聊天机器人
这一部分内容来自微信公众号机器之心《深度|Google Brain研究员详解聊天机器人:面临的深度学习技术问题以及基于TensorFlow的开发实践》,商业模式部分来自公众号大数据文摘《聊天机器人如何盈利?这里有七种可能的商业模式》
模型分类
基于检索式模型 vs 生成式模型
基于检索式模型(更简单)使用了预定义回复库和某种启发式方法来根据输入和语境做出合适的回复。这种启发式方法可以像基于规则的表达式匹配一样简单,也可以像机器学习分类器集一样复杂。这些系统不会产生任何新文本,他们只是从固定的集合中挑选一种回复而已。
生成式模型(更困难)不依赖于预定义回复库。他们从零开始生成新回复。生成式模型通常基于机器翻译技术,但区别于语言翻译,我们把一个输入「翻译」成一个输出「回复」。
两种方式都有明显的优势和劣势。由于采用人工制作的回复库,基于检索式方法不会犯语法错误。然而它们可能无法处理没见过的情况,因为它们没有合适的预定义回复。同样,这些模型不能重新提到上下文中的实体信息,如先前对话中提到过的名字。生成式模型更「聪明」。它们可以重新提及输入中的实体并带给你一种正和人类对话的感觉。然而,这些模型很难训练,很可能会犯语法错误(特别是长句),而且通常要求大量的训练数据。
基于检索式模型或生成式模型都可以应用深度学习技术,但是相关研究似乎正转向生成式方向。像序列到序列(Sequence to Sequence)这样的深度学习架构是唯一可以适用于产生文本的,并且研究者希望在这个领域取得快速进步。然而,我们仍处于构建工作良好的生成式模型的早期阶段。现在的生产系统更可能是基于检索式的。
长对话 vs 短对话
对话越长,就越难使它自动化。一方面,短文本对话(更简单)的目标是单独回复一个简单的输入。例如,你可能收到一个用户的特定问题并回复合适的答案。而长对话(更困难)要求你经历多个转折并需要记录说过什么话。客户支持类对话通常是包含多个问题的长对话流。
开域(open domain) vs 闭域(closeddomain)
在开域(更困难)环境中,用户可以进行任何对话。不需要明确定义的目标或意图。像Twitter 和 Reddit 这种社交媒体网站上的对话通常是开域的——它们可以是任何主题。话题的无限数量和用于产生合理回复的一定量的知识使开域成为了一个艰难的问题。
在闭域(更简单)设定中,因为系统试图达成一个非常明确的目标,可能输入和输出的空间会有所限制。例如客户技术支持或购物助手就属于闭域的范畴。这些系统不需要能谈论政治,它们只需要尽可能高效地完成它们特定的任务。当然,用户仍然可以进行任何他们想要的对话,但是这样的系统不需要能处理所有情况,并且用户也不期望它能处理。
普遍难题
在构建大部分属于活跃研究领域的会话代理方面存在着许多明显和不明显的难题。
整合语境
为了生成明智的回复,系统可能需要整合语言语境(linguistic context)和物理语境(physical context)。在长对话中,人们记录已经被说过的话和已经交换过的信息。这是结合语言语境的例子。最普遍的方法是将对话嵌入一个向量中,但在长对话上进行这样的操作是很有挑战性的。「使用生成式分层神经网络模型构建端到端对话系统」和「神经网络对话模型的注意与意图」两个实验中都选择了这个研究方向。此外还可能需要整合其它类型的语境数据,例如日期/时间、位置或用户信息。一致人格
当生成回复时,对于语义相同的输入,代理应该生成相同的回答。例如,你想在「你多大了?」和「你的年龄是多少?」上得到同样的回答。这听起来很简单,但是将固定的知识或者「人格」整合进模型是非常困难的研究难题。许多系统学习如何生成语义合理的回复,但是它们没有被训练如何生成语义上一致的回复。这一般是因为它们是基于多个不同用户的数据训练的。「基于个人的神经对话模型」这样的模型是明确的对人格建模的方向上的第一步。模型评估
评估一个对话代理的理想方式是衡量它是否完成了它的任务,例如,在给定对话中解决客户支持问题。但是获取这样的标签成本高昂,因为它们要求人类的判断和评估。某些时候并不存在明确定义的目标,比如开域模型中的情况。通常像 BLEU 这样被用于机器翻译且是基于文本匹配的标准并不能胜任,因为智能的回复可以包括完全不同的单词或短语。实际上,在 How NOT To Evaluate Your Dialogue System: An Empirical Study of UnsupervisedEvaluation Metrics for Dialogue Response Generation 中,研究者发现没有一个通用的度量能真正与人类判断一一对应。意图和多样性
生成式系统的普遍问题是它们往往能生成像「太好了!」或「我不知道」这样的能适用于许多输入情况的普遍回复。谷歌的智能回复(Smart Reply )早期版本常常用「我爱你」回复一切。一定程度上这是系统根据数据和实际训练目标/算法训练的结果。然而,人类通常使用针对输入的回复并带有意图。因为生成系统(特别是开域系统)是不被训练成有特定意图的,所以它们缺乏这种多样性。
实际工作情况
纵观现在所有最前沿的研究,我们发展到哪里了?这些系统的实际工作情况如何?让我们再看看我们的分类法。一个基于检索式开域系统显然是不可能实现的,因为你不能人工制作出足够的回复来覆盖所有情况。生成式开域系统几乎是人工通用智能(AGI: Artificial General Intelligence),因为它需要处理所有可能的场景。我们离 AGI 还非常遥远(但是这个领域有许多研究正在进行)。
这就让我们的问题进入了生成式和基于检索式方法都适用的受限的领域。对话越长,语境就越重要,问题就变得越困难。
现任百度首席科学家吴恩达说得很好:
当今深度学习的价值在你可以获得许多数据的狭窄领域内。有一件事它做不到:进行有意义的对话。存在一些演示,并且如果你仔细挑选这些对话,看起来就像它正在进行有意义的对话,但是如果你亲自尝试,它就会快速偏离轨道。
许多公司从外包他们的对话业务给人类工作者开始,并承诺一旦他们收集到了足够的数据,他们就会使其「自动化」。只有当他们在一个相当狭窄的领域中这样操作时,这才有可能发生——比如呼叫 Uber 的聊天界面。任何稍微多点开域的事(像销售邮件)就超出了我们现在的能力范围。然而,我们也可以利用这些系统建议和改正回复来辅助人类工作者。这就更符合实际了。
生产系统的语法错误成本很高并会赶走用户。所以,大多数系统可能最好还是使用不会有语法错误和不礼貌回答的基于检索式方法。如果公司能想办法得到大量的数据,那么生成式模型就将是可行的——但是,必须需要其它技术的辅助来防止它们像微软的 Tay 一样脱轨。
商业模式
商业模式一:BaaS(Bots as a Services,聊天机器人即服务)
B2B 领域的聊天机器人主要是帮助用户和团队更有效率地开展工作、管理任务或解决团队沟通方面出现的问题。所以 B2B 领域的聊天机器人可能会复制目前已经存在的 B2B 软件领域的商业模式。
对于 B2B 聊天机器人而言,我个人坚信,SaaS 式的免费增值模式可能会成为它最可行的商业模式。对于一些聊天机器人来说,根据你购买的增值服务的不同,那么你能使用到的聊天机器人的功能也是不同的。根据市场调研公司 Forrester 发布的数据,在 2016年,SaaS 和基于云的商业应用服务的营收有望达到 328 亿美元。因此可以想象,B2B 聊天机器人市场的营收应该也不会低。Slack 平台上的大部分应用基本都是基础功能免费,要想使用更高级的功能则需要付费。
SaaS 产品的商业模式是 B2B 领域的客户都非常熟悉的。在此基础上,聊天机器人未来可能会采取更为复杂的定价模式。
商业模式二:聊天机器人 + 赞助内容和原生内容
因为 BuzzFeed、VICE 等的出现,原生内容和原生广告在过去几年里慢慢变成了一个大趋势。原生内容或赞助内容是这样一种模式:媒体公司(如 BuzzFeed)将那些付费品牌商家的赞助内容直接发布到自己的内容频道上,让读者阅读的时候感觉这篇内容好像是媒体自己创作发布的内容而非品牌商发布的广告。下面这个例子就是杜蕾斯在 BuzzFeed 上发布的原生广告内容:
现在设想一下你正在咨询一个烹饪方面的聊天机器人,聊天机器人基于自己的原生功能可能会回答你说,在某些菜谱中,使用香菜代替茴香是可以的,然后会发给你一篇文章《这五道用 ‘是拉差辣椒酱’(一种泰式料理常用的香甜辣椒酱)烹饪的菜,吃后绝对让你惊叹不已》。当然了,这里的是拉差辣椒酱就是赞助内容。
这种原生广告的效果要比传统的横幅广告的效果要好很多。这种类型的广告对品牌商和出版商都有益。未来,你可能会看到这种广告形式将被出版商应用到聊天机器人里。
商业模式三:利用聊天机器人做联盟网络营销
联盟广告营销最近很多年已经成为一种非常流行的商业化策略。联盟广告营销指的是一种网站 A 为网站 B 设置推广链接,然后从为网站 B 带来的销售额中获取一定提成的一种广告系统。
Forrester 发布的数据报告显示,2016年,美国在联盟广告营销上的花费将达到 45 亿美元。联盟广告营销也可以作为聊天机器人的一种商业模式。举个例子,对于聊天机器人的开发商,你可以开发一款健身方面的聊天机器人,在如何保持健康的身体方面为用户提供专业的建议,然后给用户发送一些附有商业推广链接的健身方面的产品。
购物聊天机器人 Kip 现在已经开始采用这种商业化策略了。用户可以问 Kip “巧克力” 或 “咖啡” 等很多产品方面的问题,然后它会回复一些产品的购买链接,如下图所示: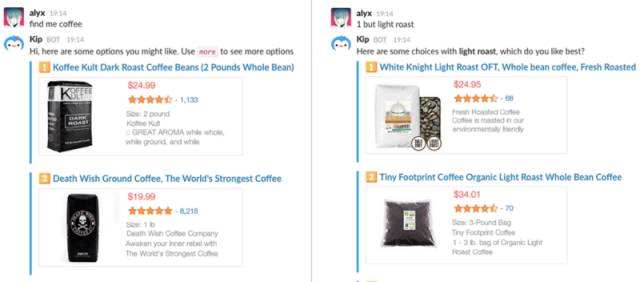
用户如果通过 Kip 发的链接购买产品,那么 Kip 团队就能从销售收入中收取一定的提成。
商业模式四:用聊天机器人做用户调研
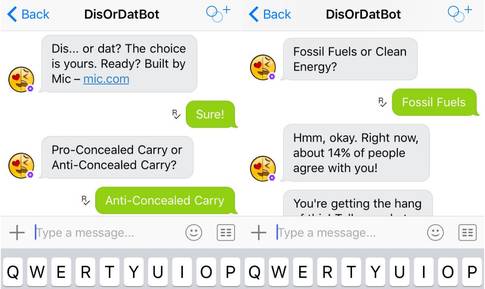
(DisOrDatBot 截图)
最近美国总统大选正在如火如荼地进行中,想了解千禧一代都是怎么看待美国总统大选的吗?你可以付费使用一些聊天机器人来进行这方面的调研。虽然我现在还没有看到有人利用聊天机器人做这方面的事,但我觉得如果有专门的 Q&A 聊天机器人来专门帮助人们做调研的话还是非常靠谱的。
目前像 DisOrDatBot 这样的聊天机器人已经开始向用户问一下调研类问题了。想象一下你作为一次活动的策划者,现在正在发愁究竟邀请哪支乐队来你所在的城市进行表演,是邀请电台司令乐队(Radiahead)还是五分钱乐队(Nickelback,加拿大的著名乐队),这时,与其花很多钱请调研公司帮你做调研,还不如使用 DisOrDatBot 进行调研,看你所在城市的用户到底喜欢哪支乐队。
如果你已经开发了一个定期给一群小众用户提供有价值内容的聊天机器人,那些想触及这些用户或是想向这群用户销售产品的公司可能会比较有兴趣通过你的聊天机器人做调研。
商业模式五:将聊天机器人用于潜在客户开发中
我预测,聊天机器人未来将会被应用到潜在客户开发中,一开始主要利用内容去开发潜在客户。通过在房产所有权、保险、婚礼和理财等方面为用户提供专业的信息、想法和见解,聊天机器人然后将自己获得的这些用户信息给到那些销售相关产品和服务的公司。
举个例子,加入你正在和一个 “生活聊天机器人” 聊天,向聊天机器人咨询一些购房方面的问题,随着聊天的深入,聊天机器人搜集了更多有关你的信息,包括你手头有多少首付资金、你想在哪里购房定居、你是否在职、你购买的是否是你的第一套房产等等。在和聊天机器人建立起一定的关系后,聊天机器人于是问你下面这个问题:
“你是否介意我介绍一家比较适合你的房产公司和你联系?”
在经过你的同意之后,聊天机器人就会将你的信息给到你所在地区的一家房地产公司。这家房产公司第二天就会和你联系沟通你的购房需求。然后这家房产公司会给聊天机器人开发商一定的佣金作为为其开发潜在客户的报酬。
商业模式六:纯粹用于零售销售的聊天机器人
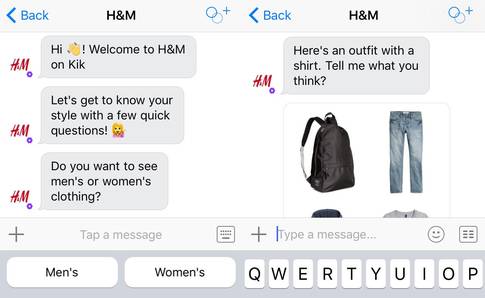
(Kit 上的 H&M 零售聊天机器人)
聊天机器人最直接的一种使用场景是商家直接向消费者(B2C)销售产品。想象一下,沃尔玛、Harry’ s、Target、Amazon 和京东等开发了这样一种聊天机器人,你可以问聊天机器人是否销售 “牙膏” 或 “刮胡刀” 等,然后聊天机器人会直接回复你这些商品的购买链接,所以用户在于聊天机器人的交流中就能直接完成商品的购买。
商业模式七:按完成的咨询次数或任务收费
人们都希望得到专业的好建议,也愿意为好建议付费。随着聊天机器人变得越来越专业和智能,我认为未来人们会在生活中的很多方面都希望得到聊天机器人的建议和帮助,并愿意为这些建议付费。例如,如果你需要生活方面的建议,你可以和 “Oprah 聊天机器人” 交流,如果你需要获得汽车方面的信息,那么你可以和 “机械聊天机器人” 交流,如果你希望获得匿名的婚姻咨询,你可以和 “婚姻聊天机器人” 交流咨询。当然了,为了得到聊天机器人的建议,你是需要支付一定的费用的。
论文推荐
Neural Responding Machine for Short-Text Conversation (2015-03)
A Neural Conversational Model (2015-06)
A Neural Network Approach to Context-Sensitive Generation of Conversational Responses (2015-06)
The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems (2015-06)
Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models (2015-07)
A Diversity-Promoting Objective Function for Neural Conversation Models (2015-10)
Attention with Intention for a Neural Network Conversation Model (2015-10)
Improved Deep Learning Baselines for Ubuntu Corpus Dialogs (2015-10)
A Survey of Available Corpora for Building Data-Driven Dialogue Systems (2015-12)
Incorporating Copying Mechanism in Sequence-to-Sequence Learning (2016-03)
A Persona-Based Neural Conversation Model (2016-03)
How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation (2016-03)
客服机器人
与聊天机器人的不同
回答问题的范围和方式不同
聊天机器人: 发散。可以回答广泛的问题,回答也是发散的。
客服机器人: 收敛。关注焦点在于聚焦的业务范围内有多大的问题处理能力。
使用门槛不同
聊天机器人: 不需要给他准备非常多的专业知识,多放一些常识库、问答库和寒暄库的知识,多放一些笑话和段子然后推出去为大家做一些即时的服务就可以了,当然也可以让他继续学习和优化。
客服机器人: 专业知识库。
特质
开放问题的收敛能力
智能客服机器人应有归纳问题的能力。能够尽量把客户的问题引导到正确的轨道上来。自学习的能力
智能客服机器人应有自学习的能力。它可以根据知识库以及工单进行批量学习,同时能够根据人工服务过程进行单次学习。人工指导学习的能力
我们可以对智能客服机器人进行相应的测试,并可以对其进行调教。归纳聚类的能力
智能客服机器人可以根据客户问的问题与现有知识进行匹配,并能够将匹配度低的问题聚类交由人工来进行回答及维护。人工回答后智能客服机器人能够同步学习,并生成新的问答类型,在下次回到中可以自行解决。
设计原则
基于业务
不靠谱问题
–> 收敛,回归。eg.提供相似问题1、2、3
–> 无法收敛?转人工靠谱问题
–> 定位,回答
总之一句话:不离本行不废话!
快速收敛
- 输入问题的时候就能快速收敛(显示提示列表让用户选择)
- 对不靠谱问题即时收敛,提供可能的相似问题
二八原则
对于很多企业的客户服务来说,80%的客户问题集中在20%的问题类型里。所以要集中攻克的是 – 不停训练智能客服机器人让它能够应对这10%的问题类型中各种刁钻的问法。
知识支撑与自学习
客服机器人至少要有的3个知识库:
- 寒暄库
- 行业知识库
- 基于用户体验的知识库
问题
多少情感含量?
客服机器人与人工服务应该是能进行无缝对接的,因此它的感性层面应该等同于人工客服,在不能回答问题的时候也要彬彬有礼,在寒暄的时候要含蓄内敛不能太过浮夸、奔放。客服机器人掌握的度应该是和人工客服一样,能让客户“如沐春风”的。
是否拒绝谩骂类客户?
然而接触了这么多用户问题,也发现有一部分人纯粹是来发牢骚甚至是骂人的,并不期待回答,对于这种情况如何处理?个人认为,“客户是上帝”,然而企业也必须尊重员工,不能任由人工客服承受无理的客服的谩骂,既然机器人和人工客服无缝对接,那么机器人也不应该“承受”这些,而应巧妙的拒绝客户,结束对话。
是否上下文关联?
尽可能在一次交互里解决问题。因为通过多次询问后客户的场景往往是混乱的,难以识别。
流程
简化的原理、流程
输入:客户问题
–> 分词、权重
–> 语义分析
–> 匹配知识
–> 要素补足
–> 精确匹配
–> 回复内容
输出: 标准问题
中间可能有的意外是匹配程度低,机器人难以给出准确回复,这时要走另一条线,来发现新的问题,完善服务。
精确匹配
–> 匹配度低
–> 传递到人工
–> 人工解答
–> 产生新的知识点
–> 转交给客服机器人
技术
一代:关键词
二代:规则+搜索
三代:语义网+自学习
目前停留在二代,三代大多还在实验室阶段。
如何精确匹配?
局部(文本相关)
维度设计: 命中核心词?其他字段?
权重设计:如何给各维度分配权重?全局
检索排序:哪个最相关?哪个最有可能相关?

