关于如何建立一个 QA 系统。整理自 Stanford NLP 公开课及 Jurafsky & Chris Manning 的 NLP book draft。
Single Document QA
基于某个 document 的 QA 系统,一般来说假定问题答案出现在了文档中。这是我们要做的项目,之后再具体介绍。
Question Types
- Simple (factoid) questions (most commercial systems)
简单的问题,可以用简单的事实回答,答案简短通常是一个 named entity
Who wrote the Declaration of Independence?
What is the average age of the onset of autism?
Where is Apple Computer based? - Complex (narrative) questions
稍微复杂的叙述问题,答案略长
What do scholars think about Jefferson’s position on dealing with pirates?
What is a Hajj?
In children with an acute febrile illness, what is the efficacy of single medication therapy with acetaminophen or ibuprofen in reducing fever? - Complex (opinion) questions
复杂的问题,通常是关于观点/意见
Was the Gore/Bush election fair?
IR-Based(Corpus-based) Approaches
简言之,就是用信息检索的方法来找最佳 answer,下面是 IR-based factoid AQ 的流程图,包括三个阶段,问题处理(question processing),篇章检索(passage retrieval)和答案处理(answering processing)
- Question Processing
Answer Type Detection: 分析 question,决定 answer type
Query Formulation: 形成合适的查询语句进行检索 - Passagge Retrieval
通过检索得到 top N documents
把 documents 拆分称合适的单位(unit/passage) - Answer Processing
得到候选的 answer
进行排序,选出最佳 answer
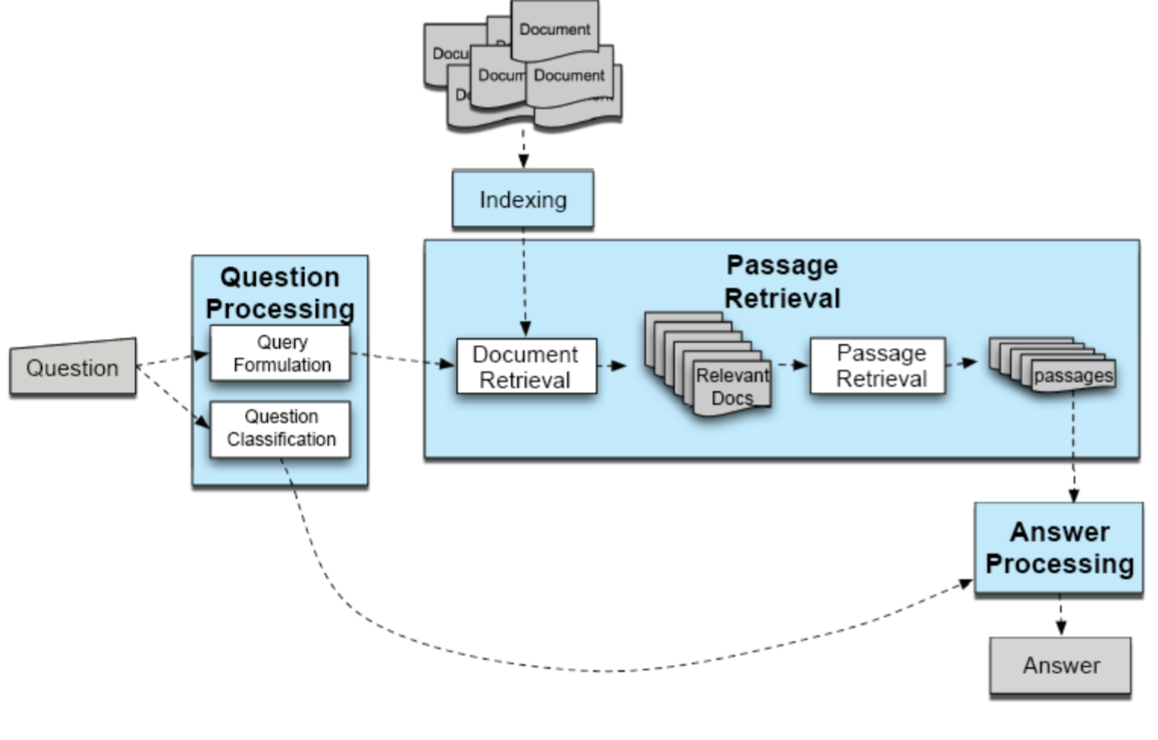
Question Processing
两个任务,确定 answer type,形成 query。有些系统还会从 question 里提取出 focus。
Answer type: the kind of entity the answer consists of (person, location, time, etc.)
Query: the keywords that should be used for the IR system to use in searching for documents
Focus: the string of words in the question that are likely to be replaced by the answer in any answer string found
这一阶段需要做的事:
E.g.
Question: Which US state capital has the largest population?
Answer type: city
Query: US state capital, largest, population
Focus: state capital
Answer Type Detection
通常而言,我们把它当作一个机器学习的分类问题
- 定义类别
- 注释训练数据,给数据打上分类标签
- 训练分类器,所用特征可以包括 hand‐written rules
Define answer types
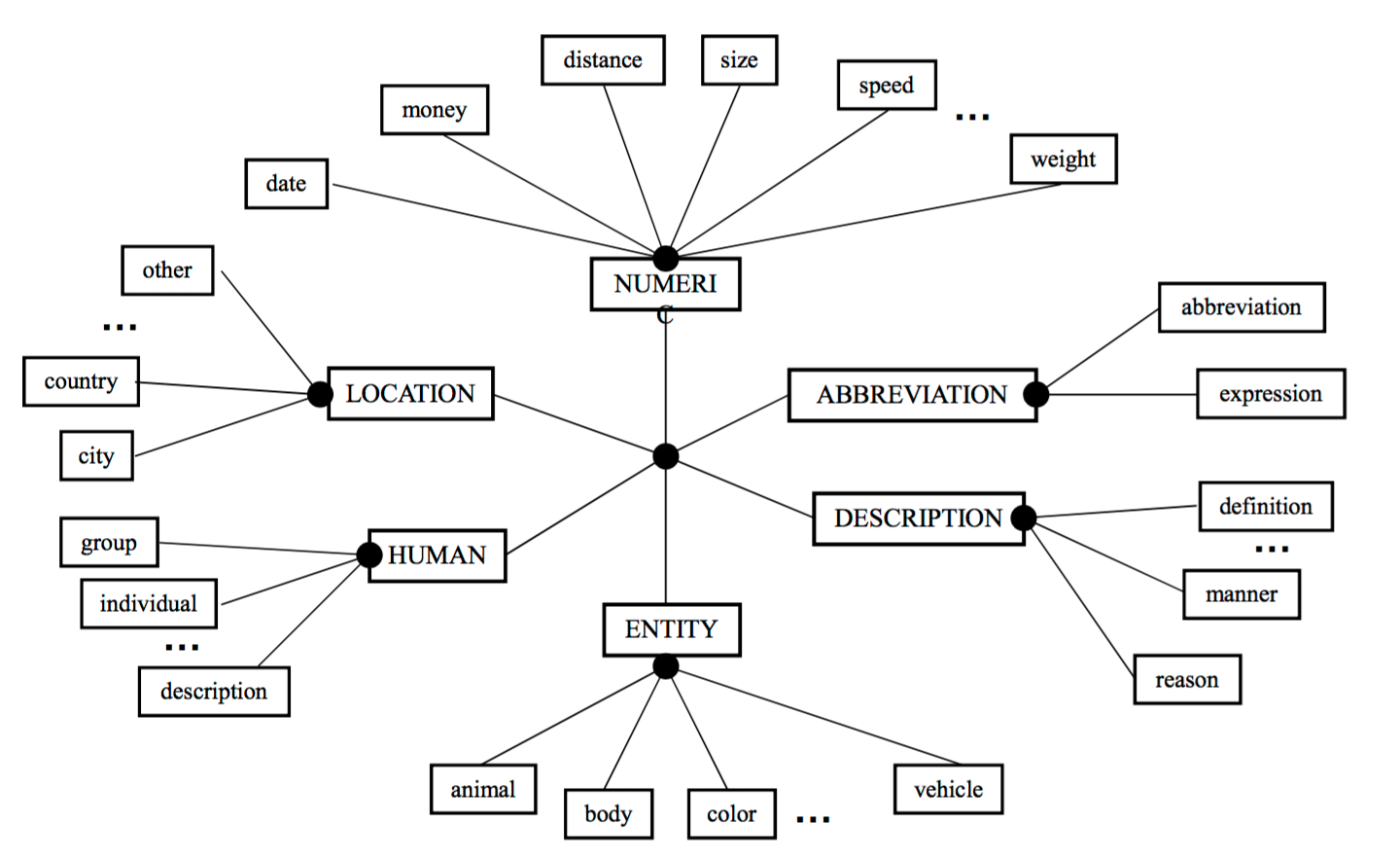
前人已经提供了一些 answer type 的层次型分类结构,如 Answer Type Taxonomy(from Li & Roth)
- Two‐layered taxonomy
- 6 coarse classes
ABBEVIATION, ENTITY, DESCRIPTION, HUMAN, LOCATION, NUMERIC_VALUE - 50 fine classes
HUMAN: group, individual, title, description
ENTITY: animal, body, color, currency…
LOCATION: city, country, mountain…

Features
Features:
Classification
一些分类方法:
- Hand-written rules
- Machine Learning
- Hybrid
- Regular expression‐based rules can get some cases:
Who {is|was|are|were} PERSON
PERSON (YEAR – YEAR) - Other rules use the question headword
= headword of first noun phrase after wh‐word:
Which city in China has the largest number of foreign financial companies?
What is the state flower of California?
当然也可以把上述某些分类方法当作特征一起进行训练。就分类效果而言,PERSON, LOCATION, TIME 这类的问题类型有更高的准确率,REASON,DESCRIPTION 这类的问题更难识别。
Query Formulation
根据 question 产生一个 keyword list,作为 IR 系统的输入 query。可能的流程是去除 stopwords,丢掉 question word(where, when, etc.),找 noun phrases,根据 tfidf 判断 keywords 的去留等等。
如果 keywords 太少,还可以通过 query expansion 来增加 query terms。
Keyword selection algorithm:
Results: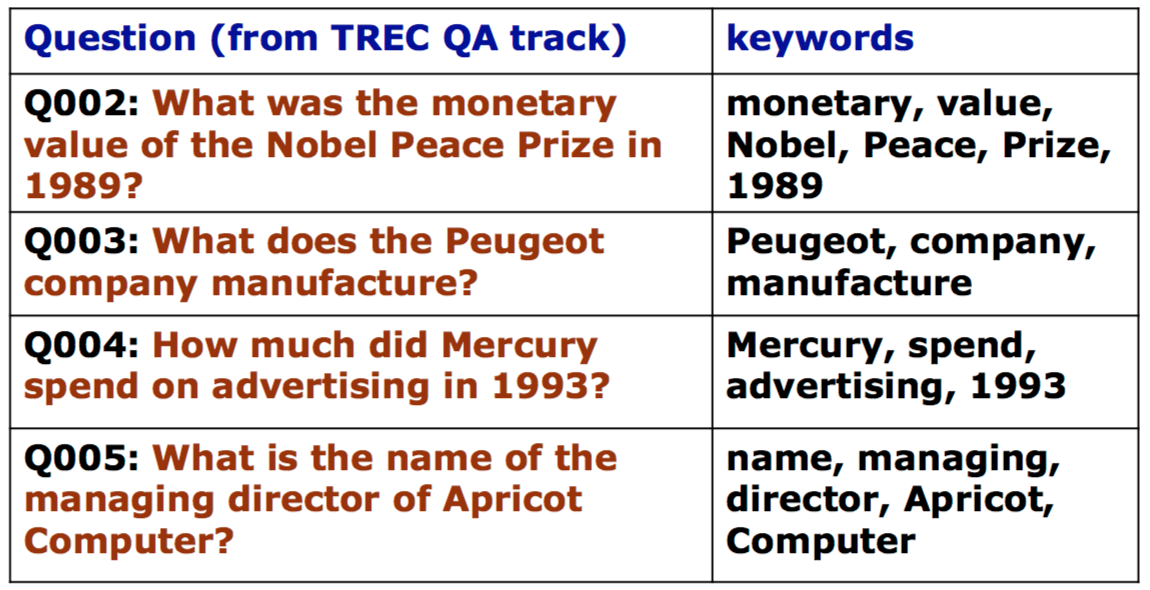
21 - 2 - Answer Types and Query Formulation-NLP-Dan Jurafsky & Chris Manning
Passage Retrieval
有了 query,我们进行检索,会得到 top N 的文档,然而文档并不是得到 answer 的最好的单位,下一步我们需要从文档抽取 potential answer passages,来方便后面的 answer processing。passage 可以是 sections, paragraphs, sentence,具体情况具体分析。
两个步骤:
- 过滤掉那些不可能包含 answer 信息的 passage
可以运行 named entity 或者 answer type 的分类器 - 对剩下的 passage 进行排序
监督机器学习方法
特征:• The number of named entities of the right type in the passage • The number of question keywords in the passage • The longest exact sequence of question keywords that occurs in the passage • The rank of the document from which the passage was extracted • The proximity of the keywords from the original query to each other For each passage identify the shortest span that covers the keywords contained in that passage. Prefer smaller spans that include more keywords (Pasca 2003, Monz 2004). • The N-gram overlap between the passage and the question Count the N-grams in the question and the N-grams in the answer passages. Prefer the passages with higher N-gram overlap with the question (Brill et al., 2002).
对于基于 web 的 QA 系统,我们可以依靠网页搜索来做 passage extraction,简单来说,可以把网页搜索产生的 snippets 作为 passages。
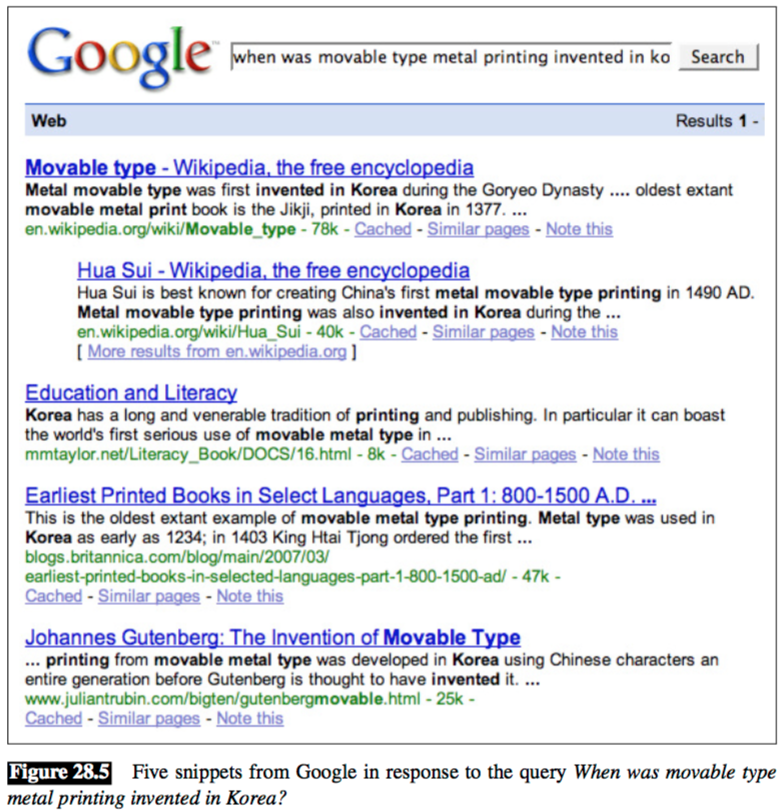
Answer Processing
现在,我们已经有了 question type,也给文本打了 Named Entities 的标签,就可以进一步缩小 candidate answer 的范围。
Answer Identification
Answer Identification 模块复杂找到问题的最佳 answer,对于具有 named entity 的问题,这个模块必须确定有正确 answer 的句子,对于没有 named entity 类型的问题,这个模块基本上得从头开始。
经常使用的方法是 word overlap
- Basic Word Overlap: 对每个候选答案计算分数,依据是答案中/附近的 question words 的数量
- Stop Words: 有时 closed class words(通常称为IR中的停止词)不包括在 word overlap 中。
- Stemming: 有时要用到 morphological analysis,仅仅比较词根(e.g. “walk” and “walked” would match).
- Weights: 一些 word 可能比其他 word 的权重更重(例如,动词可能被赋予比名词更多的权重)
Answer Extraction
Pattern‐extraction methods
在 passage 上运行 answer‐type tagger,返回包含了正确的 answer-type 的文本。
E.g.
有时候光用 pattern-extraction 方法是不够的,一方面我们不能创造规则,另一方面 passage 里也可能有多个 potential answer。另外,对于没有特定定命名实体类型的答案,我们可以使用正则表达式(人工编写或自动学习)。

N-gram tiling methods
N-gram tiling 又被称为 redundancy-based approach(Brill et al. 2002, Lin 2007),基于网页搜索产生的 snippet,进行 ngram 的挖掘,具体步骤如下:
- N-gram mining
提取每个片段中出现的 unigram, bigram, and trigram,并赋予权重 - N-gram filtering
根据 ngram 和预测的 answer type 间的匹配程度给 ngram 计算分数
可以通过为每个 answer type 人工编写的过滤规则来计算具体分数 - N-gram tiling
将重叠的 ngram 连接称更长的答案
standard greedy method:1. start with the highest-scoring candidate and try to tile each other candidate with this candidate 2. add the best-scoring concatenation to the set of candidates 3. remove the lower-scoring candidate 4. continue until a single answer is built
Rank Candidate Answers

可能用到的 feature
Knowledge-based Approaches(Siri)
对 query 建立语义模型,然后做一个 mapping 来找 answer。
semantic parsers: map from a text string to any logical form

- Build a semantic representation of the query
Times, dates, locations, entities, numeric quantities - Map from this semantics to query structured data or resources
Geospatial databases
Ontologies (Wikipedia infoboxes, dbPedia, WordNet, Yago)
Restaurant review sources and reservation services
Scientific databases
流行的本体库(ontologies)有 Freebase (Bollacker et al., 2008) 和 DBpedia (Bizer et al., 2009),它们从 Wikipedia 的 infoboxes 提取了大量的三元组,可以用来回答问题。如下面这个三元组就可以回答 factoid questions,像是 ‘When was Ada Lovelace born?’ 或者 ‘Who was born in 1815?’的问题。
Mapping
Rule-based Methods
对于一些非常常见的问题,我们可以用人工编写规则来从 question 里抽取关系,比如说 birth-year 的关系,我们可以用 question word When,动词 born,来抽取 named entity。
Supervised Methods
一般来说,系统会有一个初始的 lexicon(每个命名实体对应着一些实例),也会有一些默认的匹配规则,这些规则能够把 question parse tree 的某些部分映射为特定关系。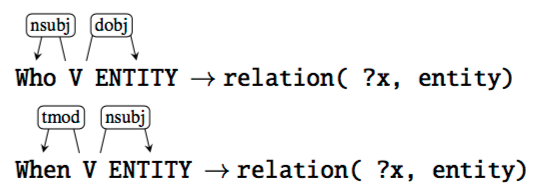
下面是一个二元组例子,用于训练分类器
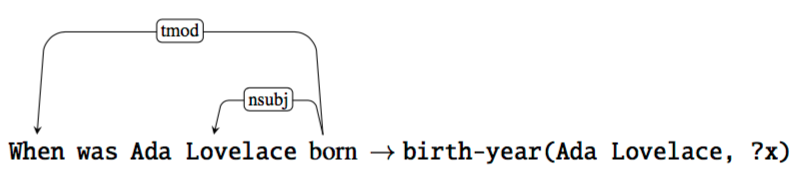
有很多这样的 pair,更多的规则将被引入,然后我们就可以预测 unseen data。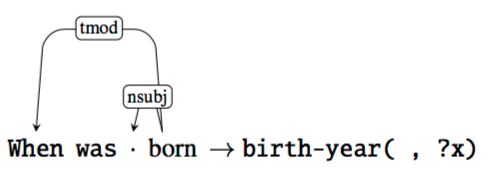
Semi-Supervised Methods
有监督的学习当然很棒,可是我们很难得到庞大的训练数据,所以一个办法就是利用textual redundancy。最常见的 redundancy 的例子当然就是 web 了,网络中存在着大量的能够表达关系的 textual variants,所以很多方法都利用了网络文本,如半监督学习算法 distant supervision,或者是无监督学习算法 open information extraction。把网络数据与规范的知识来源(canonical knowledge source)如 wikipedia 对齐,我们能创建/学习新的映射规则。
另一个 redundancy 的来源是 paraphrase databases,如 wikianswers.com
这些 question paraphrases 的 pair 可以通过 MT alignment 方法建立 MT-style phrase table 来将原始问题翻译成同义的问题,这种方法在现代的 QA 系统中经常用到。
Hybrid/DeepQA System(IBM Watson)
- 构建问题的浅层语义表达(shallow semantic representation)
- 用信息检索方法来产生候选答案
利用本体和半结构化数据 - 用更多的 knowledge source 来为候选答案计算分数
Geospatial databases
Temporal reasoning
Taxonomical classification
一些基本事实:
“The operative goal for primary search eventually stabilized at about 85 percent binary recall for the top 250 candidates; that is, the system generates the correct answer as a candidate answer for 85 percent of the questions somewhere within the top 250 ranked candidates.”
“If the correct answer(s) are not generated at this stage as a candidate, the system has no hope of answering the question. This step therefore significantly favors recall over precision, with the expectation that the rest of the processing pipeline will tease out the correct answer, even if the set of candidates is quite large.”
IBM 的 Watson 系统架构: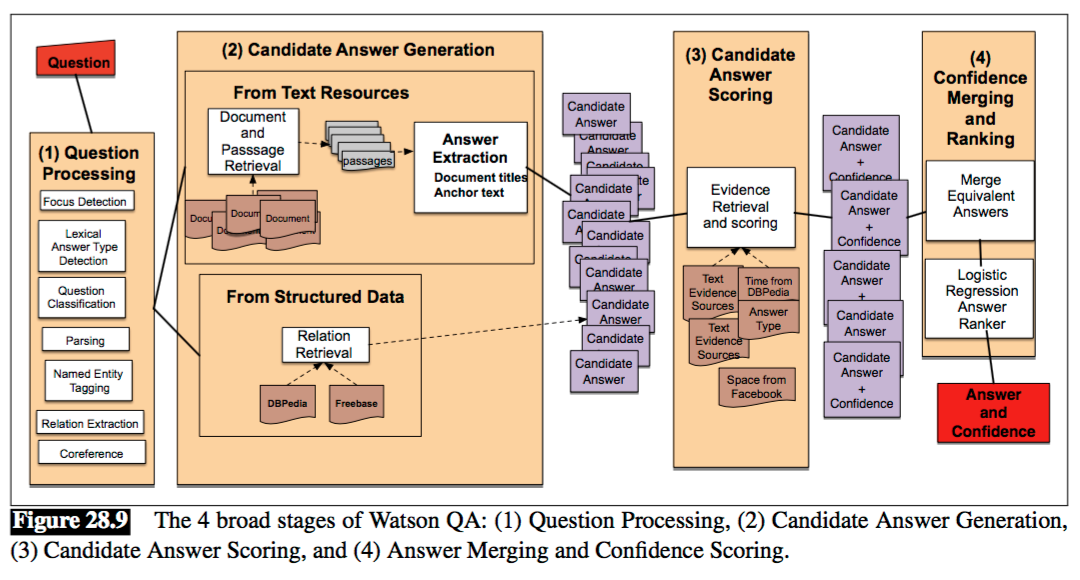
后面补充。
Evaluation
如果只返回一个 answer,就用 Accuracy,如果有多个,就用 MRR,MRR 对所有的 RR 值求平均,RR(Reciprocal rank) 指的是 1/rank of first right answer。
参考链接:
Chapter 28: Question Answering
Chapter23.2: Question Answering

