CMU 11642 的课程笔记。这一章 Authority Metrics(权威指数),用来判断哪些来源的信息更值得信任。介绍 PageRank、Topic-Sensitive PageRank(TSPR)、T-Fresh、Hyperlink-Induced Topic Search(HITS) 四种指数计算方式。
链接分析
链接分析思想最早起源于引文分析领域,通过分析文献之间的引用模式来量化学术论文的影响力。文献引用代表某篇学术论文对所引用论文的权威度的认可。类似的,对于 Web 网页,我们把超链接看成是一个网页对另一个网页的权威度的认可。当然,并不是所有引用都代表权威度认可,因为某个人可以建立多个 web 网页来指向同一个目标网页,人工来提高目标网页入链数。这种链接通常叫垃圾链接或链接作弊(link spam)。尽管如此,引用现象的普遍性和可靠性足以使搜索引擎通过精妙的链接分析方法推导出有用的排序因子。链接分析也被证明是在 web 采集中选择下一个采集网页的非常好的方法之一。给定查询下,链接分析结果已经成为 Web 搜索引擎在计算某个网页的组合得分中的一个因子。PageRank 和 HITS 就是常用的两种链接分析方法。
基本假设
- 指向页面 B 的锚文本是对 B 的一个很好的描述。
- A 到 B 的超链接表示 A 的作者对 B 的认可。
锚文本
什么是锚文本
|
|
这个 HTML 代码片段给出了一个指向 Journal of the ACM 的链接。链接指向 http://www.acm.org/jacm/,锚文本是 Journal of the ACM。
锚文本的作用
Web 上随处可见的现象是,很多网页的内容并不包含对自身的精确描述,尤其是公司网页,因为它们往往是用作商业宣传而不是介绍公司内容。如 IBM 是计算机制造商,但公司主页 (www.ibm.com) 的 HTML 代码的任何地方都不包含词项 computer。这时候,锚文本的作用就体现出来了。锚文本的词项可以作为索引目标网页的词项,也就是说 computer 的 inverted list 包含了 www.ibm.com,这时再用一个特别的指示器表示这些词项在锚文本而不是网页内部,网页评分时也基于 term frequency 计算锚文本的 term weight,在多个锚文本中高频出现的词项(如 Click 和 here)会收到惩罚。
除了锚文本,锚文本周围窗口的文本(extended anchor text),通常也可以当成锚文本来使用。
副作用
网站可以通过构造具有误导性的锚文本来指向自己,以此提高在某些 query term 的排名。
PageRank
PageRank 是 query-independent 的,也就是说与用户输入的查询无关。PageRank 高的网页并不代表一定适合某个特定的 query。如 kanye west wikipedia 网页有很高的 PageRank,但并不适合 “obama family tree” 这个特定的 query。
Random Walk Algorithm
PageRank 可以被看作是一个随机游走的算法。基本思想是模拟一个悠闲的上网者,上网者首先随机选择一个网页打开,然后在这个网页上呆了几分钟后,跳转到该网页所指向的链接,这样无所事事、漫无目的地在网页上跳来跳去,PageRank 就是估计这个悠闲的上网者分布在各个网页上的概率。
- 随机选一个网页 A 。
- 网页 A 有 n 条出链(outlinks),这时候有两种方法进行下一步。
- 随机在出链中选一个到下一个网页。
- 随机从所有 web 网页里选一个其它网页(teleport)。(因为网页 A 可能没有出链)
- 不断重复以上过程。
随机游走中访问越频繁的网页越重要。
计算方法
Voting Algorithm
PageRank 也可以被看作是一个 Voting algorithm。
再具体些
- 每次循环,网页 Pi 可以左 PR(Pi) 次投票。
- 把投票平均分发给每一个它指向的网页。
- 如果两个网页在第 i 次循环中有相同的 PageRank:
PR(p1)=0.4, p1 有 2 个 outlinks, 那么 p1 的每一个 vote 是 0.4/2=0.2
PR(p2)=0.4, p2 有 4 个 outlinks, 那么 p2 的每一个 vote 是 0.4/4=0.1
在每一个循环中, PR 的计算方法都如之前的图示。
d 的选择
假定 A 有两条出链,指向 B 和 C,B 和 C 各自有一条出链,都指向 A。
如果 d=0.5,那么经历 14 次循环 PR 会 converge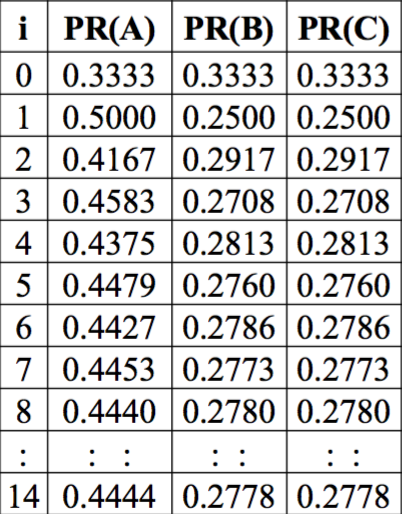
如果 d=0.85,那么经历 58 次循环 PR 会 converge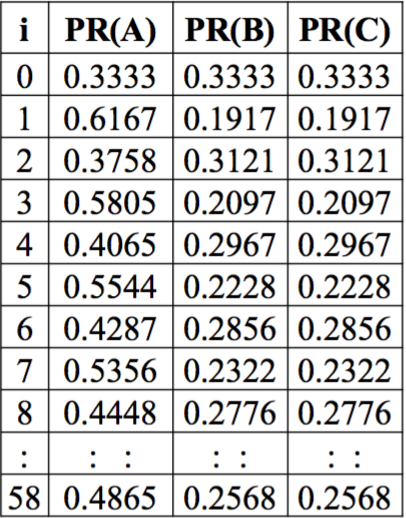
Transformation of PageRank
有些 PageRank varies over a wide range,我们可以把这个 range 进行压缩和转化。如
$$PR_T = log_{10}(PR)+11$$
效果是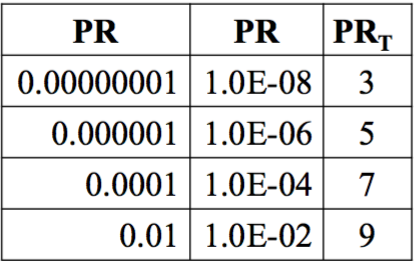
Google 的 PageRank 范围是 1-10,我们通常说的 PageRank 都是经过这种转化的 PageRank。
怎样产生 high PageRank
- 有很多入链
- 有很多来自具有高 PageRank 网页的入链
- 入链有很少的出链
因为在每一次 propagation 时,一个网页的 PR 会被它的出链平分,所以一个有很多出链的入链网页并不是非常有帮助。
PageRank 的其它问题
- 同一个站点的网页链接算不算?
- 新的网页的 PR 怎么算?
- 怎么处理 sinks(没有出链的网页)?
- 怎么处理 link farms 和链接交换?
还有一个问题就是 PR 是 topic-independent 的,一个网页可能有很高的 PR 但是对某个 query 来说却是一个很坏的选择。Topic-Sensitive PageRank(TSPR) 可以解决这个问题。
Topic-Sensitive PageRank(TSPR)
之前考虑的 PageRank 是等概率跳到一个随机网页的情况,关于 topic PageRank,我们考虑的是非等概率跳到一个随机网页的情况,计算的是基于特定兴趣/主题的 PageRank。如一个体育迷希望有关体育主题的网页的排名高于非体育主题的网页,假定这些有关体育的网页在 web 图中彼此相近,那么随机游走过程中,一个喜欢体育网页的人就可能在这类网页上停留大量的时间,因此,体育类网页的稳态分布概率被提升。
主要逻辑是
- 在索引过程中,每一个网页都被自动分配一个 topic (用文本分类的方法)。
- 为每一个网页计算一个 topic-specific 的 PageRank。
- 每一个 query 都被分配一个 topic,根据用户在这个 search session 中浏览的网页来确定 topic。
- 对每一个页面,只考虑 topic-related PageRank,如 $PR_{sports}(d)$
注: DMOZ 是一个著名的开放式分类目录,有很多可以用来做 training data 的网页。可以从 top-level 中定义 topics。
T-Fresh
PageRank rewards older web pages。old web 网页有更多的时间来积累 inlinks,有些 link 可能是来自已经废弃不用的网页,然而用户可能更偏好新的网页。
网页快照提供了 freshness 的线索。
- Page freshness:网页最近什么时候被更新过。Page text(↑),url(↑),anchor text(↑↑),new link(↑↑↑)
- Link freshness:有多少 inlinks 来自 fresh page。
- Decay freshness measures exponentially.
follow a link 的概率取决于网页的新鲜度。
有 fresh inlinks 的 fresh page 有更高的 authority score。
BM2500+T-Fresh vs BM2500+PageRank
Relevance: +8% in P@10,+11-30% in NDCG@k
Freshness: +8% in P@10,+10-12% in NDCG@k

其它相同作用的 model 如 TimedPageRank, T-Rank, BuzzRank, TemporalPageRank。
Hyperlink-Induced Topic Search(HITS)
在泛主题搜索(broad-topic search),也就是 informational needs 时,主要有两种非常有用的网页结果。
- Authority 网页:一些权威性的网页。
- Hub 网页:导航型网页,本身不是权威型网页,而是对某个主题感兴趣的人花时间编辑整理出的权威型网页列表。可以通过这种导航型网页来帮我们找到权威型网页。
一个好的 hub 网页会同时指向多个好的 authority 网页,而一个好的 authority 网页同时会被多个好的 hub 网页所指向。给定某个查询,我们对每个网页给出两个得分,一个是 hub 值,一个是 authority 值,所以对任何一个查询,我们都能得到两个排序结果列表。所以,我们其实可以给出一个 hub 值和 authority 值的循环定义,然后通过迭代计算求解。

并不是对整个 web 计算 Hubs 和 Authority 分数。而是对一个小的 set 来进行计算,set 的创建方法如下:
- 收集 query q 的 top n 网页构成 the root set
- 用 root set 的入链和出链扩充这个 set。
之后在这个网页子集上来计算 hub 和 authority 值。这个 set 的好处是有一个 strong, query-specific focus,而且 set 规模相对较小,大概只有 200 个网页。然而这些 score 必须在 query time 时进行计算。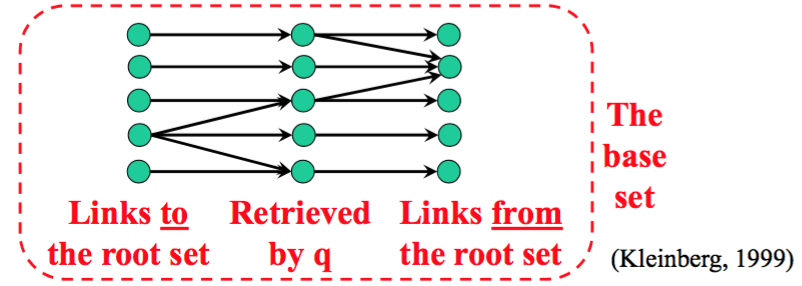
HITS 在大规模的搜索引擎中不会被使用
- 计算 spam 要比计算 PageRank 简单
- 创建一个有 high hub score 的网页很简单
- 运行成本比 PageRank 高。
HITS 通常用于别的目标。如找 communities 或是找一个 community 里的专家,因为它们会有 tightly-bound hubs 和 authorities。

