CMU 11642 的课程笔记。这一章开始的很多内容都是从论文的研究报告而来。重点是第四部分,怎样对 search log 划分 session,有哪些 feature 可以作为划分 session 的依据。
User information collection
大多数搜索引擎会保存每一次搜索的信息,主要有下面的内容:
- query
- timestamp
- IP address of the search client
- possibly an id recorded in a cookie or obtained another way
- information about the operating system and browser
- clickthrough information
目前公开的 web search logs
- The Excite log(1997)
18,113 users, 51,473 queries - The AOL Log(2006)
$>$ 650,000 users, $>$ 20 million queries - Alta Vista(1999)
285 million users, 1 billion queries - Alta Vista(2001)
$>$ 7 million queries
Query characteristics
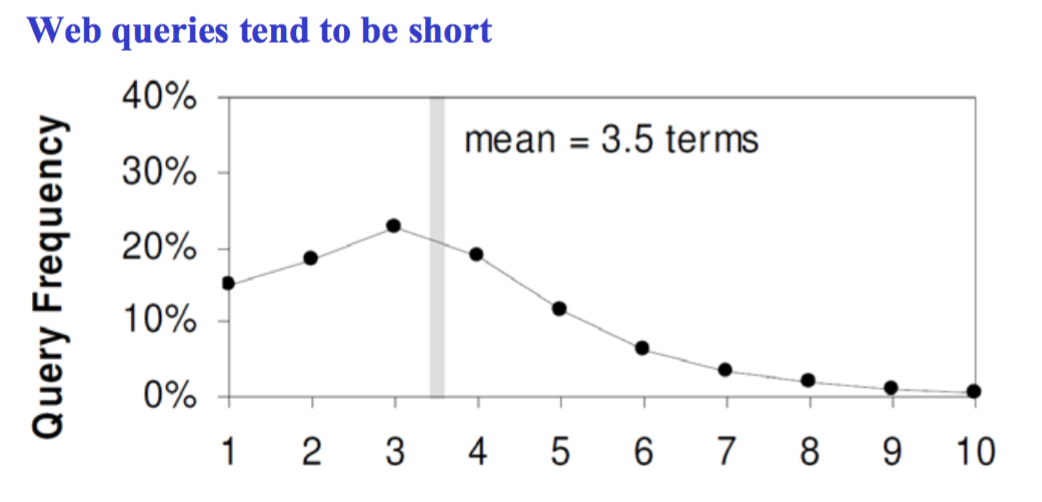
Query Length: Average terms per query: 3.5 terms
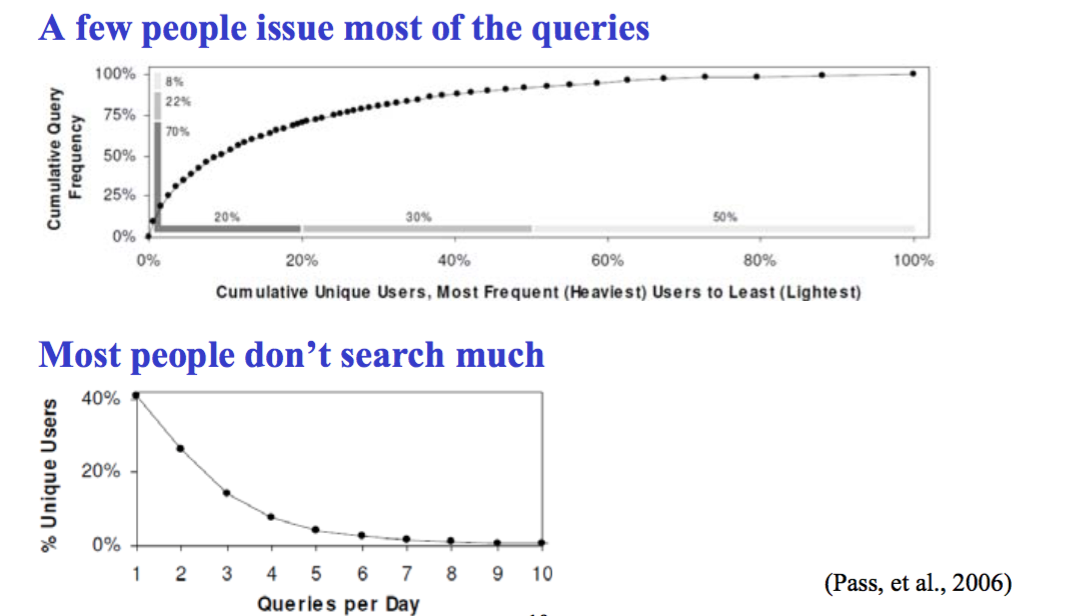
Who queries
Query Frequency: Query Frequency Follows a Power Law
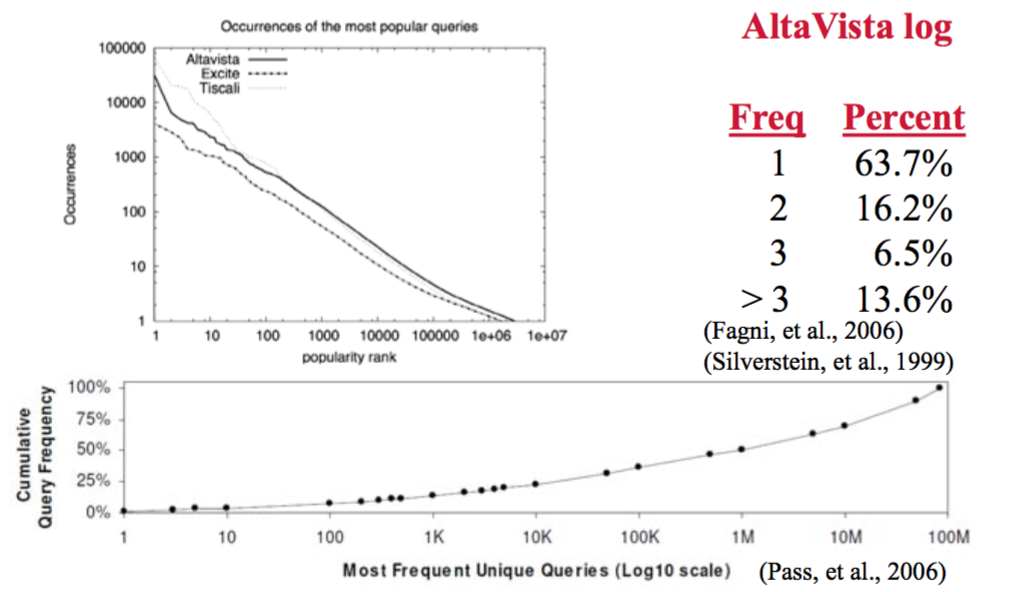
Power Law
$$Frequency(q) = K*Rank(q)^{- \alpha}$$
- K: positive constant
- Rank(q): popularity rank(r=1 is the most popular)
- $\alpha$: constant, about 2.4 for the Excite query log
和 Zipf’s law 一样的 shape,但不一样的斜率。
一小部分的 query 非常常见,而大部分的 query 非常少见。 => 通过 缓存 来提高搜索效率。
Vary over time
最常见的 query 总是在不断变化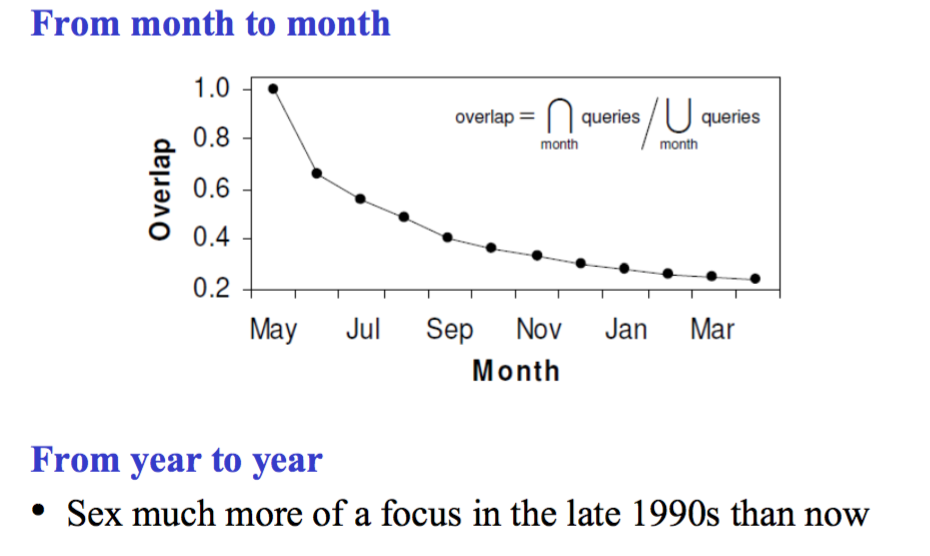
来自 google 的统计数据
- 每天的 query 中有 20% 在之前从未出现过。(占每天所有 unique query 的 50%)
- 8% 的 query 是名字(names)
Model query
- Query topics: What
比如说在雅虎目录下的分类。 - User demographics: Who
如用户的年龄、性别(用户提供)、收入、教育程度(从邮编等信息推断)等。 - Session characteristics: How
eg. session length, number of queries/session, % of queries with low/high click entropy
Represent users
需要用到的工具: Pseudo documents, clustering, control vocabulary
How to represent users?
- 在 “what” 维度上对用户进行聚类
- 在 (“who”,”how”) 维度上进一步 investigate groups
- 根据 group 的显著特征对其打上标签
根据用户的 query type 来对用户进行聚类:
- 从日志中得到 (user,query) pairs
- 为用户创建 pseudo documents
标题: user id
内容: 每条 query 的前 10 篇文档对应的 Yahoo! 分类目录 - 计算相似度
e.g. JS divergence, cosine

Types of users
这一部分主要是介绍不同类型的用户特征,这些聚类结果有什么用?=> 为下一步的个性化搜索引擎做准备。
Informational Users
How:
• More likely to issue non-navigational queries
• Less likely to have single-click sessions
• More likely to use query suggestions
What:
• Wide range of topics
• Little interest in adult content
Who:
• More likely to be well-educated
• More likely to have above-average income
Navigational Users
How:
• More likely to issue navigational queries
• More likely to have single-click sessions
• Less likely to use query suggestions
What:
• Dominated by popular websites (Facebook, YouTube, Craigslist) Who
• Mostly representative of the entire population
Transactional Users
How:
• Somewhat similar to navigational users. But, multiple sites can perform the transaction
• Diverse clicks
• Short interaction with search engine What
• Shopping, adult content, gaming
Who:
• Depends heavily on the type of transaction
• Topic “recreation/games” associated with low income & education
聚类结果 - Selected groups
Baby boomers:
• 50 years old
• Interested in finance
• Simple navigational queries related to online banking
Challenged youth:
• Average age of 34
• Low-income neighborhoods with low-level of education
• Interested in music
• Navigational sessions
Liberal females:
• Mostly female from areas that voted Democratic
• Shopping queries
• Long sessions (browsing and comparison)
White conservatives:
• Mostly male from areas that voted Republican
• Interested in automotive, business, home & garden
Older users: Health / diseases & conditions, gambling, travel
People in their late 20s: Health / fitness, reproductive health
Younger people: Games, education
Low income: Music, comics & animation, military
Asian descent: Computers & internet, programming & development
Some topics typically receive few clicks:
• News & media, society & culture, computers & internet People are more likely to click on suggestions for some topics
• Health, science, arts
People with higher educational levels:
• Tend to have shorter sessions
• Click on query suggestions less often
• Are more likely to submit tail queries
Segmenting search logs into sessions
通常,我们会把 search log 划分为一个个基于 information need 的 dialogue
dialogue 形式,实际就是用户发出初始查询,搜索引擎给出结果,用户不满意,重新修改查询语句再次搜索,然后得到新的结果,不断循环的过程。
那么问题来了,怎么来区分这些不同的 dialogues 呢?
我们定义 information need = a search session(dialogue),最简单粗暴划分 session 的方法就是通过时间,比如说三十分钟内一系列的用户行为就算作一个 session。
划分 session 可以考虑的因素:
- Time: Same session iff |timestamp (q2) – timestamp| (q1) < ∆
often ∆ = 30 minutes - Common term: Same session iff q1 ∩ q2 ≠ Ø
Probably high Precision, low Recall - Rewrite classes: Common reformulation patterns
E.g., term added, deleted, or replaced
Probably high Precision, low Recall - Edit distance
- Co-occurrence
e.g., PMI, Chi-square of queries in a query log - Same clicks
queries have co-occurring clicks in a query log - Document categories
ODP or Yahoo page category overlap of top 10 results - Same/overlap retrieved documents
JSD similarity of top 10 results
cosine distance among results - Classifiers
…
训练一个分类器是最好的方法,对任意一对 queries 大概有 95-97% 的准确率。然而 heuristics 也不差,尤其是 edit distance 和 cosine distance among results 都非常有效,时间尺度通常会和其他 heuristic 合用,效果更佳。
各种 heuristic 都可以作为分类器的 Features
- Temporal
– ≤ {5, 30, 60, 120} minutes, ∆ time, are_sequential - Edit distance
– Several character and token-based metrics - Query log
– Various types of (q1, q2) co-occurrence in a larger query log - Web search
– Cosine distance of top 50 search results for each query
(“prisma”)
我们训练分类器一般需要完成两个任务
- Boundary task: Given a pair of sequential queries
- Same task: Given a pair of queries
Challenges
用户的信息需求可能是跨越了几天甚至是几周的,比如用户写论文、找学校信息等,可能出现的情况是:
- 用户有交叉的任务
如查 paper 的时候顺便查下中午吃什么 - 用户把一个任务分成若干个子任务分阶段完成
比如今天查为什么,明天查怎么做 - 子任务可能看起来是独立的实际确实相关的

