Stanford NLP 关于信息抽取的笔记,只是一个比较笼统的介绍,两块内容,命名实体识别(Named Entity Recognition)和序列模型(Sequence Model)。提到的具体算法,之后整理后再贴出~
信息抽取(IE) 系统抽取的往往是清楚的、事实性的信息,如:Who did what to whom when? 这种比较结构化的信息。有很多方面的应用,最简单的比如说从公司报告中抽取盈利数据、总部信息、董事会成员等等信息,或者 Apple,Google mail 抽取日期时间,给出加入日历的建议这种(如下图),非常 low-level 的信息抽取。

Named Entity Recognition(NER)
命名实体识别(NER)在信息抽取中扮演着重要角色,它有两个关键词:find & classify,找到命名实体,并进行分类。
应用:
- 命名实体作为索引和超链接
- 情感分析的准备步骤,在情感分析的文本中需要识别公司和产品,才能进一步为情感词归类
- 关系抽取(Relation Extraction)
- QA 系统,大多数答案都是命名实体
Machine learning approach
非常标准的机器学习方法
Training:
- 收集代表性的训练文档
- 为每个 token 标记命名实体(不属于任何实体就标 Others O)
- 设计适合该文本和类别的特征提取方法
- 训练一个 sequence classifier 来预测数据的 label
Testing:
- 收集测试文档
- 运行 sequence classifier 给每个 token 做标记
- 输出命名实体
编码方式
看一下下面两种给 sequence labeling 的编码方式,IO encoding 简单的为每个 token 标注,如果不是 NE 就标为 O(other),所以一共需要 C+1 个类别(label)。而 IOB encoding 需要 2C+1 个类别(label),因为它标了 NE boundary,B 代表 begining,NE 开始的位置,I 代表 continue,承接上一个 NE,如果连续出现两个 B,自然就表示上一个 B 已经结束了。
在 Stanford NER 里,用的其实是 IO encoding,有两个原因,一是 IO encoding 运行速度更快,而是在实践中,两种编码方式的效果差不多。IO encoding 确定 boundary 的依据是,如果有连续的 token 类别不为 O,那么类别相同,同属一个 NE;类别不相同,就分割,相同的 sequence 属同一个 NE。而实际上,两个 NE 是相同类别这样的现象出现的很少,如上面的例子,Sue,Mengqiu Huang 两个同是 PER 类别,并不多见,更重要的是,在实践中,虽然 IOB encoding 能规定 boundary,而实际上它也很少能做对,它也会把 Sue Mengqiu Huang 分为同一个 PER,这主要是因为更多的类别会带来数据的稀疏。
特征选择
Features for sequence labeling:
再来看两个 feature
Word substrings
Word substrings 的作用是很大的,以下面的例子为例,NE 中间有 ‘oxa’ 的十有八九是 drug,NE 中间有 ‘:’ 的则大多都是 movie,而以 field 结尾的 NE 往往是 place。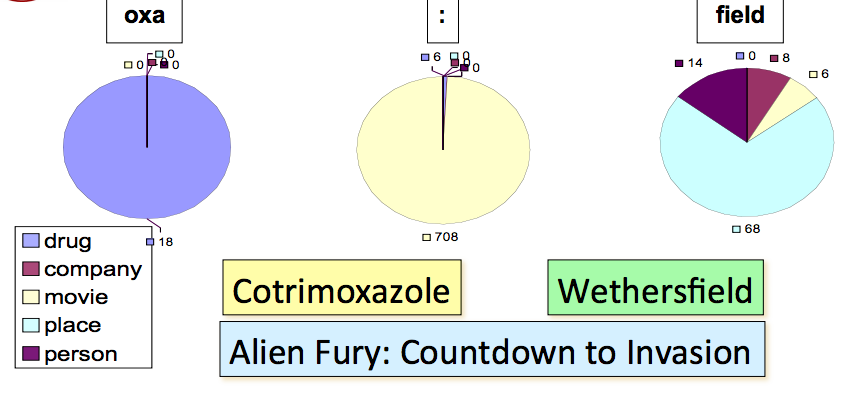
Word shapes
可以做一个 mapping,把单词长度(length)、大写(capitalization)、数字(numerals)、希腊字母(Greek eltters)、单词内部标点(internal punctuation)都作为特征。
如下面的表,把所有大写字母映射为 X,小写字母映射为 x,数字映射为 d…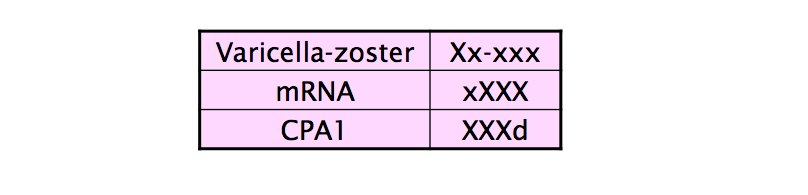
Evaluation
评估 IR 系统或者文本分类的任务,我们通常会用到 precision,recall,F1 这种 set-based metrics,见信息检索评价的 Unranked Boolean Retrieval Model 部分,但是在这里对 NER 这种 sequence 类型任务的评估,如果用这些 metrics,可能会有一些问题,如 boundary error。因为 NER 的评估是按每个 entity 而不是每个 token 来计算的,我们需要看 entity 的 boundary。
以下面一句话为例
正确的 NE 应该是 First Bank of Chicago,类别是 ORG,然而系统识别了 Bank of Chicago,类别 ORG,也就是说,右边界(right boundary)是对的,但是左边界(left boundary)是错误的,这其实是一个常见的错误。
|
|
而计算 precision,recall 的时候,我们会发现,对 ORG - (1,4) 而言,系统产生了一个 false negative,对 ORG - (2,4) 而言,系统产生了一个 false positive!所以系统有了 2 个错误。F1 measure 对 precision,recall 进行加权平均,结果会更好一些,所以经常用来作为 NER 任务的评估手段。另外,专家提出了别的建议,比如说给出 partial credit,如 MUC scorer metric,然而,对哪种 case 给多少的 credit,也需要精心设计。
Sequence models
下一篇博客会具体讲 MEMM 和 CRF,这里大概整理下课程提到的内容,当做是一个预告好了。
MEMM inference
NLP 的很多数据都是序列类型的,像 sequence of characters, words, phrases, lines, sentences,我们可以暂时把任务当做是给每一个 item 打标签,如下图所示。
对于 Maximum Entropy Markov Model (MEMM) 及 Conditional Markov Model (CMM) 这类模型,分类器在给定 observation 以及之前的决策下,每一次做一个决策,以当前观察和之前的决策为基础。
For a Conditional Markov Model (CMM) a.k.a. a Maximum Entropy Markov Model (MEMM), the classifier makes a single decision at a time, conditioned on evidence from observations and previous decisions
在每个 decision point,使用了右边表格里的所有特征。
流程如图所示,非常清楚。Inference in Systems: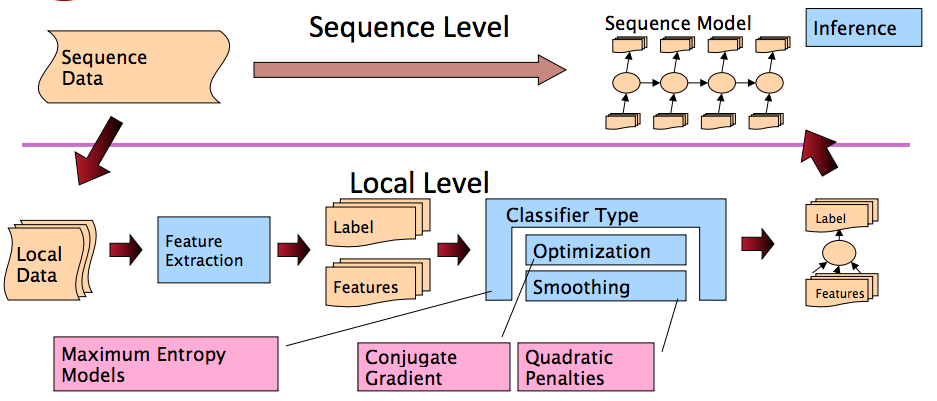
Greedy Inference
讨论下各种 inference
像上面所说的,”decide one sequence at a time and move on”,实际上是一个 greedy inference。举个例子,在词性标注中,可能模型在位置 2 的时候挑了当前最好的 PoS tag,但是到了位置 4 的时候,其实发现位置 2 应该有更好的选择,然而,greedy inference 并不会 care 这些。因为它是贪婪的,只要当前最好就行了。
Greedy Inference:
优点:
- 速度快,没有额外的内存要求
- 非常易于实现
- 有很丰富的特征,表现不错
缺点:
- 贪婪
Beam Inference
- 在每一个位置,都保留 top k 种可能(当前的完整序列)
- 在每个状态下,考虑上一步保存的序列来进行推进
优点:
- 速度快,没有额外的内存要求
- 易于实现(不用动态规划)
缺点:
- 不精确,不能保证找到全局最优
Viterbi Inference
- 动态规划
- 需要维护一个 fix small window
优点:
- 非常精确,能保证找到全局最优序列
缺点:
- 难以实现远距离的 state-state interaction
CRFs
另一种 sequence model 是条件随机场(Coditional Random Fields, CRFs),是一个完整的序列模型(whole-sequence conditional model)而不是局部模型的连接。
训练会比较慢,但是可以防止 causal-competition biases。

