主要介绍推荐系统用户行为数据、实验设计,是接下来算法实验的基础。
用户行为
用户行为数据
用户行为分为 显性 和 隐性 两种。
- 显性反馈行为(explicit feedback)
用户评分、喜欢/不喜欢 - 隐性反馈行为(implicit feedback)
页面浏览行为、消费行为
两者比较
如何表示用户:
- user id
产生行为的用户 - item id
产生行为的对象 - behavior type
行为的种类(如购买还是浏览) - context
产生行为的上下文,包括时间和地点 - behavior weight
行为的权重(用户评分、观看时长等) - behavior content
行为的内容(评论文本、标签等)
数据集的一般分类:
- 无上下文信息的隐性反馈数据集
包含 user id, item id
如 Book-Crossing - 无上下文信息的显性反馈数据集
包含 user id, item id, 物品评分 - 有上下文信息的隐性反馈数据集
包含 user id, item id, 用户对物品产生行为的 timestamp
如 Lastfm - 有上下文信息的显性反馈数据集
包含 user id, item id, 物品评分, 用户对物品产生行为的 timestamp
如 Netflix Prize
用户行为分析
物品流行度 和 用户活跃度 都近似于 长尾分布。下图表示用户活跃度和物品流行度的关系(MovieLens 数据集)。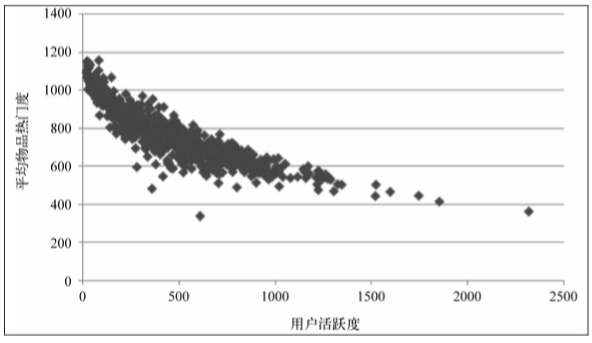
一般认为,新用户倾向于浏览热门物品,因为对网站不熟悉,只能点击首页的热门物品,而老用户会逐渐开始浏览冷门物品。
仅仅基于用户行为数据设计的推荐算法一般称为协同过滤算法,有很多种方法,这里介绍 基于邻域的方法(neighborhood-based), 隐语义模型(latent factor model), 基于图的随机游走算法(random walk on graph),这其中,最有名、在业界得到最广泛应用的算法是基于邻域的方法。接下来的博客会一一讨论这些算法。
实验设计
数据集
采用 GroupLens 提供的 MovieLens 数据集,选中等大小的数据集,包含 6000 多用户对 4000 多部电影的 100 万条评分。
实验目的
研究隐反馈数据集中的 Top N 推荐问题,因此忽略数据集中的评分记录。预测的是用户会不会对某部电影评分,而不是预测用户在准备对某部电影评分对前提下会给电影评多少分。
注意这里隐反馈数据集只有正样本(用户喜欢什么物品),而没有负样本(用户对什么物品不感兴趣)。
实验过程
离线实验。
- 将用户行为数据集均匀的随机分成 M 份(这里取 8)
挑一份作为测试集,剩下 M-1 份作为训练集 - 在训练集上建立用户兴趣模型,在测试集上评测,统计评测指标
- M 次实验,每次使用不同的测试集
M 次试验的评测指标取平均值
防止过拟合
如果数据集够大,模型够简单,为了快速通过离线实验初步选择算法,也可以只进行一次实验
|
|
评测指标
- 准确率
- 召回率
- 覆盖率
- 新颖度
|
|
该实验设计用于接下来 基于邻域的方法(neighborhood-based), 隐语义模型(latent factor model), 基于图的随机游走算法(random walk on graph) 的博客中。

