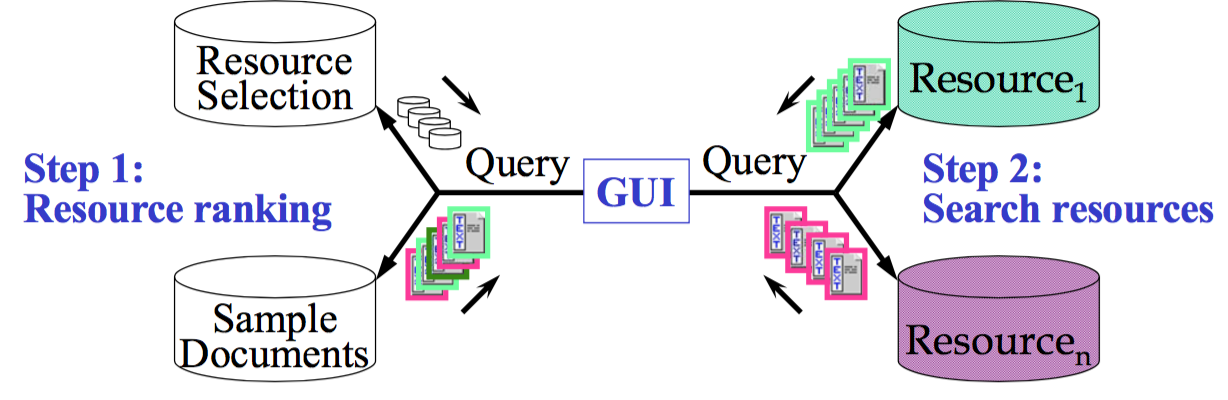
CMU 11642 的课程笔记。垂直数据库能获得更准确的搜索结果。那么对一个 query,我们可以放到合适的多个垂直数据库里检索,然后合并结果呈现给用户。
简单解释就是结果来自多个数据库。用图片表示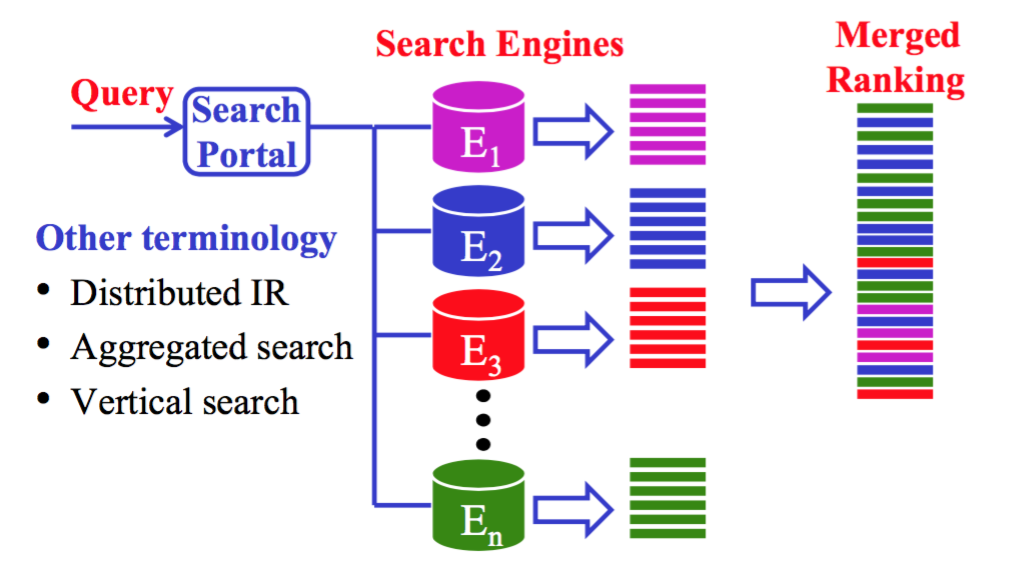
当然,大多数数据库与我们的需求并不相关,所以可以略过。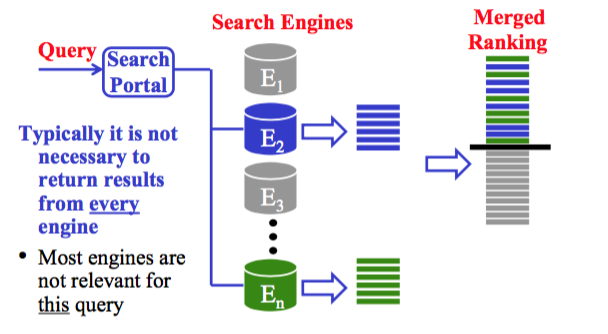
Search portals 可以有不同的策略来处理不同类型的请求
- 搜索非结构化数据
- 将初始查询映射为对应的结构化查询
- 将查询定向到特定的搜索引擎
» 汽车,音乐,图片,视频…
- 搜索结构化数据(数据库) - 例如,邮政编码,股票代码…
- 调用服务或进程
- 如,计算器,股票价格,航班跟踪…
- 调用服务或进程
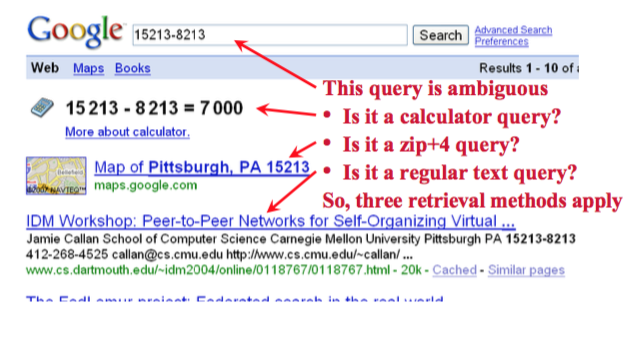
Constrains
不合作环境
- 没有特别的 federated search 的支持
- 资源不受信任
合作环境
- 资源支持公共协议/ API
- 资源是受信任的,能够提供准确的信息
Components
- Resource representation(资源表达)。即获取每个数据库的信息
- Resource selection(资源选择)。即对 resource/databases 进行排序,对每个查询选择少量资源进行检索。
- Result-merging(结果合并)。即对来自不同搜索引擎/数据库对结果进行 merge,产生最终展现给用户的 ranking list。
其中 1 是在线下完成的(offline),2、3 是在查询时完成的。
Resource representation
如何表达资源的内容?
- Bag of words: terms and frequencies
- Sample queries: Queries that this resource is good for
- Sample documents: Typical documents from this resource
一个例子解释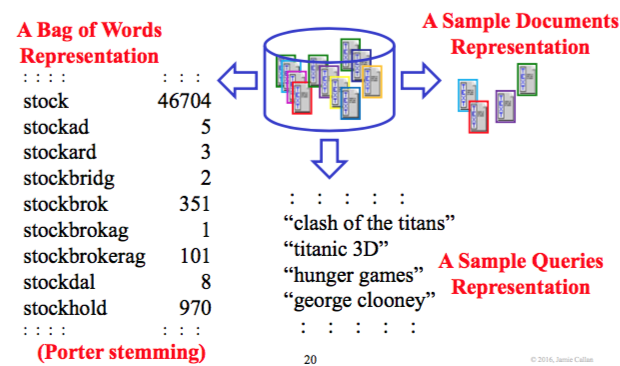
资源的内容信息如何获取
- 通过 protocol 向资源发出请求
- 对 query log 请求相关性评价 (relevance assessments)
- Query-based sampling: 提交查询,查看返回的内容
下面主要介绍第三种 query-based sampling
Query-based sampling
过程
- 选择一个初始查询
- 重复 N 次(例如,N = 100)
- 向搜索引擎提交查询
- 下载一些结果(例如,2-4 条)
- 得到并更新 representation (words and frequencies)
- 从新的 representation 中随机选择 query term(s)形成新的查询
为什么可行?
因为词汇分布服从 Heaps’ Law
如果第一条查询非常糟糕怎么办?
如在一个医学领域的语料库里找 car,可能并没有结果(如果是 boolean ranking 的话),那么就重新选择一个查询?
抽样的大小有什么影响
一条 query 取多少文档呢?实验决定吧,2-4 篇应该就够了
在合作环境下随机采样
只比 query-based sampling 好一点点
Resource selection
两大类方法,无监督学习通常是通过对 P(ri|q) 排序来解决,监督算法通常通过分类解决。
Unsupervised Resource Selection
Task: 给定查询 q,决定要搜索的资源(resources)
无监督方法将这个问题看作 resource ranking 的问题。
- 估计 p(ri|q)
- 选择前 k 个资源
– 通常 k 是给出的
– 动态设置 k 是一个开放的研究问题
两种具体方法,content-based methods 和 query-based methods
- Content-based methods(基于内容的方法)
– 对各个资源下 query 和 content 的相似度 $S(q,c)$ 来对资源进行排序
– 有不同的方法来实现,区分点在于:
» Representation type: bag of words vs. sampled documents
» Ranking algorithm: e.g., CORI - Query-based methods(基于查询的方法)
– 对 query,搜索各个资源下的 query log,找出 match 的 query,然后求当前 query 和历史 query 的相似度 $S(q,q_{past})$,对资源进行排序
– 之前用的并不多,因为缺少好的 query log
Content-based methods
Bag-of-words method
基本思想是 将每个资源视为一个(非常大的)词袋(bag of words),排序算法可以用 KL divergence 或者 query likelihood 等方法。
eg. CORI
然而,Bag of words methods (e.g., CORI)是根据 resources 和 query 的相似度进行的排序,这并不是我们的初衷。这种方法 偏好具有较高 p(qi|Rj) 的资源,通常意义上也就是 homogeneous (通常很小)的资源。这并不是我们需要的,我们想要的是,选择能够返回更多相关文档的资源,sampled document method 更能达到这个目标。
Bag of words (“large documents”) 方法的特点
- 大文档更好的代表了 resource representation
- 偏好具有较大比例相关内容的资源
– i.e., small or homogeneous resources - 非常有效,很有竞争力
Sample documents method
基本思想: 对每个资源采样然后合并得到一个 centralized index,记录每个文档来自哪个 resource。
eg. ReDDE
给定一个查询
- 搜索 centralized sample index 得到相关文档
- 取前 T 的文档
- 检查哪些资源提供了这些相关文档
- 估计每个资源中相关文档的数量
• 计算资源 i 中高于阈值 T 的文档数量 n
• n * resource_size / sample_size
ReDDE 可以看作是 sample-based voting method,每个 top-ranked document 可以看作是对它属于的那个资源的一个投票。
特点:
- 高召回率: 选择包含更多相关文档的资源
- 高准确率: 选择能够返回更多的出现在合并结果集 top T 的文档的资源
- 有很多算法的变种
– 来自更可靠/权威的资源的 sample 获得更多的投票
– 更相关的 sample 获得更多的投票
CORI vs ReDDE
- ReDDE 相对而言更加准确
– 通常效果更好,几乎不会有更糟的情况 - 当各个 collection size 的分布是 skewed 时,ReDDE 的性能优于 CORI
– CORI 偏向小集合。他们更可能是同质的,它错过了大型,异质的 collections
– ReDDE 对大型 collection 的偏见没那么强 - CORI 比 ReDDE 更有效
– 一个资源一个文档 vs. 一个资源多个文档
Supervised Resource Selection
当我们有可用的训练数据时,就可以进行有监督的资源选择
- 利用广泛的特征
- 将任务框架化为分类问题
- 让机器学习算法学习如何给不同的特征分配权重
Main issues
- 特征工程
- 获取训练数据
- 确定要选择的资源数
Framework
Task: 给定一个查询,选择一个或更多的 verticals
将问题定义为一个 “one-vs-all” 的分类任务
- 对每个 vertical 都训练一个分类器
- 对 “no vertical” (web only) 也训练一个分类器
- E.g., Arguello, et al (2009) 用了逻辑回归模型
典型的选择策略
- 选择一个具有最高置信度(confidence score)的分类器
- 选择 n 个最好的分类器
- 选择所有置信度分数高于 threshold 的分类器
Features
Query features
- Boolean: keywords and regular expressions
– E.g., “weather”, “news”, “videos”, … - Geographic: Probabilities associated with geographic entities
– E.g., “Pittsburgh pizza” - Category: query’s affinity to a set of topic categories
– E.g., “Cancun vacations”
Corpus Features
ReDDE 是非常流行的资源排序算法
Clarity (Cronen-Townsend, et al., 2002)
Clarity 用来预测给定语料库上的查询的有效性,本质上是 top-ranked 文档和完整集合之间的 KL divergence,如果排名靠前的文档看起来像是 collection 的 random sample,搜索结果将会很差
Query Log Features
- 人工评估/点击率
qlog feature
- 用查询日志中的 query 来构建语言模型 v
- 用 query likelihood 来建模 $P(q|v)=\prod_t^q P(t|v)$
- p(t | v) is a smoothed MLE
Soft.ReDDE feature:
- 用查询日志中的 query 来构建语言模型 v
- 用 query 对外部的 collection 检索
– E.g., wikipedia - 选择前 n 个文档
- 文档 di 的投票是 KLD (di || v)
– 与查询日志相似的文档具有更高的投票
Result merging
主要问题:
idf
同一个 term,在不同数据库的 idf 不同怎么办?
scores
不同数据库的 doc score 不是可比的怎么办?
=> Map resource-specific scores to resource-neutral scores
Result merging
- 用所有的 sampled documents 创建一个 index (offline)
- 从选定的资源里检索文档
– 因为资源并不提供文档分数,所以对每个文档计算 sim (q, d)
– 利用 index 的 corpus statistics 来计算每个文档的 authority score - score(d) = f ( sim (q, d), authority (d) )
Semi-Supervised Learning
由资源 i 返回的一些文档可能同时出现在 sample index 里
对这些文档我们有两个分数
- Sample index (resource neutral) score
- Resource i (resource-specific) score
这就是我们用来学习 f (resource-specific) = resource-neutral 的训练数据
对这个所需的 “normalization” 用线性函数进行建模,因为线性模型可以利用少量的数据进行训练,而且 Ad-hoc CORI 的合并就是线性的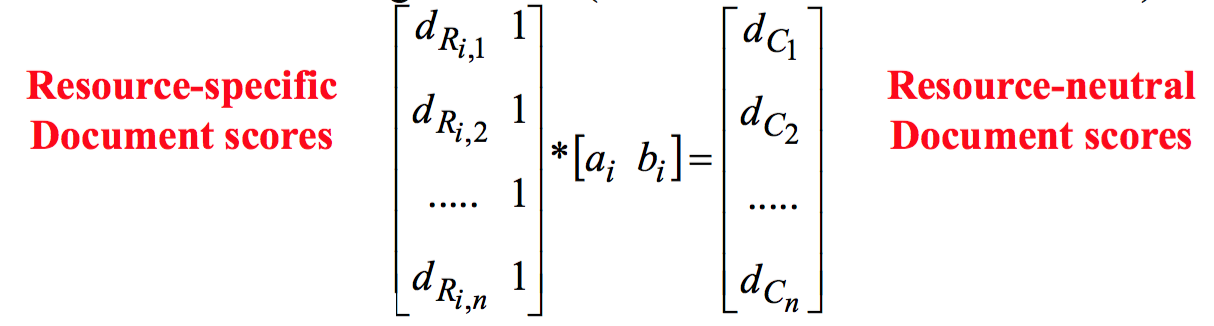
使用线性回归(linear regression)推导出权重
- f(resource-specific score)= a×dRi,j + b = resource-neutral score
- 每个(query, resource) pair 对应不同的函数
它有效么?
目前为止是最好的选择,因为 mapping 是 query-specific 和 resource-specific 的。
有没有足够的训练数据?
通常有,因为 resource selection 和 sample index 可以用相同的文档。如果没有,下载 1-3 篇文档来产生训练数据。
Large-Scale Search Architecture
之前讲过 large-scale search architecture 的相关内容。我们可以把数据集分为两层 高价值 和 低价值,然后将每一层进行分区(shards),再将分区分配给计算机。
事实上我们并不需要对每个查询都检索每一个分区,这样做成本很高,为什么不直接搜索最好/最合适的分区呢?
通常带来的结果是:
- 高准确率 (尤其是 top ranks)
- 低召回率 (可能会错过许多有用的文档)
– 只搜索了少量资源,这也是广泛应用的障碍
所以分为两步:
- 资源定义(Resource definition)
- 对文档分区
- 资源选择(Resource selection)
- 对特定 query 选择要搜索的分区
下面进行详细的介绍。
Resource definition
Goal: 搜索更少的分区得到更高的 recall
Requirement:
对于可能提交的任何 query,大多数的相关文档必须出现在同一个分区中
How:
把 closely-associated documents 也就是相似(相同主题)的文档归到同一个分区。
Hypothesis: Closely-associated ≈ topically-related & Each shard covers one topic/subject
对给定的语料库,应该使用哪些 topics/subjects?
- 人工开发类别? – LCSH, DMOZ, Reuters, …
- 自动学习 corpus-specific topics? – Clustering, LDA, PLSA, …
我们想要一个可以应用于任何语料库的解决方案,因此,需要能自动学习基于语料库的特定的主题。许多算法能产生语料库特定的“主题”:
- 聚类: E.g., k-means clustering
- 主题模型: E.g., Latent Dirichlet Allocation (LDA)
当然我们也要保证解决方案必须对 large collections 是有效的:
- 从 collection 的一个随机样本里创建主题
- 将其余文档分配给最相似的主题
Resource selection
Goal: 给定查询,选择最好的分区
两类重要的资源选择算法:
- Model-based: CORI, CRCS, Taily, …
- Sample-based: ReDDE, SUSHI, Rank-S, …
有很多好的算法
- Sample-based 的算法被认为是最有效的
- 在初始工作中常常使用 ReDDE 变种
- Taily 和 Rank-S 也经常被研究/考虑
对每个分区采样:
将样本存储到 sample index 里 => offline
给定查询
- 搜索 sample index,得到 top documents
- Top documents 对它们所在的分区投票
- 将 query 发送到得到最多投票的分区
=> online
Cost
$C_{Total}$:
- 处理 inverted list 的数量
- 用于资源选择
- 用于分区选择
- I/O 和计算成本
Selective search 分为两步:
- 选择要搜索的分区(resource selection)
- 搜索所选的分区
ReDDE 具有更高的计算成本
Key techniques
- Resource definition for selective search
– How to partition a large corpus effectively - Resource representation
– How to represent the contents of each resource
– Vocabulary-based, sample-documents-based, feature-based - Resource selection
– How to select the right resources for a particular query

