具体需要研究相关论文。
Semantics Road Map
- Lexical semantics
- Vector semantics
- Meaning representation languages and semantic roles
- Compositional semantics, semantic parsing
- Discourse and pragmatics
上一章讲了 FOL,它是定义良好表现良好易于理解,然而也存在一些 Issues
- “Meanings” of sentences are truth values.
- Only first-order (no quantifying over predicates).
- Not very good for “fluents” (time-varying things, real-valued quantities, etc.)
- Brittle: anything follows from any contradiction(!)
- Goedel incompleteness: “This statement has no proof”!
• (Finite axiom sets are incomplete w.r.t. the real world.) - So: Most systems use its descriptive apparatus (with extensions) but not its inference mechanisms.
Stages of Semantic Parsing
Semantic Analysis/Parsing 的目的是把自然语言转化成机器可以理解的逻辑语言如 FOL
|
|
Goal:
Learn f: sentence -> logical form
Example
Syntax-driven semantic analysis
句法驱动的语义分析(Syntax-driven semantic analysis)仅仅以词典和语法中的静态知识为输入语句指派意义表示(meaning representation),这是一个贫瘠的表示,上下文独立(context-independent),推理无关(inference-free),视野有限。然而,在某些领域,这样的表示足以产生有用的结果,另一方面,这些表示也可以作为后续处理的输入,进而产生更丰富、更有用的意义表示。
基于组合性原则的语义(Compostitional Semantics)假定一个句子的意义可以由它的几个部分(subparts)的意义组成(这显然有些例外,如 hot dog, straw man, New York 等)。
要注意的是,这个思想并不是说句子的意义仅仅依赖于句子中的词汇,而是还依赖于句中词汇的顺序、词汇所形成的群组和词汇之间的关系。也就是说,在句法驱动的语义分析中,意义表示的组成是由句法成分和关系来引导的。
给上下文无关语法规则扩充语义
基本思路是给 CFG 规则添加语义附着。从 parse tree 开始,使用 FOL 和 lambda 表达式来建立语义,过程
- Parse the sentence syntactically
- Associate some semantics to each word
- Combine the semantics of word and non-terminals recursively
- Until the root of the sentence
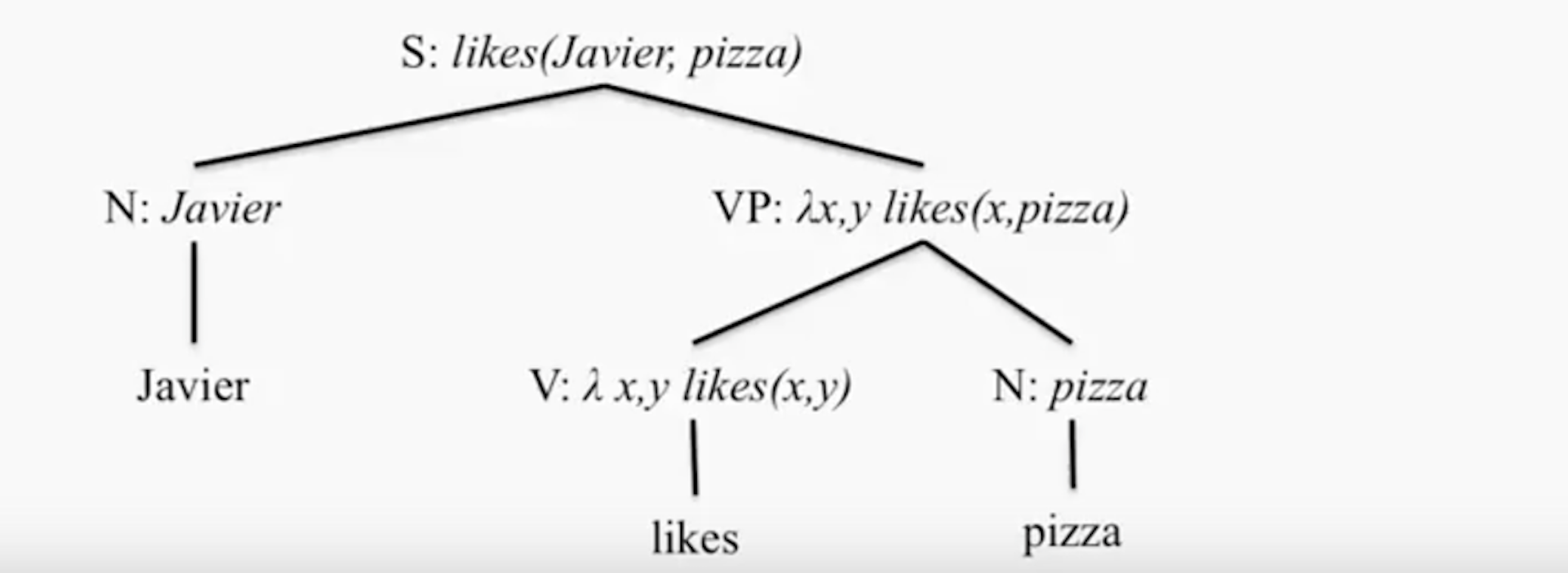
最简单的例子
稍复杂的例子,bottom-up
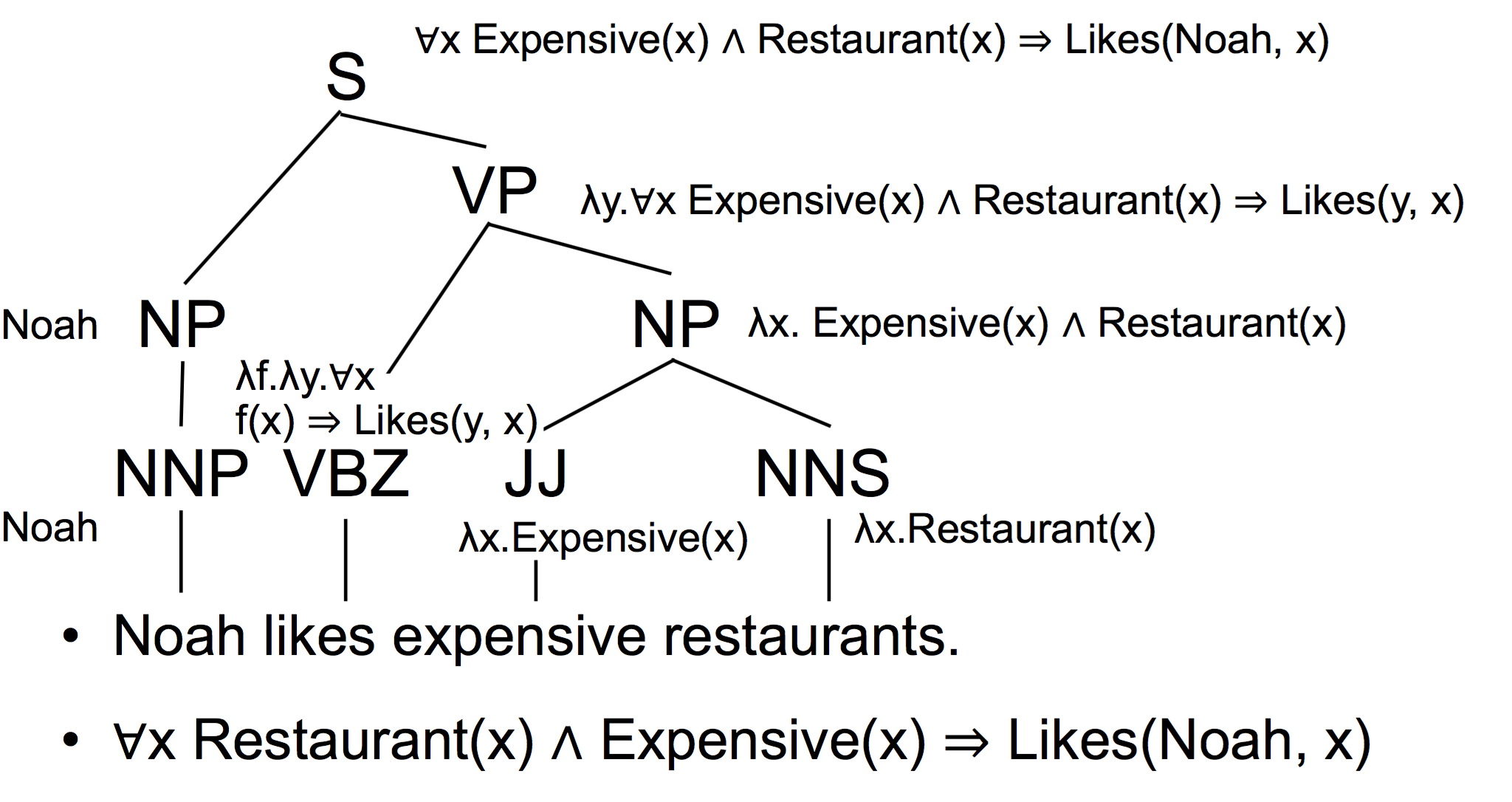
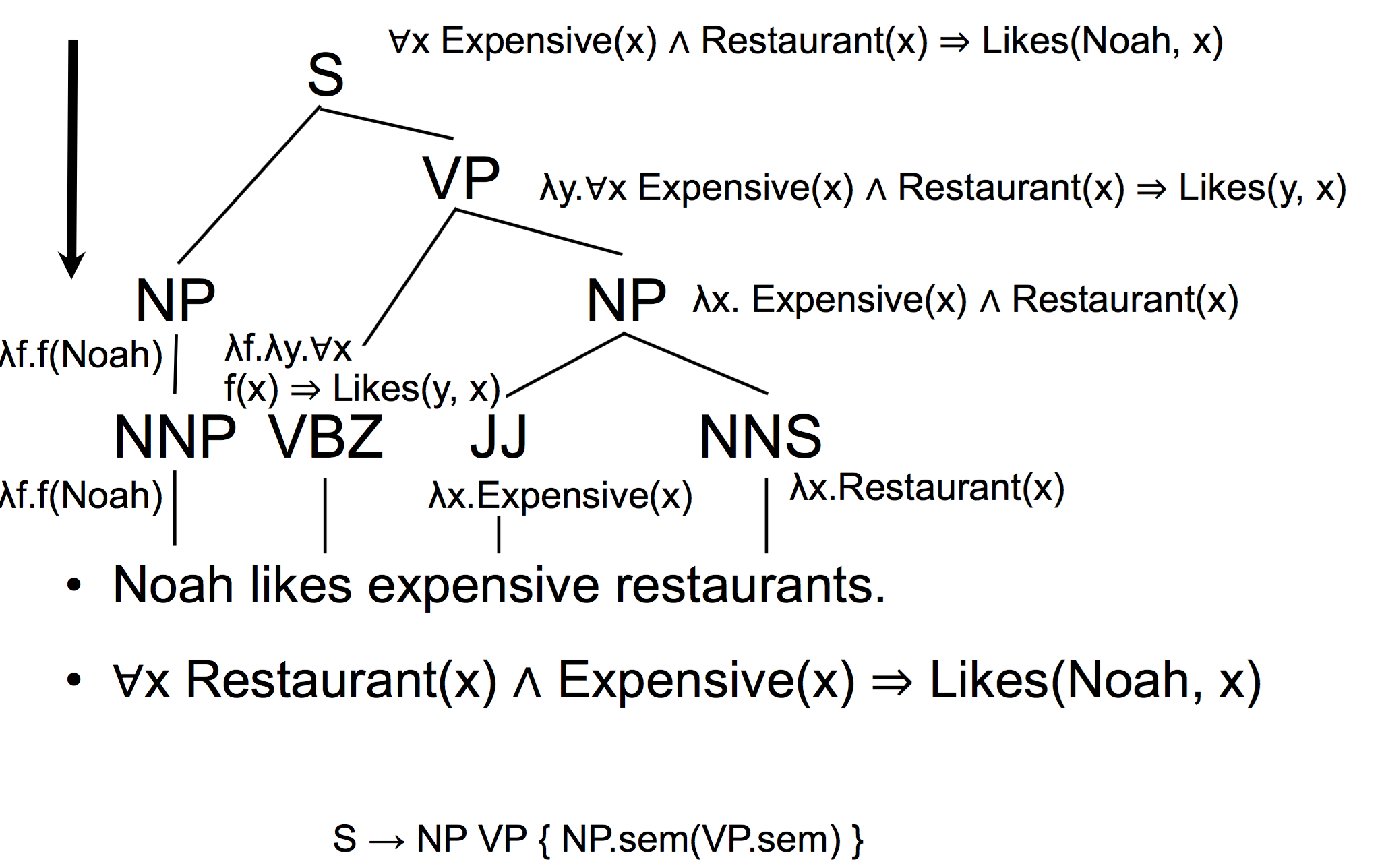
当然还有一种对应的是从上往下,follow SLP
歧义
由于句法和词汇都存在歧义,因此句法驱动的语义分析将产生成倍的歧义意义表示,解决这些歧义并不是语义分析器的工作,而是通过使用领域知识和上下文知识在候选项中进行选择的后续理解处理。当然也可以通过使用鲁棒的词性标注器、介词短语附着机制以及词义排歧原理,以减少歧义表示的数量。
Using CCG(Steedman 1996)
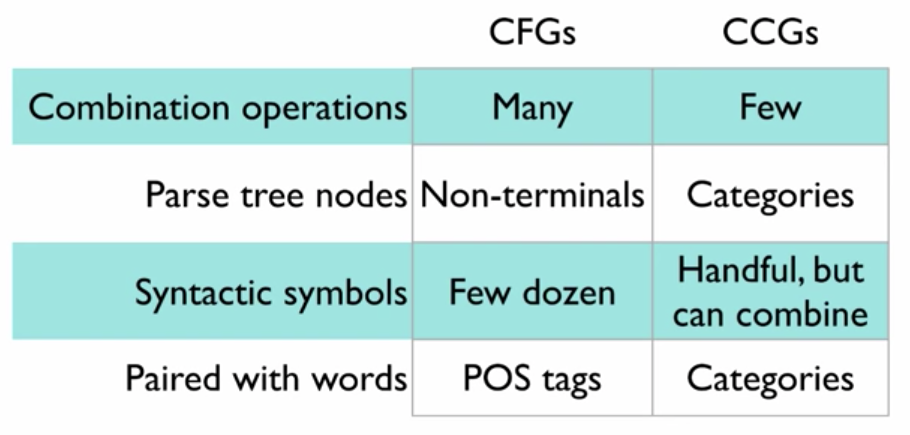
CCG(Combinatorial Categorial Grammar)的基本思路是先将词/短语和类别(categories)配对,然后逐步的对类别进行组合,通过 logical form 来捕捉句子的完整含义。
CCG assigns a category to each word and constructs a parse by combining pairs of categories to form an S. Not all pairs of categories can combine. A pair is allowed to combine if one category(e.g. A) is contained within the category next to it(e.g. B/A) and lies on the side indicated by the slash(\ for left, / for right). When two categories combine, the result is a new category, taken from the left of the slash(B in this example)
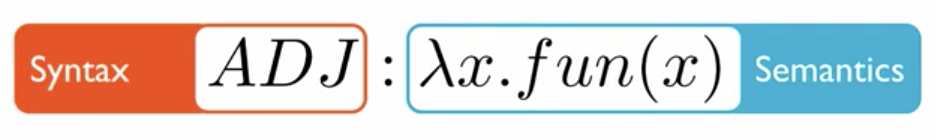
CCG Category 由两部分组成,左边是句法(syntax),右边是语义(semantics)
Syntax 包含基本符号和运算符
- Primitive symbols: N, S, NP, ADJ and PP
- Syntactic combination operator (/,)
Slashes specify argument order and direction
CCG: Five (5) grammar rules!
- Application:
– Forward: A/B + B = A A/B:S + B:T = A:S.T
– Backward: B + A\B = A B:T + A\B:S = A:S.T - Composition:
– Forward: A/B + B/C = A/C
– Backward: B\C + A\B = A\C - Coordination:
– X CONJ X’ = X” - Type raising:
– A = X/(X\A)
Semantics 包含逻辑语言,如 lambda calculus,将 syntax 和 semantics 匹配起来就形成了 CCG Category,如
(S\NP)/ADJ: $\lambda f.\lambda x.f(x)$
一个简单的例子
CCG 的优点
- 简化了组合规则(combinatory rules)
- 将复杂性从 rule 身上转移到了 (categorial) lexical entries 上
- 更紧密的与语义融合
- 句法和语义成分之间是一对一的关系
Handling Coordination
Constituent Coordination
|
|
如上面的例子可以直接通过 coordination rule 来 parse
Non-constituent coordination
|
|
然而这个例子就只能通过 Type raising 来解决
完整的例子

UW SPF
UW 有一个开源项目 University of Washington Semantic Parsing Framework (UW SPF),将语义分析的任务分成了三个子问题 Parsing -> Learning -> Modeling
Parsing choice
Note: 项目中用了 Combinatory Categorial Grammars
Learning
Note: 项目中用了 Unified learning algorithm
Semantic Modeling
更多见 Semantic Parsing with Combinatory Categorial Grammars
CCGs vs. CFGs
补充:词汇语义学(Lexical Semantics)
词汇语义学方面的知识可以用于基于 CFG 的语义分析。先看一下词位之间以及词位的含义之间的各种关系
- 同形关系(homonymy) 指词形(包括字形和音形)相同但意义不同的词之间的关系
- 多义关系(polysemy) 指单个词位具有多个相关含义的概念
- 同义关系(synonymy) 指具有相同意义的不同词位之间的关系
- 上下位关系(hyponymy) 指具有类别包含(class-inclusion)关系的词位之间的关系
我们知道,意义表示是以基本的谓词-论元结构为基础的,在组成这样的表示时,我们假定词位的某些类倾向于促成谓词和谓词-论元结构,而其他的倾向于促成论元。这里探讨的是,词位的各个意义表示之间具有可分析的内在结构,正是这个内在结构与语法相结合,才确定了良构句子中词位之间的关系。
Thematic Roles
题元角色(Thematic Roles)是一组范畴,为刻画动词的某些 argument 的特征提供了浅层语义语言,比如下面两个句子
|
|
通过 FOPC 可以得到下面的部分表示
可以发现,动词 break 和 open 的主语的角色分别为 Breaker 和 Opener,然而每种可能发生事的深层角色(deep role)都是特定的,比如 Breaking 事件中的 Breaker,Opening 事件中的 Opener,Eating 事件中的 Eater 等,但 Breaking 和 Opener 有一些共同点,它们都是有意志的行为人,常常是有生命的,并且对它们的事件负有直接因果责任,题元角色(Thematic Roles)就是表示这种共性的一种方式,比如说我们把这两个动词的主语称为 agent。
常用的 Thematic roles 及其定义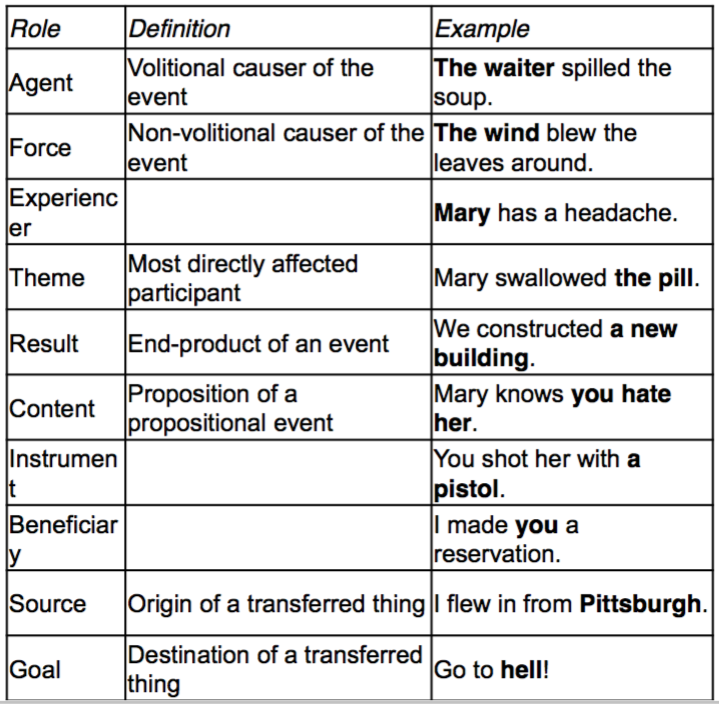
The Thematic Grid or Case Frame shows
• How many arguments the verb has
• What roles the arguments have
• Where to find each argument
For example, you can find the agent in the subject position

Thematic roles 的另一个用途是,通过题元层级(thematic hierarchy)来决定主语和宾语,如上,如果一个动词的题元描述包括一个 AGENT,一个 INSTRUMENT,和一个 THEME,那么 AGENT 被实现为主语,如果题元描述值包括一个 INSTRUMENT 和一个 THEME,那么 INSTRUMENT 成为主语。
Verb Subcategorization
动词可以有不同数量的 argument,以及不同的 VP 规则,应用 SUBCAT 特征,可以创建 allowed arguments 的集合。
Selectional Restriction
选择限制(selectional restriction)是一种语义约束,通过容许词位对那些能够与它们在一个句子中出现的词位和短语设置某些语义限制,来增加语义角色。举个例子,看下面四个句子,前两个句子很正常,我们可以说 dog, child 是开心的,因为他们是动物,有情绪,所以可以把他们和 happy 联系起来,然而后两个句子就非常的诡异,事实上它们违反了选择限制(selectional restriction)。
|
|
我们可以通过面向事件的意义表示,来捕捉选择限制的语义,像 eat 这样的动词的语义贡献可以表示为
所有关于 y(theme 角色的填充者)的信息是:通过 THEME 关系,与 Eating 事件相关联,为加入 y 必须是可食用的东西这一选择限制,我们可以通过简单添加一个新的 term 来实现,如下
当遇到像 ate a hamburger 这样的短语,语义分析器能够形成如下的表示
这个表示是完全合理的,假如在知识库中有一个合理的事实集,y 在范畴 Hamburger 中的成员属性与它再范畴 EdibleThing 中的成员属性是一致的。相反,ate a takeoff 这样的短语是不合理的,因为 takeoff 中的成员属性与范畴 EdibleThing 中的成员属性不一致。然而这种方法预先假定存在一个大规模的关于组成选择限制的概念的事实逻辑库,遗憾的是,尽管这类知识库正在建设,但还没有普遍使用,而且几乎没有达到任务所需规模的知识库。
一个更实际的方法是利用 WordNet 信息库中的上下位关系,这种方法中,语义角色的选择限制是用 WordNet 的同义集而不是逻辑概念来表述的,如果填充语义角色的词位是由谓词给语义角色指定的同义集的上位词中的一个,那么这个给定的意义表示可以被判断为良构的。
如在 WordNet 的 60,000 个同义集中,有一个 {food, nutrient} 的同义集,我们可以将它指定为对动词 eat 的 THEME 角色的选择限制,也就是将这个橘色的填充者限定为再这个同义集或其下位词中,看下图,hamburger 的上位关系链显示它确实为 food

