对 Luo Si 和 Jamie Callan 的论文 Relevant Document Distribution Estimation Method for Resource Selection 做的一些笔记。之后会整理 Federated search 这一章的笔记。
Distributed information retrieval
Distributed information retrieval 也叫做 Federated search,这种搜索引擎包含了多种搜索引擎或者数据库。论文表示 Distributed information retrieval 主要存在三个子问题。
- Resource representation。即获取每个数据库的信息
- Resource ranking。即对 resource databases 进行排序,对每个 query 选择 a small number of resources。
- Result-merging。即对来自不同搜索引擎/数据库对结果进行 merge,产生最终展现给用户的 ranking list。
Database size 估计
Database size 是资源描述的重要组成部分。先前的研究表明,评估相似度时对数据库大小进行归一化对结果很重要。resource selection error 也通常是因为 normalize 不同大小的数据库中的 term frequency 时的不合理。
database size 有很多种表现形式:
- size of vocabulary
- number of word occurrences
- number of documents
- …
论文中的数据库大小用文档数量来表示。
目前有的估计 database size 的方法有 Capture-Recapture Method[11], gGIOSS[6], Iperirotis’s Hierarchical Database Sampling and Selection algorithm[8], D’Souza and Thom’s n-term indexing method[5], CORI resource selection algorithm[1,2] 等等。论文介绍了 Capture-Recapture Method,在此基础上提出了 Sample-Resample Method。
Capture-Recapture Method
主要思想是通过抽取两个 sample,基于样本独立的假设以及此基础上的概率知识 P(A|B)=P(A) 来推断 database size。
假设:一个 collection 里有两个(或更多)独立的 sample。
- N: population size
- A: the event that an item is included in the first sample which is of size n1
- B: the event that an item is included in the second sample which is of size n2
- m2: the number of items that appeared in both samples
于是有:
$$P(A)={n_1 \over N} \qquad (1)$$
$$P(B)={n_2 \over N} \qquad (2)$$
$$P(A|B)={m_2 \over n_2} \qquad (3)$$
因为这两个 sample 是独立的,所以有
$$P(A|B)=P(A) \qquad (4)$$
所以
$$\hat N={n_1n_2 \over m_2} \qquad (5)$$
通过随机发送 query 到数据库/搜索引擎然后从返回的 document ids 进行抽样,然后估计数据库大小。
论文指出,这种算法可能不现实,这主要是基于成本的考虑。比如说,当估计一个有 300,000 篇文档的数据库,采样过程使用 2000 条 query,每条 query 返回 1000 个 document ids,那么一共就有 2,000,000 (non-unique) documents 需要评估。这个 cost 无疑是巨大的。而我们希望用更低的成本来估计数据库大小。由此论文提出了 Sample-Resample Method。
Sample-Resample Method
Capture-Recapture 算法需要和数据库进行多次交互,Sample-Resample 算法减少了交互的次数。
相关前提假设
假定 resource description 由 query-based sampling [13] 产生,每个 resource description list 列出了
- 抽样的文档数 (number of documents sampled)
- 抽样文档中包含的 term (the terms contained in sampled documents)
- 抽样文档中包含各个 term 的文档数 (the number of sampled documents containing each term)
并且,我们假定各个 search engine/database 列出了 match 当前 query 的所有文档数。
过程
从当前数据库的 resource description 里随机抽取一个 term,然后把这个 term 当作 query (single-term query) 在当前 database 进行检索,这个过程又叫做 resampling。数据库会返回匹配这个 query 的文档数和一些排在前面的文档 (top-raked documents)。一些 notation 如下:
- Cj: database
- Cj_sample: documents sampled from the database when the resource description was created
- N_cj: size of Cj
- N_cj_sample: size of Cj sample
- qi: query term selected from the resouce description for Cj
- df_qicj: number of documents in Cj that contain qi
- df_qicj_samp: number of documents in Cj_sample that contain qi
- A: the event that a document sampled from the database contains term qi
- B: the event taht a document from the database contains qi
然后,我们就能得到下面的概率。
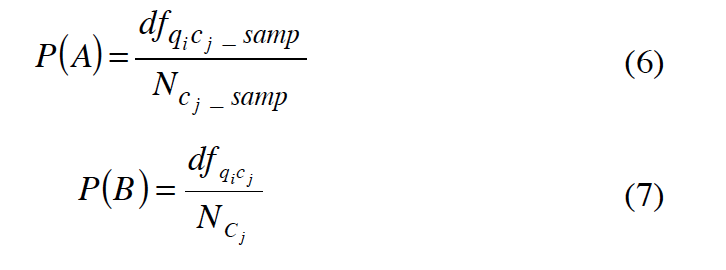
假设: 从数据库里抽取的样本具有代表性,能够很好的描述整个数据库
在这个假设下,我们就可以推断出数据库大小。
=> P(A)~P(B)
=>
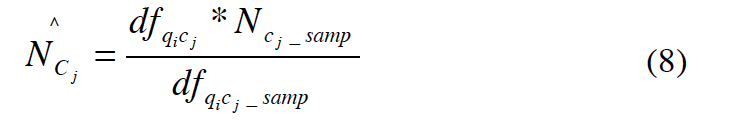
Database Size Evaluation Metrics
很简单的公式。
$$AER={|N-N^\ast|\over N^\ast} \qquad (9)$$
- AER: absolute error ratio
- $N^{\ast}$: actual databse size
- N: estimate
Cost
重要的成本就是和搜索引擎进行的交互次数。
Liu 和 Yu 在 Capture-Recapture 算法[11]中假定数据库返回的排序列表有 1,000 个 document id。通常来说,像 AltaVista 和 Google 最初都只会返回 top 10 或 20 的结果。如果我们假定搜索引擎每页能返回 10-20 个结果,假定为 20,那么为了得到 1,000 个 docid,需要和数据库进行 50 次交互。当然,如果我们可以提前设定我们从 sample 里取多少条(top k documents),并且搜索引擎可以让我们限定返回的结果数,那么就只需要和搜索引擎进行 1 次的交互啦,然而这个并不现实,一般搜索引擎不会提供这样的接口。
而 Sample-Resample 算法主要的成本来自于用于 resample 的 queries,每一个 resample query 都需要一次数据库交互,论文里对每个数据库只用了 5 个 resample queries,也就是 5 次交互。与 Capture-Recapture 算法相比 cost 大大降低。
ReDDE 算法
资源选择的目的是找出一个包含了许多相关文档的一小撮数据库。如果我们能知道这些相关文档在不同数据库的分布,那么就可以根据每个数据库有的相关文档的数量,给数据库一个 ranking,这个 ranking 叫做 relevance based ranking(RBR)。
数据库 Cj 里与 query q 相关的文档数:
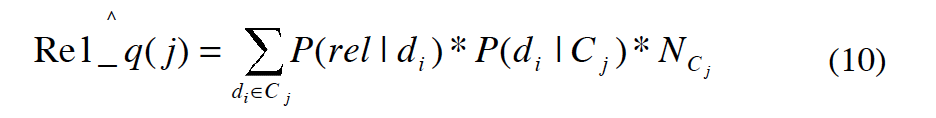
Ncj 是数据库 Cj 里的文档总数,可以用 Sample-Resample 的方法估计出来,是估计值我们可以用 $\hat N_{c_j}$ 来表示。 对于 P(di|Cj),既然我们有一个 complete resource description,那么这个概率就是 1/Ncj。所以相关文档数就成了
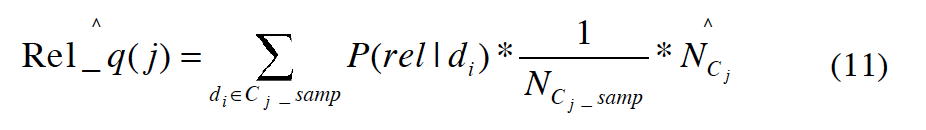
现在就剩下了 P(rel|di),给定一个文档求相关的概率。我们定义一个 centralized complete database,代表在分布式的 IR 系统里所有 available individual databases 的全集。P(rel|di)是给定一个文档,centralized complete database 返回的这篇文档与 query 相关的概率。这个概率分布可以用 step function 进行建模,也就是说在 ranked list 中排在 top k 的文档的 relevance probability 都是一个常量,其它所有文档的 relevance probability 都是 0。

- Cq: query-independent constant
- rank_central(di): the rank of document di in the centralized complete database
- ratio: threshold, indicating how the algorithm focuses attention on different parts of the centralized complete DB ranking.
在论文中,ratio 用了 0.003,相当于在一个文档总数为 1,000,000 的数据库里取前 3,000 文档。实验表明,ReDDE 算法在 0.002-0.005 间有比较好的效果。
然而,一个 centralized complete database 难以获取,我们只能建立 centralized sample database 来作为 centralized complete database 的 representative subset,这里的文档来自于在 database resource description 建立的基础上进行的 query-based sample。之前的研究表明,centralized sample database 对 result merging 的归一化文档分数非常有效。
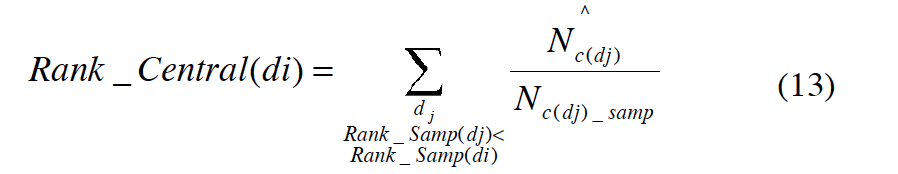
等式 12 和 13 代入 11 就可以计算出 $\hat Rel_q(j)$,到此,我们就可以通过 normalize 等式 11 的值来估计数据库分布,从而为数据库排名。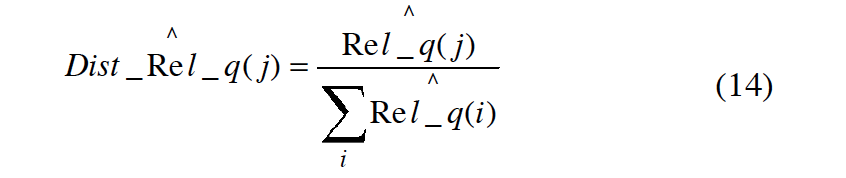
实验
这里略过了实验,有兴趣的同学可以查看原文。主要是验证了 ReDDE 算法的有效性,并且提出了,提高资源选择不一定能提高检索准确率的结论。
如果我们有一个 centralized complete database,一个搜索算法会返回 TOP 100 的文档,然而这个结果集只在所有文档中占一个非常非常小的比例,ReDDE 算法需要评估更大的比例。比如说,如果 ratio 是 0.003,total testbed size 是 1,000,000 文档,尽管目标是检索 100 篇相关文档,然而资源选择算法会得到在 centralized complete database 的 TOP 3,000 篇文档,优化 TOP 100 和优化 TOP 3,000 并不是一回事儿。当然你可以选择降低 ratio,然而这样的话我们就只能在一个 sampled documents 很少的情况下做决策,使用 small ratio 会使一小部分数据库有 nonzero estimates.
随之而来的改进版 ReDDE 算法,考虑两个 ratio,一个 smaller ratio 一个 larger ratio,对于有 large enough estimation value 的数据库我们用 smaller ratio 来排序,而其他的数据库我们用 larger ratio 来排序,于是对每个数据库,我们用等式 14 可以得到两个 estimation values(DistRel_r1j,DistRel_r2j),r1 的经验值是 0.0005,r2 的经验值是 0.003,过程如下:
- Rank all the databases that have DistRel_r1j >= backoff_Thres
- For all the other databases rank them with the values DistRel_r2j.
backoff_Thres 在实验中被设为 0.1。
结论
CORI 算法是非常有效的一种资源排序算法,然而对很多小的数据库和一部分非常大的数据库组合的环境下(比如公司或者政府环境)效果并不好,于是才引入了 ReDDE 算法。
ReDDE 算法的基本思想是通过使用估计的数据库大小和一个 centralized sample database 来估计 available databases 下相关文档的分布。实验表明 ReDDE 算法在 rank 1-10 下至少能和 CORI 算法一样有效,有些情况下甚至更有效,当然在有很多数据库被搜索的情况下 CORI 算法还是有着优势。
另一个结论是提高资源选择不一定能提高检索准确率。实验表明,ReDDE 算法产生的最终的文档排序和 CORI 算法产生的最终的文档排序至少一样准确,甚至更好。
ReDDE 算法的不足是它采用了常量来对文档相关性建模,这些常量本身可能是一个 weakness。训练数据能够自动来决定 testbed-specific parameter settings,来提高准确性和广泛性,这一点还在研究中。
论文也提出了估计数据库大小对算法 Sample-Resample,与 Capture-Recapture 算法相比,Sample-Resample 算法在各种数据库尤其是大型数据库下稳定性更强。
REFERENCES
[1] J. Callan. (2000). Distributed information retrieval. In W.B.Croft, editor, Advances in Information Retrieval. Kluwer Academic Publishers. (pp. 127-150).
[2] J. Callan, W.B. Croft, and J. Broglio. (1995). TREC and TIPSTER experiments with INQUERY. Information Processing and Management, 31(3). (pp. 327-343).
[3] N. Craswell. (2000). Methods for distributed information retrieval. Ph. D. thesis, The Australian Nation University.
[4] A. Le Calv and J. Savoy. (2000). Database merging strategy based on logistic regression. Information Processing and Management, 36(3). (pp. 341-359).
[5] D. D’Souza, J. Thom, and J. Zobel. (2000). A comparison of techniques for selecting text collections. In Proceedings of the Eleventh Australasian Database Conference (ADC).
[6] L. Gravano, C. Chang, H. Garcia-Molina, and A. Paepcke.(1997). STARTS: Stanford proposal for internet metasearching. In Proceedings of the 20th ACM-SIGMOD International Conference on Management of Data.
[7] J.C. French, A.L. Powell, J. Callan, C.L. Viles, T. Emmitt, K.J. Prey, and Y. Mou. (1999). Comparing the performance of database selection algorithms. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.
[8] P. Ipeirotis and L. Gravano. (2002). Distributed search over the hidden web: Hierarchical database sampling and selection. In Proceedings of the 28th International Conference on Very Large Databases (VLDB).
[9] The lemur toolkit. http://www.cs.cmu.edu/~lemur
[10] InvisibleWeb.com. http://www.invisibleweb.com/
[11] K.L. Liu, C. Yu, W. Meng, A. Santos and C. Zhang. (2001). Discovering the representative of a search engine. In Proceedings of 10th ACM International Conference on Information and Knowledge Management (CIKM).
[12] A.L. Powell, J.C. French, J. Callan, M. Connell, and C.L. Viles, (2000). The impact of database selection on distributed searching. In Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.
[13] L. Si and J. Callan. (2002). Using sampled data and regression to merge search engine results. In Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.
[14] J. Xu and J. Callan. (1998). Effective retrieval with distributed collections. In Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.
[15] S. Robertson and S. Walker. (1994). Some simple effective approximations to the 2-poisson model for probabilistic weighted retrieval. In Proceedings of the 17th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.

