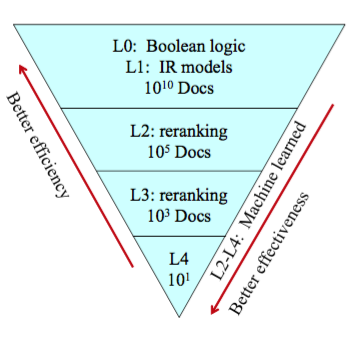
CMU 11642 的课程笔记。我们已经学习了很多检索方法,如果把这些方法结合起来,效果会不会更好呢?
传统的排序模型
相关度排序模型(Relevance Ranking Model)
相关度排序模型根据查询和文档之间的相似度来对文档进行排序。常用的模型包括:布尔模型(Boolean Model),向量空间模型(Vector Space Model),隐语义分析(Latent Semantic Analysis),BM25,LMIR 模型等等。
重要性排序模型(Importance Ranking Model)
重要性排序模型考虑的是 query-independent 的因素,根据网页(亦即文档)之间的图结构来判断文档的权威程度(Authority Score),典型的权威网站包括 Google,Yahoo! 等。常用的模型包括 PageRank,HITS,HillTop,TrustRank 等等。
Learning to Rank
Why
对于传统的排序模型,单个模型往往只能考虑某一个方面(相关度或者重要性),所以只是用单个模型达不到要求。搜索引擎通常会组合多种排序模型来进行排序,但是,如何组合多个排序模型来形成一个新的排序模型,以及如何调节这些参数,都是一个很大的问题。使用机器学习的方法,我们可以把各个现有排序模型的输出作为特征,然后训练一个新的模型,并自动学得这个新的模型的参数,从而很方便的可以组合多个现有的排序模型来生成新的排序模型。
先来看看我们现在已经拥有的东西,这些都可以作为 feature
- Retrieval models: Vector space, BM25, language models, …
- Representations: Title, body, url, inlink, …
- Query templates: Sequential dependency models, …
- Query-independent evidence: PageRank, url depth, …
我们可以把 retrieval model 也当作 feature,然后用 machine learning 的算法将上面这些 evidence 综合起来。
结构
Framework
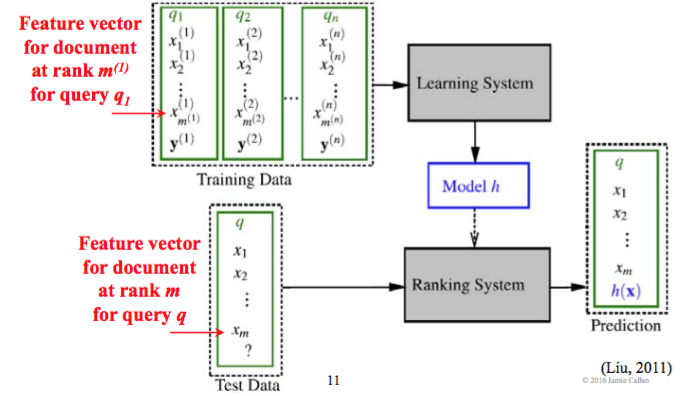
Components
从三个角度来讨论。
- Features
- Training data
- Algorithm
Features
其实之前已经讲过,retrieval models, representations, query templates, query-independent evidence 都能作为特征。
Training data
L2R 的训练数据可以有三种形式,这三种形式的训练数据之间可以相互转换,详见[1]。
- 对于每个查询,各个文档的绝对相关值(非常相关,比较相关,不相关,等等)
- 对于每个查询,两两文档之间的相对相关值(文档1比文档2相关,文档4比文档3相关,等等)
- 对于每个查询,所有文档的按相关度排序的列表(文档1>文档2>文档3)
训练数据的获取有两种主要方法:人工标注和从日志文件中挖掘。
人工标注: 首先从搜索引擎的搜索记录中随机抽取一些查询,将这些查询提交给多个不同的搜索引擎,然后选取各个搜索引擎返回结果的前 K 个,最后由专业人员来对这些文档按照和查询的相关度进行标注。
从日志中挖掘: 搜索引擎都有大量的日志记录用户的行为,我们可以从中提取出 L2R 的训练数据。Joachims 提出了一种很有意思的方法:给定一个查询,搜索引擎返回的结果列表为 L ,用户点击的文档的集合为 C,如果一个文档 di 被点击过,另外一个文档 dj 没有被点击过,并且 dj 在结果列表中排在 di 之前,则 di>dj 就是一条训练记录。亦即训练数据为:${di>dj,di \in C,dj \in L-C,p(dj)<p(di)}$,其中 p(d) 表示文档 d 在查询结果列表中的位置,越小表示越靠前。
Machine Learning Algorithm
L2R算法主要包括三种类别:PointWise,PairWise,ListWise。
Pointwise
- 训练数据是一个文档类别或分数
- Accurate score ≠ accurate ranking
- 忽略文档的位置信息
Pairwise
- 训练数据是文档对的一个偏好(一对文档选哪个)
- Accurate preference ≠ accurate ranking
- 忽略文档的位置信息
Listwise
- 训练数据是文档的排名
- 难以直接优化 ranking metrics
PointWise L2R
只考虑给定查询下,单个文档的绝对相关度,而不考虑其他文档和给定查询的相关度。亦即给定查询 q 的一个真实文档序列,我们只需要考虑单个文档 di 和该查询的相关程度 ci。
Approach: 用 individual documents 训练模型
Training data: x -> score
Learned model: h(x) -> score
Regression (e.g., linear regression)
– Scores are { -1, +1 } or { 4, 3, 2, 1, 0 }
Classification (e.g., SVM)
– Categories are { -1, +1 } or { 4, 3, 2, 1, 0 }

局限:
- 要求 score 必须在一定范围内 E.g., { -1, +1 } or { 4, 3, 2, 1, 0 } 然而经过排序算法出来的分数往往不是这样的,它可能是 { 189, 57, 42, 16, 1}.
- 重要的是 order,而不是 score。
- 没有考虑到排序的一些特征,比如文档之间的排序结果针对的是给定查询下的文档集合,而 Pointwise 方法仅仅考虑单个文档的绝对相关度
- 在排序中,排在最前的几个文档对排序效果的影响非常重要,Pointwise 没有考虑这方面的影响
Pointwise方法主要包括以下算法:Pranking (NIPS 2002), OAP-BPM (EMCL 2003), Ranking with Large Margin Principles (NIPS 2002), Constraint Ordinal Regression (ICML 2005)。
Pairwise L2R
Pairwise 方法考虑给定查询下,两个文档之间的相对相关度。亦即给定查询 q 的一个真实文档序列,我们只需要考虑任意两个相关度不同的文档之间的相对相关度:di>dj,或者 di<dj。
Approach: 用文档对来训练模型
Training data: prefer (x1, x2)
Learned model: h (x1) > h (x2)
Pair value
Binary assessments { >, < }
Loss function
如果文档对顺序正确,为 0,否则为 1
Minimize the number of misclassified document pairs
关注偏好,而不是 raw scores/labels
E.g.,
Ranking SVM
Properties of Ranking SVM
- 泛化能力强
- Kernels 可以用来提高准确率
– linear kernels 往往效果不错 - 继承了 SVM 的优势
– 有许多开源工具
– 有很多关于优化的研究
– 训练速度快
– 有理论保证
Pairwise方法主要包括以下几种算法:
Learning to Retrieve Information (SCC 1995),
Learning to Order Things (NIPS 1998),
Ranking SVM (ICANN 1999),
RankBoost (JMLR 2003), LDM (SIGIR 2005),
RankNet (ICML 2005), Frank (SIGIR 2007),
MHR(SIGIR 2007),
Round Robin Ranking (ECML 2003),
GBRank (SIGIR 2007),
QBRank (NIPS 2007),
MPRank (ICML 2007),
IRSVM (SIGIR 2006) 。
Pairs
在相关文档和不相关文档间能有很好的平衡的 queries 在训练数据中占主导地位
|
|
相比于 Pointwise 方法,Pairwise 方法通过考虑两两文档之间的相对相关度来进行排序,有一定的进步。然而,因为一个 label 会产生很多的 training instances,所以 pairwise approach 容易受到 noisy labels 的影响。另外,Pairwise 使用的这种基于两两文档之间相对相关度的损失函数,和真正衡量排序效果的一些指标之间,可能存在很大的不同,有时甚至是负相关。
另外,有的Pairwise方法没有考虑到排序结果前几名对整个排序的重要性,也没有考虑不同查询对应的文档集合的大小对查询结果的影响(但是有的Pairwise方法对这些进行了改进,比如 IR SVM 就是对 Ranking SVM 针对以上缺点进行改进得到的算法)。
Listwise L2R
与 Pointwise 和 Pairwise 方法不同,Listwise 方法直接考虑给定查询下的文档集合的整体序列,直接优化模型输出的文档序列,使得其尽可能接近真实文档序列。
Approach: 用文档序列来训练模型
Training data: x1 > x2 > … > xn
Learned model: h (x1) > h (x2) > …
Loss function
Some metric over the ranking
E.g., NDCG@n, with n=1, 3, 5, 10, … – E.g., MAP@n
Goal: Maximize the value of the metric
Directly align the model with the ranking target
E.g.,
直接优化 metrics 很难,因为一些常用的 metrics (e.g., NDCG@n) 不连续或者不是凸函数。
Two common strategies in listwise approaches:
- 找另一个直观且易于优化的指标
– E.g. likelihood of ‘best’ rankings in training data - 用 approximation 直接优化 evaluation metrics, with
Listwise 算法主要包括以下几种算法:LambdaRank (NIPS 2006), AdaRank (SIGIR 2007), SVM-MAP (SIGIR 2007), SoftRank (LR4IR 2007), GPRank (LR4IR 2007), CCA (SIGIR 2007), RankCosine (IP&M 2007), ListNet (ICML 2007), ListMLE (ICML 2008) 。
相比于 Pointwise 和 Pairwise 方法,Listwise 方法直接优化给定查询下,整个文档集合的序列,所以比较好的克服了以上算法的缺陷。Listwise 方法中的 LambdaMART(是对 RankNet 和 LambdaRank 的改进)在 Yahoo Learning to Rank Challenge 表现出最好的性能。
ListMLE(Listwise Maximum Likelihood Estimation)


直接优化 metric of interest,然而很难做到,因为一些指标不连续或者不可微,如基于位置的 metrics
Simpler possibilities:
- 优化 metric 的 approximation
- 约束目标函数
- 直接优化目标函数(不能保证结果)
Summary
Pointwise 是三种方法里最弱的
Pairwise 和 listwise 几乎同样有效
- Pairwise 有一个不完美的学习目标,但是容易实现
– 最小化 pairwise errors, 但我们想要的是最好的 ranking
- 有理论保证的一个简单化的学习模型 - Listwise 有一个完美的学习目标,但是更难实现
– 学习目标与我们想要的完全相同
- 然而很难学习
Relative effectiveness:
Listwise ≈ Pairwise > Pointwise
许多 ML 算法使用 pointwise & pairwise LeToR,因为易于开发,也比较有效。Listwise 算法可能最终更有效,然而成熟的解决方案比较少,现在仍然是一个开放的研究主题。
效果评价
L2R 是用机器学习的方法来进行排序,所以评价 L2R 效果的指标就是评价排序的指标,主要包括一下几种:
- WTA(Winners take all) 对于给定的查询 q,如果模型返回的结果列表中,第一个文档是相关的,则 WTA(q)=1,否则为0.
- MRR(Mean Reciprocal Rank) 对于给定查询 q,如果第一个相关的文档的位置是 R(q),则 MRR(q)=1/R(q)。
- MAP(Mean Average Precision) 对于每个真实相关的文档 d,考虑其在模型排序结果中的位置 P(d),统计该位置之前的文档集合的分类准确率,取所有这些准确率的平均值。
- NDCG(Normalized Discounted Cumulative Gain) 是一种综合考虑模型排序结果和真实序列之间的关系的一种指标,也是最常用的衡量排序结果的指标,详见 Wikipedia。
- RC(Rank Correlation) 使用相关度来衡量排序结果和真实序列之间的相似度,常用的指标是 Kendall’s Tau。
参考链接
Learning to rank
A Short Introduction to Learning to Rank
Learning to Rank 简介

