网上教程太少,只能自己摸索了。关于怎么用 python 来调用 Stanford Parser。–持续更新中–
Tregex 用来做句子层面的识别及操作,简单理解就是关于 tree 的 regex。一些语法知识见The Wonderful World of Tregex。用 java 来调用 API 更简单一点,然而项目需要,所以这一篇讲怎么用 python 来调用。
Stanford CoreNLP
Stanford NLP 的工具还可以有 Server 端!简直是 python 使用者一大福利。
下载安装CoreNLP Server
先测试一下
ok,可以运行,然后开启 server
|
|
之后就可以通过 python 发送 http 请求来调用接口啦~ Python 代码
结果
Tregex 的基本语法
之后再慢慢补充吧。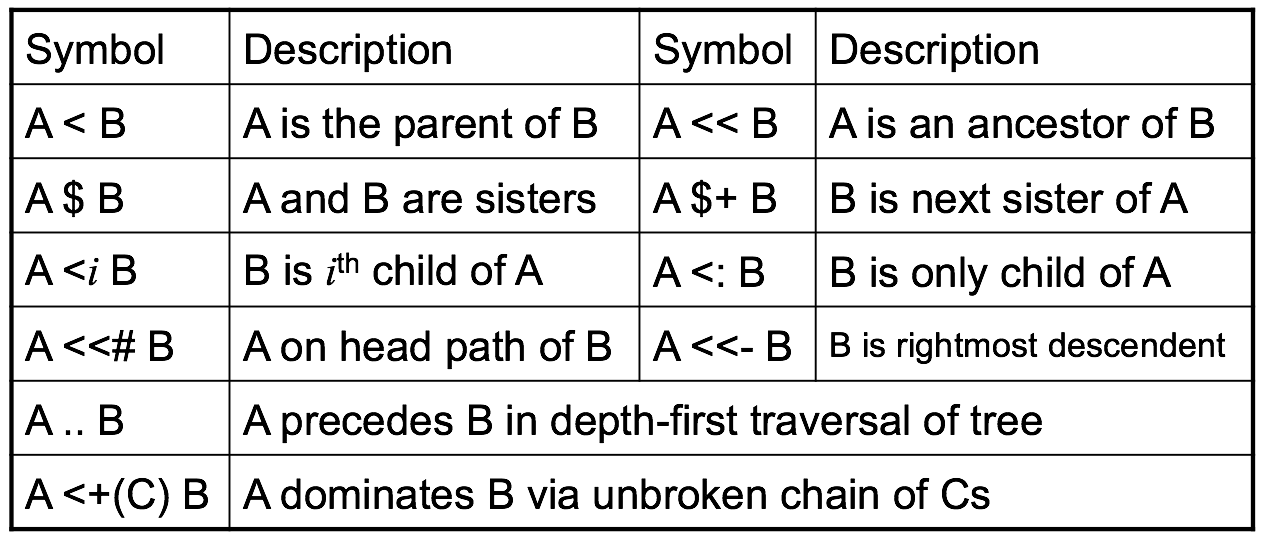
示例
假定已经安装好了 nltk, stanford nlp 各类包,并设置好了路径。
Parse Tree from NLTK
|
|
输出
Parse Tree from CoreNLP Server
|
|
输出
annotators 可以加其他 parameter,得到更多的 ner, lemma 等信息,输出也可以设定为 json 或 html 等格式。
同位语
得到 parse tree 的同位语部分,规则如下,第一个 NP 是 parent,后面两个 NP 是 sisters,中间由逗号隔开,这是同位语的基本形式。
代码:
输出
再进一步处理
输出:

